علم محرر Downcodes أن معهد Zhiyuan للأبحاث أصدر مؤخرًا Infinity-Instruct، وهي مجموعة بيانات دقيقة تحتوي على عشرات الملايين من التعليمات، تهدف إلى تحسين أداء نماذج اللغة بشكل كبير، وخاصة نماذج الحوار. تنقسم مجموعة البيانات إلى جزأين: مجموعة بيانات التعليمات الأساسية Infinity-Instruct-7M ومجموعة بيانات تعليمات الحوار Infinity-Instruct-Gen، تحتوي الأولى على أكثر من 7.44 مليون قطعة من البيانات، تغطي مجالات متعددة، وتستخدم لتحسين القدرات الأساسية للنموذج؛ يحتوي الأخير على 1.49 مليون تعليمات معقدة مصممة لتعزيز قوة النموذج في سيناريوهات الحوار الحقيقية. وفقًا لنتائج الاختبار، حقق النموذج الذي تم ضبطه باستخدام Infinity-Instruct نتائج ممتازة في قوائم التقييم الرئيسية المتعددة، حتى أنه تجاوز بعض نماذج الحوار الرسمية.
أطلق معهد Zhiyuan للأبحاث مجموعة من عشرات الملايين من بيانات الضبط الدقيق للتعليمات تسمى Infinity-Instruct، بهدف تحسين أداء نماذج اللغة في الحوار والجوانب الأخرى. في الآونة الأخيرة، أكملت Infinity Instruct جولة جديدة من التكرارات، بما في ذلك مجموعة بيانات التعليمات الأساسية Infinity-Instruct-7M ومجموعة بيانات تعليمات الحوار Infinity-Instruct-Gen.
تحتوي مجموعة بيانات التعليمات الأساسية Infinity-Instruct-7M على أكثر من 7.44 مليون قطعة من البيانات، تغطي مجالات مثل الرياضيات والتعليمات البرمجية والمعرفة العامة للأسئلة والأجوبة، وهي مخصصة لتحسين القدرات الأساسية للنماذج المدربة مسبقًا. وتظهر نتائج الاختبار أن نماذج Llama3.1-70B وMistral-7B-v0.1 التي تم ضبطها بدقة باستخدام مجموعة البيانات هذه قريبة من نموذج المحادثة الذي تم إصداره رسميًا من حيث القدرات الشاملة، ومن بينها، يتفوق Mistral-7B على GPT -3.5، بينما Llama3 .1-70B قريب من GPT-4.
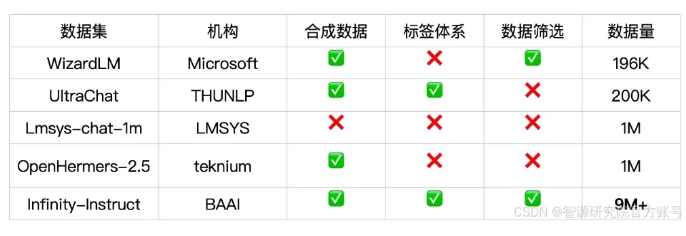
تحتوي مجموعة بيانات تعليمات الحوار Infinity-Instruct-Gen على 1.49 مليون تعليمات معقدة اصطناعية، بهدف تحسين قوة النموذج في سيناريوهات الحوار الحقيقية. وبعد مزيد من الضبط باستخدام مجموعة البيانات هذه، يمكن للنموذج أن يتفوق في الأداء على نماذج المحادثة الرسمية.
قام معهد Zhiyuan للأبحاث باختبار Infinity-Instruct على قوائم التقييم الرئيسية مثل MTBench وAlpacaEval2 وArena-Hard، وأظهرت النتائج أن النموذج الذي تم ضبطه بواسطة Infinity-Instruct قد تجاوز النموذج الرسمي من حيث قدرات المحادثة.
يوفر Infinity-Instruct تعليقات توضيحية تفصيلية لكل بيانات التعليمات، مثل اللغة ونوع القدرة ونوع المهمة ومصدر البيانات، مما يسهل على المستخدمين تصفية مجموعات البيانات الفرعية وفقًا للاحتياجات. قام معهد Zhiyuan للأبحاث ببناء مجموعات بيانات عالية الجودة من خلال اختيار البيانات وتوليف التعليمات لسد الفجوة بين نماذج المحادثة مفتوحة المصدر وGPT-4.
يستخدم المشروع أيضًا إطار تدريب FlagScale لتقليل تكاليف الضبط الدقيق، وإزالة العينات المكررة من خلال إلغاء البيانات المكررة من MinHash واسترجاع BGE. تخطط Zhiyuan لفتح مصدر كود العملية بالكامل لمعالجة البيانات والتدريب النموذجي في المستقبل، واستكشاف توسيع استراتيجية البيانات Infinity-Instruct لتشمل مراحل المحاذاة والتدريب المسبق لدعم متطلبات بيانات دورة الحياة الكاملة لنماذج اللغة.
رابط مجموعة البيانات:
https://modelscope.cn/datasets/BAAI/Infinity-Instruct
يوفر إصدار مجموعة بيانات Infinity-Instruct طريقة جديدة لتحسين أداء نماذج اللغة ويساهم في تطوير تكنولوجيا النماذج الكبيرة. يأمل محرر Downcodes أن يتم تحسين Infinity-Instruct بشكل أكبر في المستقبل لتوفير الدعم لمزيد من الباحثين والمطورين.