El editor de Downcodes se enteró de que el Instituto de Investigación Zhiyuan lanzó recientemente Infinity-Instruct, un conjunto de datos ajustado que contiene decenas de millones de instrucciones, con el objetivo de mejorar significativamente el rendimiento de los modelos de lenguaje, especialmente los modelos de diálogo. El conjunto de datos se divide en dos partes: el conjunto de datos de instrucciones básicas Infinity-Instruct-7M y el conjunto de datos de instrucciones de diálogo Infinity-Instruct-Gen. El primero contiene más de 7,44 millones de datos, que cubren múltiples campos y se utiliza para mejorar. Las capacidades básicas del modelo; este último contiene 1,49 millones de instrucciones complejas que están diseñadas para mejorar la solidez del modelo en escenarios de diálogo reales. Según los resultados de las pruebas, el modelo ajustado con Infinity-Instruct ha logrado excelentes resultados en múltiples listas de evaluación convencionales, incluso superando algunos modelos de diálogo oficiales.
El Instituto de Investigación Zhiyuan ha lanzado un conjunto de datos de ajuste de instrucciones de decenas de millones llamado Infinity-Instruct, con el objetivo de mejorar el rendimiento de los modelos de lenguaje en el diálogo y otros aspectos. Recientemente, Infinity Instruct ha completado una nueva ronda de iteraciones, incluido el conjunto de datos de instrucciones básicas Infinity-Instruct-7M y el conjunto de datos de instrucciones de diálogo Infinity-Instruct-Gen.
El conjunto de datos de instrucciones básicas Infinity-Instruct-7M contiene más de 7,44 millones de datos, que cubren campos como matemáticas, código y preguntas y respuestas de conocimientos generales, y está dedicado a mejorar las capacidades básicas de los modelos previamente entrenados. Los resultados de las pruebas muestran que los modelos Llama3.1-70B y Mistral-7B-v0.1 ajustados con este conjunto de datos están cerca del modelo de conversación lanzado oficialmente en términos de capacidades integrales. Entre ellos, Mistral-7B incluso supera a GPT. -3,5, mientras que Llama3 .1-70B está cerca de GPT-4.
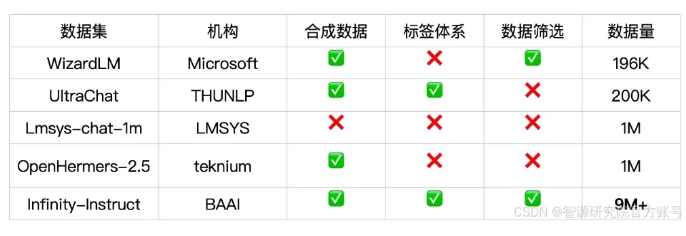
El conjunto de datos de instrucciones de diálogo Infinity-Instruct-Gen contiene 1,49 millones de instrucciones complejas sintéticas, con el propósito de mejorar la robustez del modelo en escenarios de diálogo reales. Después de realizar más ajustes utilizando este conjunto de datos, el modelo puede superar a los modelos conversacionales oficiales.
El Instituto de Investigación Zhiyuan probó Infinity-Instruct en listas de evaluación convencionales como MTBench, AlpacaEval2 y Arena-Hard. Los resultados mostraron que el modelo ajustado por Infinity-Instruct ha superado al modelo oficial en términos de capacidades de conversación.
Infinity-Instruct proporciona anotaciones detalladas para cada dato de instrucción, como idioma, tipo de capacidad, tipo de tarea y fuente de datos, lo que facilita a los usuarios filtrar subconjuntos de datos según las necesidades. El Instituto de Investigación Zhiyuan ha construido conjuntos de datos de alta calidad mediante selección de datos y síntesis de instrucciones para cerrar la brecha entre los modelos de conversación de código abierto y GPT-4.
El proyecto también utiliza el marco de capacitación FlagScale para reducir los costos de ajuste y elimina muestras duplicadas mediante la deduplicación MinHash y la recuperación de BGE. Zhiyuan planea abrir el código de proceso completo de procesamiento de datos y entrenamiento de modelos en el futuro, y explorar la extensión de la estrategia de datos Infinity-Instruct a las etapas de alineación y preentrenamiento para respaldar los requisitos de datos del ciclo de vida completo de los modelos de lenguaje.
Enlace del conjunto de datos:
https://modelscope.cn/datasets/BAAI/Infinity-Instruct
El lanzamiento del conjunto de datos Infinity-Instruct proporciona una nueva forma de mejorar el rendimiento de los modelos de lenguaje y contribuye al desarrollo de tecnología de modelos grandes. El editor de Downcodes espera que Infinity-Instruct pueda mejorarse aún más en el futuro para brindar soporte a más investigadores y desarrolladores.