บรรณาธิการของ Downcodes ได้เรียนรู้ว่าสถาบันวิจัย Zhiyuan เพิ่งเปิดตัว Infinity-Instruct ซึ่งเป็นชุดข้อมูลที่ปรับแต่งอย่างละเอียดซึ่งประกอบด้วยคำสั่งหลายสิบล้านคำสั่ง โดยมีเป้าหมายเพื่อปรับปรุงประสิทธิภาพของโมเดลภาษาอย่างมีนัยสำคัญ โดยเฉพาะโมเดลบทสนทนา ชุดข้อมูลแบ่งออกเป็นสองส่วน ได้แก่ ชุดข้อมูลคำสั่งพื้นฐาน Infinity-Instruct-7M และชุดข้อมูลคำสั่งบทสนทนา Infinity-Instruct-Gen ชุดแรกมีข้อมูลมากกว่า 7.44 ล้านชิ้น ครอบคลุมหลายสาขา และใช้เพื่อปรับปรุง ความสามารถพื้นฐานของโมเดล ส่วนหลังมี 1.49 ล้านคำสั่งที่ซับซ้อน ได้รับการออกแบบมาเพื่อเพิ่มความแข็งแกร่งของโมเดลในสถานการณ์การสนทนาจริง จากผลการทดสอบ โมเดลที่ได้รับการปรับแต่งอย่างละเอียดโดยใช้ Infinity-Instruct ได้รับผลลัพธ์ที่ยอดเยี่ยมในรายการประเมินกระแสหลักหลายรายการ แม้จะเหนือกว่าโมเดลการสนทนาอย่างเป็นทางการบางรุ่นก็ตาม
Zhiyuan Research Institute ได้เปิดตัวชุดข้อมูลการปรับแต่งคำสั่งหลายสิบล้านชุดที่เรียกว่า Infinity-Instruct โดยมีเป้าหมายเพื่อปรับปรุงประสิทธิภาพของโมเดลภาษาในบทสนทนาและด้านอื่นๆ เมื่อเร็วๆ นี้ Infinity Instruct ได้เสร็จสิ้นการทำซ้ำรอบใหม่ ซึ่งรวมถึงชุดข้อมูลคำสั่งพื้นฐานของ Infinity-Instruct-7M และชุดข้อมูลคำสั่งบทสนทนา Infinity-Instruct-Gen
ชุดข้อมูลคำสั่งพื้นฐานของ Infinity-Instruct-7M มีข้อมูลมากกว่า 7.44 ล้านชิ้น ซึ่งครอบคลุมสาขาต่างๆ เช่น คณิตศาสตร์ โค้ด และคำถามและคำตอบความรู้ทั่วไป และมีจุดมุ่งหมายเพื่อปรับปรุงความสามารถพื้นฐานของโมเดลที่ได้รับการฝึกอบรมล่วงหน้า ผลการทดสอบแสดงให้เห็นว่ารุ่น Llama3.1-70B และ Mistral-7B-v0.1 ที่ได้รับการปรับแต่งอย่างละเอียดโดยใช้ชุดข้อมูลนี้ ใกล้เคียงกับโมเดลการสนทนาที่เปิดตัวอย่างเป็นทางการในแง่ของความสามารถที่ครอบคลุม ในบรรดาโมเดลเหล่านี้ Mistral-7B ยังเหนือกว่า GPT อีกด้วย -3.5 ในขณะที่ Llama3 .1-70B ใกล้เคียงกับ GPT-4
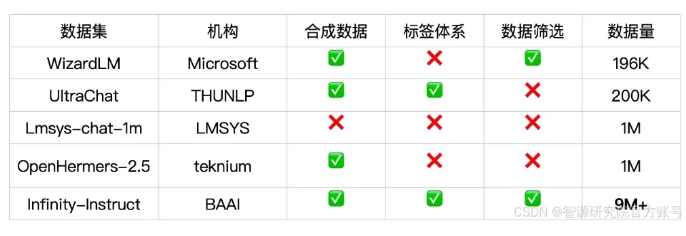
ชุดข้อมูลคำสั่งบทสนทนา Infinity-Instruct-Gen ประกอบด้วยคำสั่งที่ซับซ้อนสังเคราะห์ 1.49 ล้านคำสั่ง โดยมีวัตถุประสงค์เพื่อปรับปรุงความทนทานของแบบจำลองในสถานการณ์การสนทนาจริง หลังจากปรับแต่งเพิ่มเติมโดยใช้ชุดข้อมูลนี้ โมเดลจะสามารถทำงานได้ดีกว่าโมเดลการสนทนาอย่างเป็นทางการ
Zhiyuan Research Institute ทดสอบ Infinity-Instruct ในรายการประเมินผลกระแสหลัก เช่น MTBench, AlpacaEval2 และ Arena-Hard ผลการวิจัยพบว่าโมเดลที่ได้รับการปรับแต่งอย่างละเอียดโดย Infinity-Instruct นั้นเหนือกว่าโมเดลอย่างเป็นทางการในแง่ของความสามารถในการสนทนา
Infinity-Instruct ให้คำอธิบายประกอบโดยละเอียดสำหรับข้อมูลคำสั่งแต่ละรายการ เช่น ภาษา ประเภทความสามารถ ประเภทงาน และแหล่งข้อมูล ทำให้ผู้ใช้สามารถกรองชุดย่อยของข้อมูลตามความต้องการได้อย่างง่ายดาย Zhiyuan Research Institute ได้สร้างชุดข้อมูลคุณภาพสูงผ่านการเลือกข้อมูลและการสังเคราะห์คำสั่ง เพื่อลดช่องว่างระหว่างโมเดลการสนทนาแบบโอเพ่นซอร์สและ GPT-4
โปรเจ็กต์ยังใช้เฟรมเวิร์กการฝึกอบรม FlagScale เพื่อลดต้นทุนการปรับแต่ง และกำจัดตัวอย่างที่ซ้ำกันผ่านการขจัดข้อมูลซ้ำซ้อน MinHash และการดึงข้อมูล BGE Zhiyuan วางแผนที่จะโอเพ่นซอร์สโค้ดกระบวนการทั้งหมดของการประมวลผลข้อมูลและการฝึกฝนโมเดลในอนาคต และสำรวจการขยายกลยุทธ์ข้อมูล Infinity-Instruct ไปสู่การจัดตำแหน่งและขั้นตอนก่อนการฝึกอบรม เพื่อรองรับข้อกำหนดข้อมูลวงจรชีวิตเต็มรูปแบบของโมเดลภาษา
ลิงค์ชุดข้อมูล:
https://modelscope.cn/datasets/BAAI/Infinity-Instruct
การเปิดตัวชุดข้อมูล Infinity-Instruct มอบวิธีใหม่ในการปรับปรุงประสิทธิภาพของโมเดลภาษา และมีส่วนช่วยในการพัฒนาเทคโนโลยีโมเดลขนาดใหญ่ บรรณาธิการของ Downcodes หวังว่า Infinity-Instruct จะได้รับการปรับปรุงเพิ่มเติมในอนาคต เพื่อให้การสนับสนุนสำหรับนักวิจัยและนักพัฒนามากขึ้น