L'éditeur de Downcodes a appris que le Zhiyuan Research Institute a récemment publié Infinity-Instruct, un ensemble de données affinées contenant des dizaines de millions d'instructions, visant à améliorer considérablement les performances des modèles de langage, en particulier des modèles de dialogue. L'ensemble de données est divisé en deux parties : l'ensemble de données d'instructions de base Infinity-Instruct-7M et l'ensemble de données d'instructions de dialogue Infinity-Instruct-Gen. Le premier contient plus de 7,44 millions de données, couvrant plusieurs domaines, et est utilisé pour améliorer l'ensemble de données. capacités de base du modèle ; ce dernier contient 1,49 million d'instructions complexes conçues pour améliorer la robustesse du modèle dans des scénarios de dialogue réels. Selon les résultats des tests, le modèle affiné à l'aide d'Infinity-Instruct a obtenu d'excellents résultats sur plusieurs listes d'évaluation traditionnelles, dépassant même certains modèles de dialogue officiels.
L'Institut de recherche Zhiyuan a lancé un ensemble de données de réglage précis de dizaines de millions d'instructions appelé Infinity-Instruct, visant à améliorer les performances des modèles de langage dans le dialogue et dans d'autres aspects. Récemment, Infinity Instruct a réalisé une nouvelle série d'itérations, notamment l'ensemble de données d'instructions de base Infinity-Instruct-7M et l'ensemble de données d'instructions de dialogue Infinity-Instruct-Gen.
L'ensemble de données d'instructions de base Infinity-Instruct-7M contient plus de 7,44 millions de données, couvrant des domaines tels que les mathématiques, le code et les questions et réponses de connaissances générales, et est dédié à l'amélioration des capacités de base des modèles pré-entraînés. Les résultats des tests montrent que les modèles Llama3.1-70B et Mistral-7B-v0.1, affinés à l'aide de cet ensemble de données, sont proches du modèle de conversation officiellement publié en termes de capacités complètes. Parmi eux, Mistral-7B surpasse même GPT. -3,5, tandis que Llama3 .1-70B est proche de GPT-4.
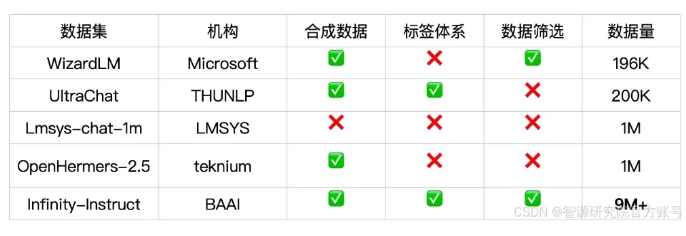
L'ensemble de données d'instructions de dialogue Infinity-Instruct-Gen contient 1,49 million d'instructions complexes synthétiques, dans le but d'améliorer la robustesse du modèle dans des scénarios de dialogue réels. Après un ajustement plus précis à l’aide de cet ensemble de données, le modèle peut surpasser les modèles conversationnels officiels.
L'Institut de recherche Zhiyuan a testé Infinity-Instruct sur des listes d'évaluation traditionnelles telles que MTBench, AlpacaEval2 et Arena-Hard. Les résultats ont montré que le modèle affiné par Infinity-Instruct a dépassé le modèle officiel en termes de capacités conversationnelles.
Infinity-Instruct fournit des annotations détaillées pour chaque donnée d'instruction, telles que la langue, le type de capacité, le type de tâche et la source de données, permettant aux utilisateurs de filtrer facilement les sous-ensembles de données en fonction de leurs besoins. L'Institut de recherche Zhiyuan a construit des ensembles de données de haute qualité grâce à la sélection de données et à la synthèse d'instructions pour combler le fossé entre les modèles de conversation open source et GPT-4.
Le projet utilise également le cadre de formation FlagScale pour réduire les coûts de réglage fin et élimine les échantillons en double grâce à la déduplication MinHash et à la récupération BGE. Zhiyuan prévoit d'ouvrir en source l'intégralité du code du processus de traitement des données et de formation des modèles à l'avenir, et d'explorer l'extension de la stratégie de données Infinity-Instruct aux étapes d'alignement et de pré-formation pour prendre en charge les exigences en matière de données du cycle de vie complet des modèles de langage.
Lien vers l'ensemble de données :
https://modelscope.cn/datasets/BAAI/Infinity-Instruct
La publication de l'ensemble de données Infinity-Instruct offre une nouvelle façon d'améliorer les performances des modèles de langage et contribue au développement de la technologie des grands modèles. L'éditeur de Downcodes espère qu'Infinity-Instruct pourra être encore amélioré à l'avenir pour soutenir davantage de chercheurs et de développeurs.