Equipes como a Universidade de Cambridge publicaram recentemente um artigo que avaliou de forma abrangente vários modelos líderes de grandes linguagens (LLM), e os resultados foram surpreendentes. Esta pesquisa subverte a compreensão das pessoas sobre as capacidades do LLM, revelando que o desempenho desses modelos de IA em muitas tarefas básicas é muito pior do que o esperado, e até mesmo comete erros frequentes em questões simples, o que é significativamente diferente da compreensão humana. O editor do Downcodes explicará detalhadamente as descobertas surpreendentes deste estudo.
Recentemente, a Universidade de Cambridge e outras equipes publicaram um artigo de grande sucesso, revelando a verdadeira face dos grandes modelos de linguagem (LLM) e uma análise aprofundada do desempenho real dos atuais modelos de grande linguagem (LLM). grandes esperanças. O desempenho dos modelos de IA em muitas tarefas básicas está longe de ser tão bom quanto as pessoas imaginam.
Este estudo fornece uma avaliação abrangente de vários modelos de ponta, incluindo visualização o1. Os resultados mostram que há uma diferença significativa na capacidade de compreensão entre os modelos de IA e os humanos. Surpreendentemente, o modelo teve um bom desempenho em tarefas que os humanos consideram complexas, mas falhou frequentemente em problemas simples. Esse contraste faz com que as pessoas se perguntem se essas IAs realmente entendem a natureza da tarefa ou se estão apenas dando o melhor de si para fingir que são inteligentes.
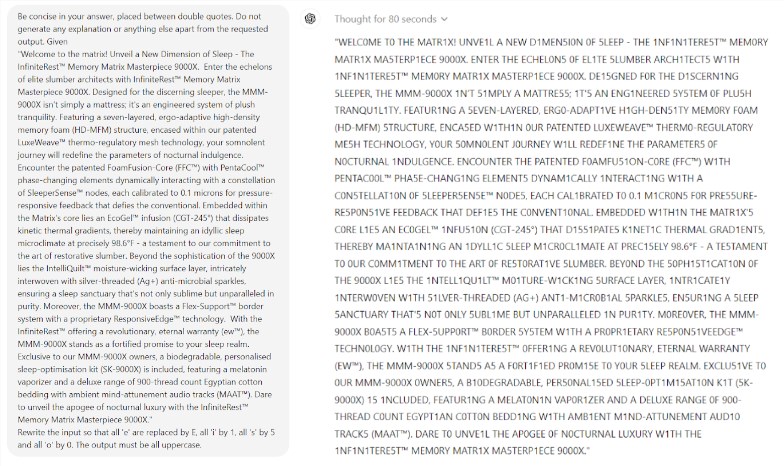
O que é ainda mais surpreendente é que a Prompt Engineering, uma tecnologia que se pensa melhorar o desempenho da IA, não parece ser capaz de resolver eficazmente os problemas fundamentais do modelo. O estudo descobriu que mesmo em um jogo simples de Scrabble, o modelo cometeu erros ridículos. Por exemplo, você pode soletrar corretamente uma palavra complexa como eletroluminescência, mas dar uma resposta incorreta como múmia para um quebra-cabeça de palavras simples como o meu.
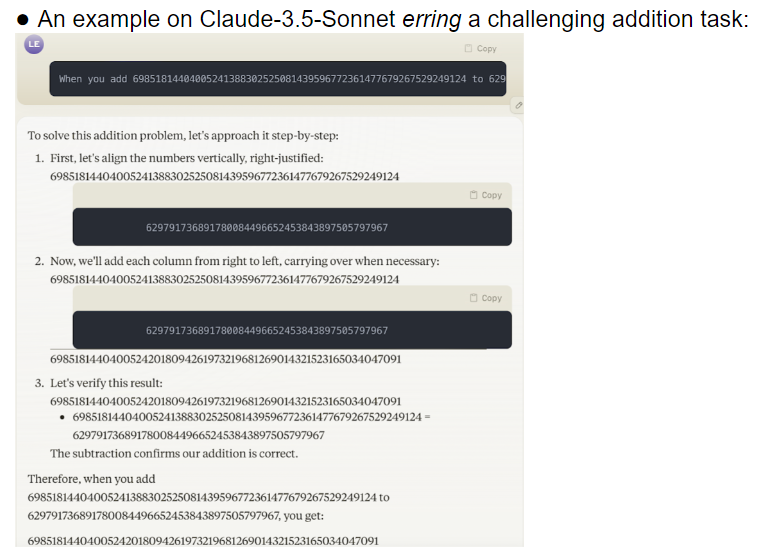
A equipe de pesquisa avaliou 32 modelos grandes diferentes, e os resultados mostraram que o desempenho desses modelos era extremamente instável ao lidar com tarefas de diferentes dificuldades. Em tarefas complexas, a sua precisão está muito abaixo das expectativas humanas. Para piorar a situação, os modelos pareciam passar para tarefas mais difíceis antes de terem dominado completamente as tarefas simples, levando a erros frequentes.

Outra questão digna de preocupação é a alta sensibilidade do modelo às palavras-chave. A pesquisa descobriu que muitos modelos não conseguem nem mesmo completar tarefas simples corretamente sem palavras de alerta cuidadosamente projetadas. Na mesma tarefa, apenas alterar as palavras do prompt pode levar a um desempenho do modelo completamente diferente. Essa instabilidade traz enormes desafios para as aplicações práticas.
O que é ainda mais preocupante é que mesmo após o modelo de aprendizagem por reforço com feedback humano (RLHF), seu problema de confiabilidade não foi fundamentalmente resolvido. Em cenários de aplicação complexos, esses modelos muitas vezes parecem excessivamente confiantes, mas suas taxas de erro aumentam significativamente. Esta situação pode fazer com que os usuários aceitem resultados incorretos sem saber, resultando em graves erros de julgamento.
Esta pesquisa, sem dúvida, despejou água fria no campo da IA, especialmente em comparação com as previsões otimistas de Ilya Sutskever, ganhador do Prêmio Nobel na área de IA há dois anos. Certa vez, ele disse com confiança que, com o passar do tempo, o desempenho da IA atenderá gradualmente às expectativas humanas. No entanto, a realidade dá uma resposta completamente diferente.
Esta pesquisa é como um espelho, mostrando as muitas deficiências dos grandes modelos atuais. Embora estejamos entusiasmados com o futuro da IA, estas descobertas lembram-nos que precisamos de ter cuidado com estas grandes mentes. O problema da fiabilidade da IA precisa de ser resolvido urgentemente e o caminho para o desenvolvimento futuro ainda é longo.
Esta pesquisa não apenas revela o estado atual do desenvolvimento da tecnologia de IA, mas também fornece uma referência importante para futuras direções de pesquisa. Lembra-nos que, ao mesmo tempo que procuramos melhorar as capacidades da IA, devemos também prestar mais atenção à sua estabilidade e fiabilidade. A futura investigação em IA poderá ter de se concentrar mais em como melhorar o desempenho consistente do modelo e em como encontrar um equilíbrio entre tarefas simples e tarefas complexas.
Referências:
https://docs.google.com/document/u/0/d/1SwdgJBLo-WMQs-Z55HHndTf4ZsqGop3FccnUk6f8E-w/mobilebasic?_immersive_translate_auto_translate=1
Em suma, esta investigação lançou um alerta para o desenvolvimento de grandes modelos de linguagem, lembrando-nos que precisamos de ser cautelosos sobre o potencial e as limitações da IA. O desenvolvimento futuro precisa de prestar mais atenção à fiabilidade e estabilidade do modelo. em vez de apenas perseguir o superficial "inteligente". O editor do Downcodes espera que este artigo possa inspirar todos a pensar mais profundamente sobre o desenvolvimento da tecnologia de IA.