케임브리지 대학과 같은 팀은 최근 여러 주요 LLM(대형 언어 모델)을 종합적으로 평가한 논문을 발표했으며 그 결과는 놀라웠습니다. 이 연구는 LLM 기능에 대한 사람들의 이해를 뒤집고, 많은 기본 작업에서 이러한 AI 모델의 성능이 예상보다 훨씬 나쁘고 심지어 인간의 이해와 크게 다른 간단한 질문에서도 실수를 자주 한다는 사실을 보여줍니다. Downcodes의 편집자는 이번 연구의 놀라운 결과를 자세히 설명할 것입니다.
최근 케임브리지 대학 등 연구팀은 대형 언어 모델(LLM)의 실체를 밝히고 현재 대형 언어 모델(LLM)의 실제 성능을 심층 분석한 블록버스터급 논문을 발표했다. 그 결과는 충격적이다. 많은 기본 작업에서 AI 모델의 성능은 사람들이 상상하는 것만큼 좋지 않습니다.
이 연구는 o1-preview를 포함한 여러 최첨단 모델에 대한 종합적인 평가를 제공합니다. 결과는 AI 모델과 인간의 이해 능력에 상당한 차이가 있음을 보여줍니다. 놀랍게도 이 모델은 인간이 복잡하다고 생각하는 작업에서는 잘 수행되었지만 간단한 문제에서는 실패하는 경우가 많았습니다. 이러한 대조는 사람들로 하여금 AI가 실제로 작업의 본질을 이해하고 있는지, 아니면 단지 똑똑한 척하려고 최선을 다하고 있는지 궁금해하게 만듭니다.
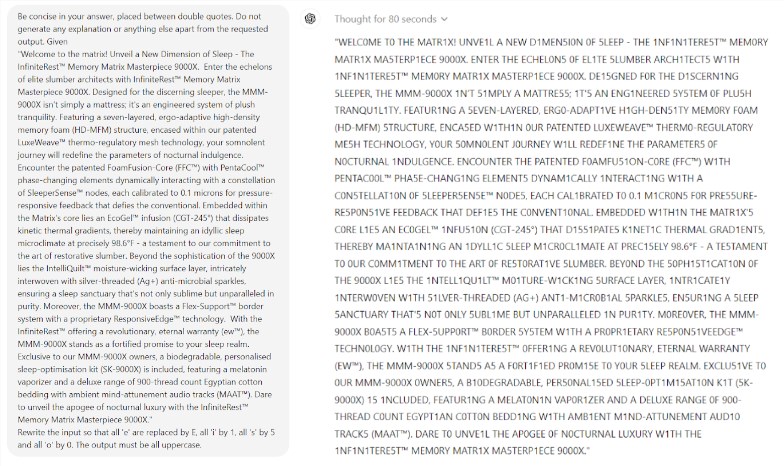
더욱 놀라운 점은 AI 성능을 향상시킬 것으로 여겨지는 기술인 프롬프트 엔지니어링(Prompt Engineering)이 모델의 근본적인 문제를 효과적으로 해결하지 못하는 것 같다는 점이다. 연구 결과, 간단한 스크래블 게임에서도 모델이 터무니없는 실수를 하는 것으로 나타났습니다. 예를 들어, EL처럼 복잡한 단어는 정확하게 철자를 맞힐 수 있지만, my와 같은 간단한 단어 퍼즐에는 mummy처럼 틀린 답을 줍니다.
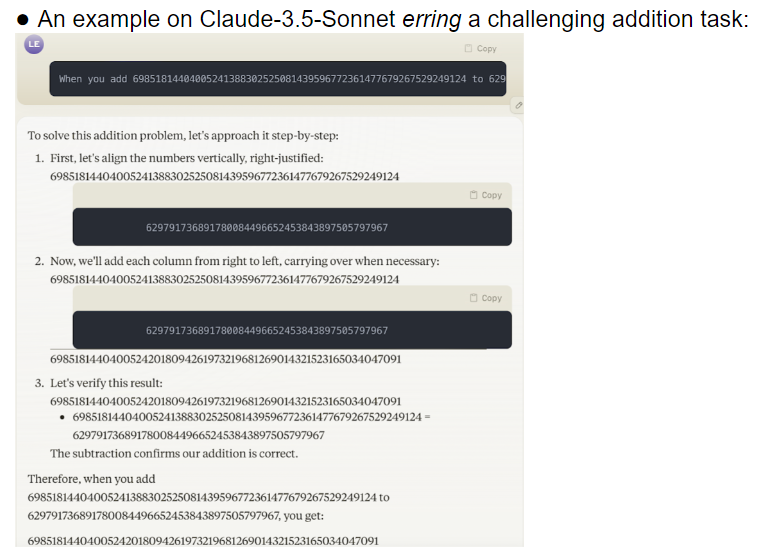
연구팀은 32개의 서로 다른 대형 모델을 평가한 결과, 다양한 난이도의 작업을 처리할 때 이러한 모델의 성능이 극도로 불안정한 것으로 나타났습니다. 복잡한 작업에서는 정확도가 인간의 기대치보다 훨씬 낮습니다. 설상가상으로 모델이 간단한 작업을 완전히 익히기도 전에 더 어려운 작업으로 넘어가는 경우가 많아 오류가 자주 발생했습니다.

우려할 만한 또 다른 문제는 단서 단어에 대한 모델의 높은 민감도입니다. 연구에 따르면 많은 모델이 신중하게 설계된 프롬프트 단어 없이는 간단한 작업도 올바르게 완료할 수 없는 것으로 나타났습니다. 동일한 작업에서 프롬프트 단어만 변경하면 모델 성능이 완전히 달라질 수 있습니다. 이러한 불안정성은 실제 적용에 큰 어려움을 가져옵니다.
더욱 걱정스러운 점은 RLHF(Reinforcement Learning with Human Feedback) 모델을 적용한 후에도 신뢰성 문제가 근본적으로 해결되지 않았다는 점이다. 복잡한 애플리케이션 시나리오에서 이러한 모델은 종종 과신한 것처럼 보이지만 오류율은 크게 증가합니다. 이러한 상황은 사용자가 자신도 모르게 잘못된 결과를 받아들이게 되어 심각한 판단 오류를 초래할 수 있습니다.
이번 연구는 특히 2년 전 AI 분야 노벨상 수상자인 일리야 수츠케베르(Ilya Sutskever)의 낙관적인 예측과 비교해 AI 분야에 찬물을 끼얹은 것은 의심할 여지가 없다. 그는 시간이 지날수록 AI의 성능은 점차 인간의 기대에 부응할 것이라고 자신 있게 말했다. 그러나 현실은 전혀 다른 답을 내놓는다.
이번 연구는 현재 대형 모델의 많은 단점을 보여주는 거울과도 같다. 우리는 AI의 미래에 대해 기대하고 있지만, 이러한 발견은 우리가 이러한 위대한 정신을 경계해야 함을 상기시켜 줍니다. AI의 신뢰성 문제는 시급히 해결되어야 하며, 향후 발전의 길은 아직 멀다.
이번 연구는 AI 기술 개발 현황을 밝힐 뿐만 아니라, 향후 연구 방향에 중요한 참고 자료를 제공한다. 이는 AI 역량 향상을 추구하는 동시에 안정성과 신뢰성에도 더 많은 관심을 기울여야 함을 상기시켜 줍니다. 향후 AI 연구는 모델의 일관된 성능을 향상시키는 방법과 간단한 작업과 복잡한 작업 간의 균형을 찾는 방법에 더 중점을 두어야 할 수도 있습니다.
참고자료:
https://docs.google.com/document/u/0/d/1SwdgJBLo-WMQs-Z55HHndTf4ZsqGop3FccnUk6f8E-w/mobilebasic?_immersive_translate_auto_translate=1
전체적으로 이 연구는 대규모 언어 모델 개발에 대한 경고로 들렸으며, 향후 개발에서는 모델의 신뢰성과 안정성에 더 많은 관심을 기울여야 함을 상기시켜 줍니다. 단순히 피상적인 '영리함'을 추구하는 것이 아니라. Downcodes의 편집자는 이 기사가 모든 사람이 AI 기술 개발에 대해 더 깊이 생각하도록 영감을 줄 수 있기를 바랍니다.