Downcodes の編集者は、Zhiyuan Research Institute が言語モデル、特に対話モデルのパフォーマンスを大幅に向上させることを目的として、数千万の命令を含む微調整されたデータセットである Infinity-Instruct を最近リリースしたことを知りました。データセットは、Infinity-Instruct-7M 基本命令データセットと Infinity-Instruct-Gen 対話命令データセットの 2 つの部分に分かれており、前者には複数の分野をカバーする 744 万件以上のデータが含まれており、改善に使用されます。モデルの基本機能。後者には、実際の対話シナリオにおけるモデルの堅牢性を高めるために設計された 149 万の複雑な命令が含まれています。テスト結果によると、Infinity-Instruct を使用して微調整されたモデルは、複数の主流の評価リストで優れた結果を達成し、一部の公式対話モデルをも上回りました。
Zhiyuan Research Institute は、対話やその他の側面における言語モデルのパフォーマンスを向上させることを目的として、Infinity-Instruct と呼ばれる数千万の命令微調整データセットを開始しました。最近、Infinity Instruct は、Infinity-Instruct-7M 基本命令データ セットおよび Infinity-Instruct-Gen ダイアログ命令データ セットを含む、新たな反復ラウンドを完了しました。
Infinity-Instruct-7M の基本命令データ セットには、数学、コード、一般知識 Q&A などの分野をカバーする 744 万件を超えるデータが含まれており、事前トレーニングされたモデルの基本機能の向上に特化しています。テスト結果は、このデータセットを使用して微調整された Llama3.1-70B モデルと Mistral-7B-v0.1 モデルが、総合的な機能の点で正式にリリースされた会話モデルに近いことを示しています。その中でも、Mistral-7B は GPT をも上回っています。 -3.5、Llama3 .1-70B は GPT-4 に近いです。
Infinity-Instruct-Gen 対話命令データ セットには、実際の対話シナリオにおけるモデルの堅牢性を向上させる目的で、149 万の合成複合命令が含まれています。このデータセットを使用してさらに微調整すると、モデルは公式の会話モデルを上回るパフォーマンスを発揮できるようになります。
Zhiyuan Research Institute は、MTBench、AlpacaEval2、Arena-Hard などの主流の評価リストで Infinity-Instruct をテストした結果、Infinity-Instruct によって微調整されたモデルが会話機能の点で公式モデルを上回っていることがわかりました。
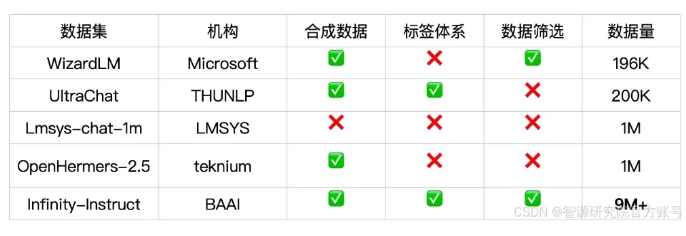
Infinity-Instruct は、言語、機能タイプ、タスクタイプ、データソースなどの各命令データに詳細な注釈を提供し、ユーザーがニーズに応じてデータサブセットを簡単にフィルタリングできるようにします。 Zhiyuan Research Institute は、オープンソースの会話モデルと GPT-4 の間のギャップを埋めるために、データ選択と命令合成を通じて高品質のデータセットを構築しました。
このプロジェクトでは、FlagScale トレーニング フレームワークを使用して微調整コストを削減し、MinHash 重複排除と BGE 取得を通じて重複サンプルを排除します。 Zhiyuan は、将来的にデータ処理とモデル トレーニングのプロセス コード全体をオープンソース化し、言語モデルのライフ サイクル データ要件全体をサポートするために、Infinity-Instruct データ戦略を調整段階と事前トレーニング段階に拡張することを検討する予定です。
データセットのリンク:
https://modelscope.cn/datasets/BAAI/Infinity-Instruct
Infinity-Instruct データセットのリリースは、言語モデルのパフォーマンスを向上させる新しい方法を提供し、大規模モデル技術の開発に貢献します。 Downcodes の編集者は、Infinity-Instruct が将来的にさらに改良され、より多くの研究者や開発者にサポートを提供できることを期待しています。