Tim seperti Universitas Cambridge baru-baru ini menerbitkan makalah yang mengevaluasi secara komprehensif beberapa model bahasa besar (LLM) terkemuka, dan hasilnya mengejutkan. Penelitian ini menumbangkan pemahaman masyarakat tentang kemampuan LLM, mengungkapkan bahwa performa model AI ini pada banyak tugas dasar jauh lebih buruk dari yang diharapkan, dan bahkan sering membuat kesalahan pada pertanyaan sederhana, yang sangat berbeda dengan pemahaman manusia. Editor Downcodes akan menjelaskan temuan mengejutkan dari penelitian ini secara detail.
Baru-baru ini, Universitas Cambridge dan tim lainnya menerbitkan makalah blockbuster yang mengungkap wajah sebenarnya dari model bahasa besar (LLM) dan analisis mendalam tentang kinerja aktual model bahasa besar (LLM) saat ini. Hasilnya mengejutkan - ini memang benar harapan yang tinggi. Performa model AI pada banyak tugas dasar masih jauh dari sebaik yang dibayangkan orang.
Studi ini memberikan evaluasi komprehensif terhadap beberapa model mutakhir termasuk o1-preview. Hasilnya menunjukkan terdapat perbedaan kemampuan pemahaman yang signifikan antara model AI dan manusia. Yang mengejutkan, model tersebut bekerja dengan baik pada tugas-tugas yang dianggap rumit oleh manusia, namun sering kali gagal pada masalah-masalah sederhana. Perbedaan ini membuat orang bertanya-tanya apakah AI ini benar-benar memahami sifat tugasnya, atau hanya berusaha semaksimal mungkin untuk berpura-pura menjadi pintar.
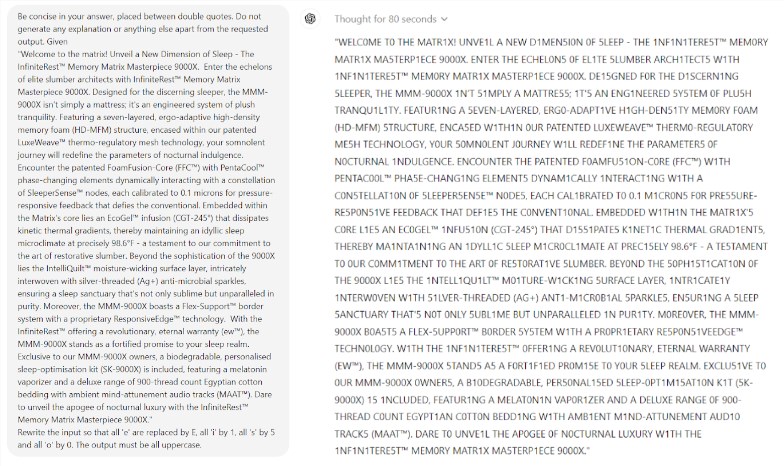
Yang lebih mengejutkan lagi adalah Prompt Engineering, sebuah teknologi yang dianggap dapat meningkatkan kinerja AI, tampaknya tidak mampu menyelesaikan masalah mendasar model tersebut secara efektif. Studi tersebut menemukan bahwa bahkan dalam permainan Scrabble yang sederhana, model tersebut membuat kesalahan yang konyol. Misalnya, Anda dapat mengeja kata kompleks seperti electroluminescence dengan benar, tetapi memberikan jawaban yang salah seperti mumi untuk teka-teki kata sederhana seperti my.
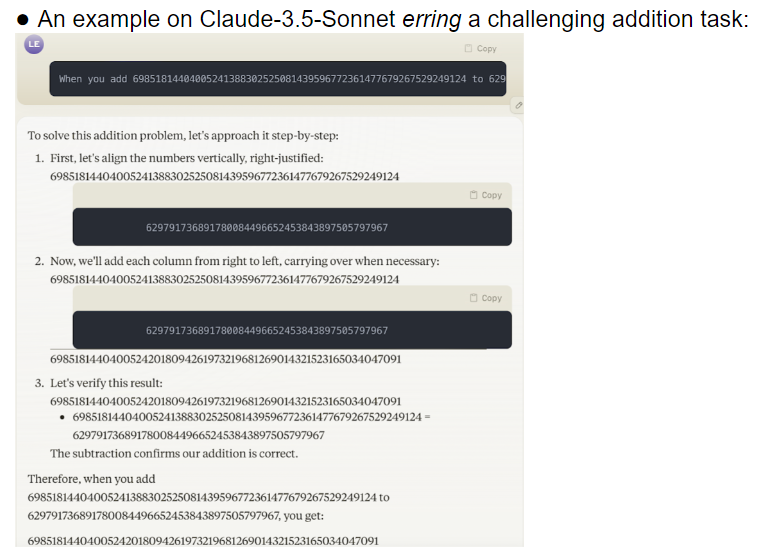
Tim peneliti mengevaluasi 32 model besar yang berbeda, dan hasilnya menunjukkan bahwa kinerja model ini sangat tidak stabil ketika menangani tugas-tugas dengan tingkat kesulitan yang berbeda-beda. Pada tugas-tugas kompleks, keakuratannya jauh di bawah ekspektasi manusia. Lebih buruk lagi, model tersebut tampaknya beralih ke tugas-tugas yang lebih sulit sebelum mereka benar-benar menguasai tugas-tugas sederhana, sehingga sering terjadi kesalahan.

Masalah lain yang perlu diperhatikan adalah sensitivitas model yang tinggi terhadap kata-kata isyarat. Penelitian telah menemukan bahwa banyak model bahkan tidak dapat menyelesaikan tugas sederhana dengan benar tanpa kata-kata cepat yang dirancang dengan cermat. Dalam tugas yang sama, hanya mengubah kata-kata cepat dapat menghasilkan performa model yang sangat berbeda. Ketidakstabilan ini membawa tantangan besar pada aplikasi praktis.
Yang lebih mengkhawatirkan lagi adalah bahkan setelah pembelajaran penguatan dengan model umpan balik manusia (RLHF), masalah reliabilitasnya belum teratasi secara mendasar. Dalam skenario aplikasi yang kompleks, model ini sering kali tampak terlalu percaya diri, namun tingkat kesalahannya meningkat secara signifikan. Situasi ini dapat menyebabkan pengguna menerima hasil yang salah tanpa menyadarinya, sehingga mengakibatkan kesalahan penilaian yang serius.
Penelitian ini tidak diragukan lagi memberikan air dingin bagi bidang AI, terutama dibandingkan dengan prediksi optimis Ilya Sutskever, pemenang Hadiah Nobel di bidang AI dua tahun lalu. Ia pernah mengatakan dengan yakin bahwa seiring berjalannya waktu, kinerja AI secara bertahap akan memenuhi ekspektasi manusia. Namun, kenyataan memberikan jawaban yang sangat berbeda.
Penelitian ini ibarat cermin, menunjukkan banyaknya kekurangan model besar saat ini. Meskipun kami sangat antusias dengan masa depan AI, temuan ini mengingatkan kita bahwa kita perlu mewaspadai para pemikir hebat ini. Masalah keandalan AI perlu segera diatasi, dan jalan menuju pengembangan di masa depan masih panjang.
Penelitian ini tidak hanya mengungkap status perkembangan teknologi AI saat ini, namun juga memberikan referensi penting untuk arah penelitian di masa depan. Hal ini mengingatkan kita bahwa sembari mengupayakan peningkatan kemampuan AI, kita juga harus lebih memperhatikan stabilitas dan keandalannya. Penelitian AI di masa depan mungkin perlu lebih fokus pada cara meningkatkan performa model yang konsisten dan cara menemukan keseimbangan antara tugas sederhana dan tugas kompleks.
Referensi:
https://docs.google.com/document/u/0/d/1SwdgJBLo-WMQs-Z55HHndTf4ZsqGop3FccnUk6f8E-w/mobilebasic?_immersive_translate_auto_translate=1
Secara keseluruhan, penelitian ini memberikan peringatan bagi pengembangan model bahasa besar, mengingatkan kita bahwa kita perlu berhati-hati terhadap potensi dan keterbatasan AI di masa depan. Pengembangan di masa depan perlu lebih memperhatikan keandalan dan stabilitas model. daripada sekedar menekuni yang dangkal “pintar”. Redaksi Downcodes berharap artikel ini dapat menginspirasi semua orang untuk memikirkan lebih dalam mengenai perkembangan teknologi AI.