ケンブリッジ大学などのチームは最近、複数の主要な大規模言語モデル (LLM) を包括的に評価した論文を発表しましたが、その結果は驚くべきものでした。この研究は、LLM 機能に対する人々の理解を覆し、多くの基本的なタスクにおけるこれらの AI モデルのパフォーマンスが予想よりもはるかに悪く、人間の理解とは大きく異なる単純な質問でも頻繁に間違いを犯すことさえ明らかにしました。この研究の驚くべき発見について、『Downcodes』編集者が詳しく解説します。
最近、ケンブリッジ大学と他のチームは、大規模言語モデル (LLM) の本当の姿と、現在の大規模言語モデル (LLM) の実際のパフォーマンスの詳細な分析を明らかにした大ヒット論文を発表しました。その結果は衝撃的です。多くの基本的なタスクにおける AI モデルのパフォーマンスは、人々が想像しているほど優れているわけではありません。
この調査では、o1-preview を含む複数の最先端モデルの総合的な評価を提供します。その結果、AIモデルと人間とでは理解力に大きな差があることが分かりました。驚くべきことに、このモデルは人間が複雑だと考えるタスクではうまく機能しましたが、単純な問題では頻繁に失敗しました。このコントラストにより、人々は、これらの AI がタスクの性質を本当に理解しているのか、それとも単に賢いふりをしようと最善を尽くしているだけなのか疑問に感じます。
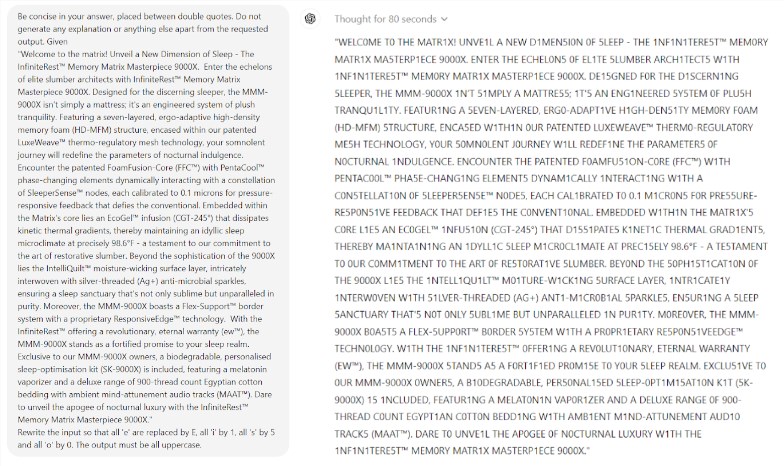
さらに驚くべきことは、AI のパフォーマンスを向上させると考えられているテクノロジであるプロンプト エンジニアリングが、モデルの根本的な問題を効果的に解決できないように見えることです。この研究では、単純なスクラブル ゲームであっても、モデルがとんでもない間違いを犯していることが判明しました。たとえば、エレクトロルミネッセンスのような複雑な単語を正しく綴ることができますが、私のような単純な単語パズルに対しては「ミイラ」のように不正確な答えを与えることができます。
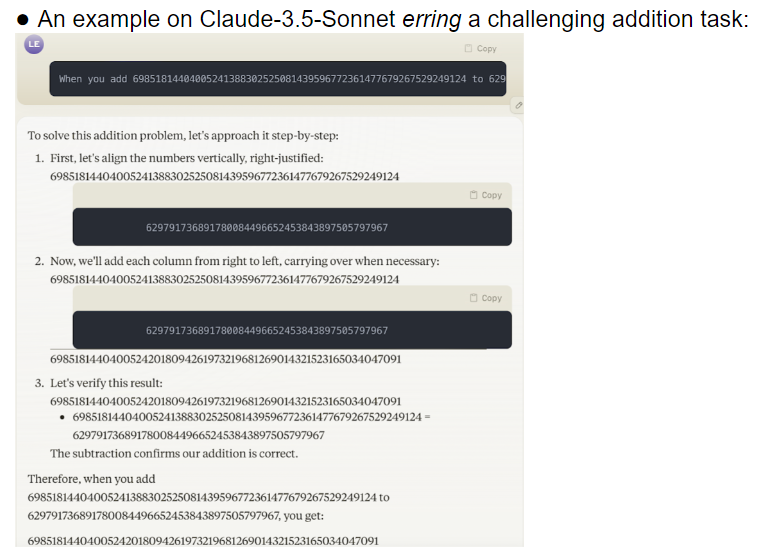
研究チームは 32 の異なる大規模モデルを評価し、その結果、さまざまな難易度のタスクを処理する場合、これらのモデルのパフォーマンスが非常に不安定であることがわかりました。複雑なタスクでは、その精度は人間の期待をはるかに下回ります。さらに悪いことに、モデルは単純なタスクを完全に習得する前に、より難しいタスクに移ったようで、頻繁にエラーが発生しました。

懸念に値するもう 1 つの問題は、手がかりとなる単語に対するモデルの感度が高いことです。研究によると、多くのモデルは、慎重に設計されたプロンプトの言葉がなければ、単純なタスクを正しく完了することさえできないことがわかっています。同じタスクにおいて、プロンプトの単語を変更するだけで、モデルのパフォーマンスがまったく異なる可能性があります。この不安定性は、実際のアプリケーションに大きな課題をもたらします。
さらに懸念されるのは、ヒューマンフィードバックによる強化学習(RLHF)モデルの後でも、その信頼性の問題が根本的に解決されていないことである。複雑なアプリケーション シナリオでは、これらのモデルは自信過剰に見えることがよくありますが、エラー率は大幅に増加します。このような状況では、ユーザーが誤った結果を知らずに受け入れてしまい、重大な判断ミスを引き起こす可能性があります。
この研究は、特に 2 年前の AI 分野のノーベル賞受賞者イリヤ・サツケヴァー氏の楽観的な予測と比較すると、AI 分野に冷や水を浴びせたことは間違いありません。彼はかつて、時間が経つにつれて、AI のパフォーマンスは徐々に人間の期待に応えられるようになる、と自信を持って語ったことがあります。しかし、現実はまったく異なる答えを与えます。
この研究は鏡のようなもので、現在の大型モデルの多くの欠点を示しています。私たちは AI の将来に興奮していますが、これらの発見は、私たちがこれらの偉大な頭脳に注意する必要があることを思い出させます。 AIの信頼性問題は早急に解決する必要があり、今後の発展への道のりはまだ遠い。
この研究は、AI技術開発の現状を明らかにするだけでなく、今後の研究の方向性についても重要な参考となる。 AI の機能の向上を追求する一方で、その安定性と信頼性にもさらに注意を払う必要があることを思い出させます。将来の AI 研究では、モデルの一貫したパフォーマンスを向上させる方法と、単純なタスクと複雑なタスクのバランスを見つける方法にさらに焦点を当てる必要があるかもしれません。
参考文献:
https://docs.google.com/document/u/0/d/1SwdgJBLo-WMQs-Z55HHndTf4ZsqGop3FccnUk6f8E-w/mobilebasic?_immersive_translate_auto_translate=1
全体として、この研究は大規模な言語モデルの開発に警鐘を鳴らしており、今後の開発ではモデルの信頼性と安定性にさらに注意を払う必要があることを思い出させてくれます。表面的な「賢さ」だけを追求するのではなく。 Downcodes の編集者は、この記事がすべての人に AI テクノロジーの開発についてより深く考えるきっかけになればと願っています。