Der Herausgeber von Downcodes erfuhr, dass das Zhiyuan Research Institute kürzlich Infinity-Instruct veröffentlicht hat, einen fein abgestimmten Datensatz mit mehreren zehn Millionen Anweisungen, der darauf abzielt, die Leistung von Sprachmodellen, insbesondere Dialogmodellen, deutlich zu verbessern. Der Datensatz ist in zwei Teile unterteilt: den Basisbefehlsdatensatz Infinity-Instruct-7M und den Dialogbefehlsdatensatz Infinity-Instruct-Gen. Ersterer enthält mehr als 7,44 Millionen Daten, die mehrere Bereiche abdecken, und wird zur Verbesserung des verwendet Grundfähigkeiten des Modells; letzteres enthält 1,49 Millionen komplexe Anweisungen, die die Robustheit des Modells in realen Dialogszenarien verbessern sollen. Den Testergebnissen zufolge hat das mit Infinity-Instruct verfeinerte Modell auf mehreren Mainstream-Bewertungslisten hervorragende Ergebnisse erzielt und sogar einige offizielle Dialogmodelle übertroffen.
Das Zhiyuan Research Institute hat einen Datensatz zur Feinabstimmung von Anweisungen in zweistelliger Millionenhöhe namens Infinity-Instruct eingeführt, der darauf abzielt, die Leistung von Sprachmodellen im Dialog und in anderen Aspekten zu verbessern. Kürzlich hat Infinity Instruct eine neue Iterationsrunde abgeschlossen, darunter den Basisbefehlsdatensatz Infinity-Instruct-7M und den Dialogbefehlsdatensatz Infinity-Instruct-Gen.
Der grundlegende Befehlsdatensatz von Infinity-Instruct-7M enthält mehr als 7,44 Millionen Daten, die Bereiche wie Mathematik, Code und Fragen und Antworten zum Allgemeinwissen abdecken, und dient der Verbesserung der grundlegenden Fähigkeiten vorab trainierter Modelle. Die Testergebnisse zeigen, dass die mithilfe dieses Datensatzes optimierten Modelle Llama3.1-70B und Mistral-7B-v0.1 in Bezug auf umfassende Funktionen dem offiziell veröffentlichten Konversationsmodell nahe kommen. Unter ihnen übertrifft Mistral-7B sogar GPT -3,5, während Llama3 .1-70B nahe an GPT-4 liegt.
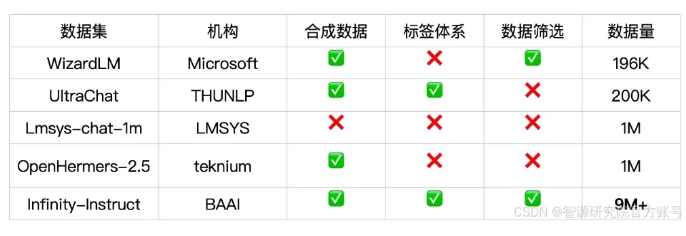
Der Dialoganweisungsdatensatz von Infinity-Instruct-Gen enthält 1,49 Millionen synthetische komplexe Anweisungen mit dem Ziel, die Robustheit des Modells in realen Dialogszenarien zu verbessern. Nach einer weiteren Feinabstimmung mithilfe dieses Datensatzes kann das Modell offizielle Konversationsmodelle übertreffen.
Das Zhiyuan Research Institute testete Infinity-Instruct auf gängigen Bewertungslisten wie MTBench, AlpacaEval2 und Arena-Hard. Die Ergebnisse zeigten, dass das von Infinity-Instruct verfeinerte Modell das offizielle Modell in Bezug auf die Konversationsfähigkeiten übertraf.
Infinity-Instruct bietet detaillierte Anmerkungen zu allen Anweisungsdaten, wie z. B. Sprache, Fähigkeitstyp, Aufgabentyp und Datenquelle, sodass Benutzer Datenteilmengen einfach nach Bedarf filtern können. Das Zhiyuan Research Institute hat durch Datenauswahl und Befehlssynthese hochwertige Datensätze erstellt, um die Lücke zwischen Open-Source-Konversationsmodellen und GPT-4 zu schließen.
Das Projekt nutzt außerdem das FlagScale-Trainingsframework, um die Kosten für die Feinabstimmung zu senken, und eliminiert doppelte Proben durch MinHash-Deduplizierung und BGE-Abruf. Zhiyuan plant, in Zukunft den gesamten Prozesscode der Datenverarbeitung und des Modelltrainings als Open Source bereitzustellen und die Ausweitung der Infinity-Instruct-Datenstrategie auf die Ausrichtungs- und Vortrainingsphasen zu prüfen, um die gesamten Lebenszyklus-Datenanforderungen von Sprachmodellen zu unterstützen.
Link zum Datensatz:
https://modelscope.cn/datasets/BAAI/Infinity-Instruct
Die Veröffentlichung des Infinity-Instruct-Datensatzes bietet eine neue Möglichkeit zur Verbesserung der Leistung von Sprachmodellen und trägt zur Entwicklung der Großmodelltechnologie bei. Der Herausgeber von Downcodes hofft, dass Infinity-Instruct in Zukunft weiter verbessert werden kann, um mehr Forscher und Entwickler zu unterstützen.