O editor do Downcodes soube que o Zhiyuan Research Institute lançou recentemente o Infinity-Instruct, um conjunto de dados ajustado contendo dezenas de milhões de instruções, com o objetivo de melhorar significativamente o desempenho dos modelos de linguagem, especialmente dos modelos de diálogo. O conjunto de dados é dividido em duas partes: conjunto de dados de instruções básicas Infinity-Instruct-7M e conjunto de dados de instruções de diálogo Infinity-Instruct-Gen. O primeiro contém mais de 7,44 milhões de dados, cobrindo vários campos, e é usado para melhorar o. capacidades básicas do modelo; este último contém 1,49 milhão de instruções complexas projetadas para aumentar a robustez do modelo em cenários reais de diálogo. De acordo com os resultados dos testes, o modelo ajustado usando o Infinity-Instruct alcançou excelentes resultados em várias listas de avaliação convencionais, superando até mesmo alguns modelos de diálogo oficiais.
O Instituto de Pesquisa Zhiyuan lançou um conjunto de dados de ajuste fino de instruções de dezenas de milhões chamado Infinity-Instruct, com o objetivo de melhorar o desempenho dos modelos de linguagem no diálogo e outros aspectos. Recentemente, o Infinity Instruct completou uma nova rodada de iterações, incluindo o conjunto de dados de instruções básicas Infinity-Instruct-7M e o conjunto de dados de instruções de diálogo Infinity-Instruct-Gen.
O conjunto de dados de instruções básicas Infinity-Instruct-7M contém mais de 7,44 milhões de dados, abrangendo áreas como matemática, código e perguntas e respostas de conhecimento geral, e é dedicado a melhorar os recursos básicos de modelos pré-treinados. Os resultados do teste mostram que os modelos Llama3.1-70B e Mistral-7B-v0.1 ajustados usando este conjunto de dados estão próximos do modelo de conversação lançado oficialmente em termos de capacidades abrangentes. Entre eles, o Mistral-7B supera até mesmo o GPT. -3,5, enquanto Llama3 .1-70B está próximo de GPT-4.
O conjunto de dados de instruções de diálogo Infinity-Instruct-Gen contém 1,49 milhão de instruções complexas sintéticas, com o objetivo de melhorar a robustez do modelo em cenários reais de diálogo. Após ajustes adicionais usando este conjunto de dados, o modelo pode superar os modelos conversacionais oficiais.
O Zhiyuan Research Institute testou o Infinity-Instruct em listas de avaliação convencionais, como MTBench, AlpacaEval2 e Arena-Hard. Os resultados mostraram que o modelo ajustado pelo Infinity-Instruct superou o modelo oficial em termos de capacidades de conversação.
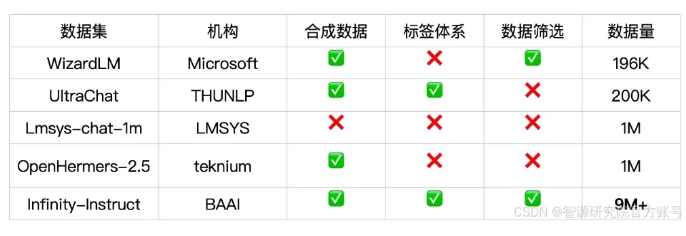
O Infinity-Instruct fornece anotações detalhadas para cada dado de instrução, como idioma, tipo de capacidade, tipo de tarefa e fonte de dados, facilitando aos usuários a filtragem de subconjuntos de dados de acordo com as necessidades. O Instituto de Pesquisa Zhiyuan construiu conjuntos de dados de alta qualidade por meio da seleção de dados e síntese de instruções para preencher a lacuna entre os modelos de conversação de código aberto e o GPT-4.
O projeto também usa a estrutura de treinamento FlagScale para reduzir custos de ajuste fino e elimina amostras duplicadas por meio de desduplicação MinHash e recuperação BGE. Zhiyuan planeja abrir o código-fonte de todo o código do processo de processamento de dados e treinamento de modelo no futuro e explorar a extensão da estratégia de dados Infinity-Instruct aos estágios de alinhamento e pré-treinamento para dar suporte aos requisitos de dados do ciclo de vida completo dos modelos de linguagem.
Link do conjunto de dados:
https://modelscope.cn/datasets/BAAI/Infinity-Instruct
O lançamento do conjunto de dados Infinity-Instruct oferece uma nova maneira de melhorar o desempenho de modelos de linguagem e contribui para o desenvolvimento de tecnologia de modelos grandes. O editor do Downcodes espera que o Infinity-Instruct possa ser melhorado ainda mais no futuro para fornecer suporte a mais pesquisadores e desenvolvedores.