mLoRA
1.0.0
Mlora
"โรงงาน" ที่มีประสิทธิภาพในการสร้างอะแดปเตอร์ Lora หลายตัว

MLORA (AKA Multi-Lora Fine-Tune) เป็นเฟรมเวิร์กโอเพนซอร์ซที่ออกแบบมาสำหรับการปรับแต่งแบบจำลองภาษาขนาดใหญ่หลายแบบ (LLMS) อย่างมีประสิทธิภาพโดยใช้ LORA และตัวแปร คุณสมบัติที่สำคัญของ Mlora ได้แก่ :
การปรับจูนอย่างละเอียดพร้อมกันของอะแดปเตอร์ LORA หลายตัว
โมเดลพื้นฐานที่ใช้ร่วมกันในหลายอะแดปเตอร์ LORA
อัลกอริทึมการขนานท่อที่มีประสิทธิภาพ
รองรับอัลกอริทึมตัวแปร LORA หลายตัวและรุ่นพื้นฐานต่างๆ
การสนับสนุนอัลกอริทึมการจัดตำแหน่งการจัดตำแหน่งการเรียนรู้การเสริมแรงหลายครั้ง
สถาปัตยกรรมแบบ end-to-end ของ Mlora แสดงในรูป:
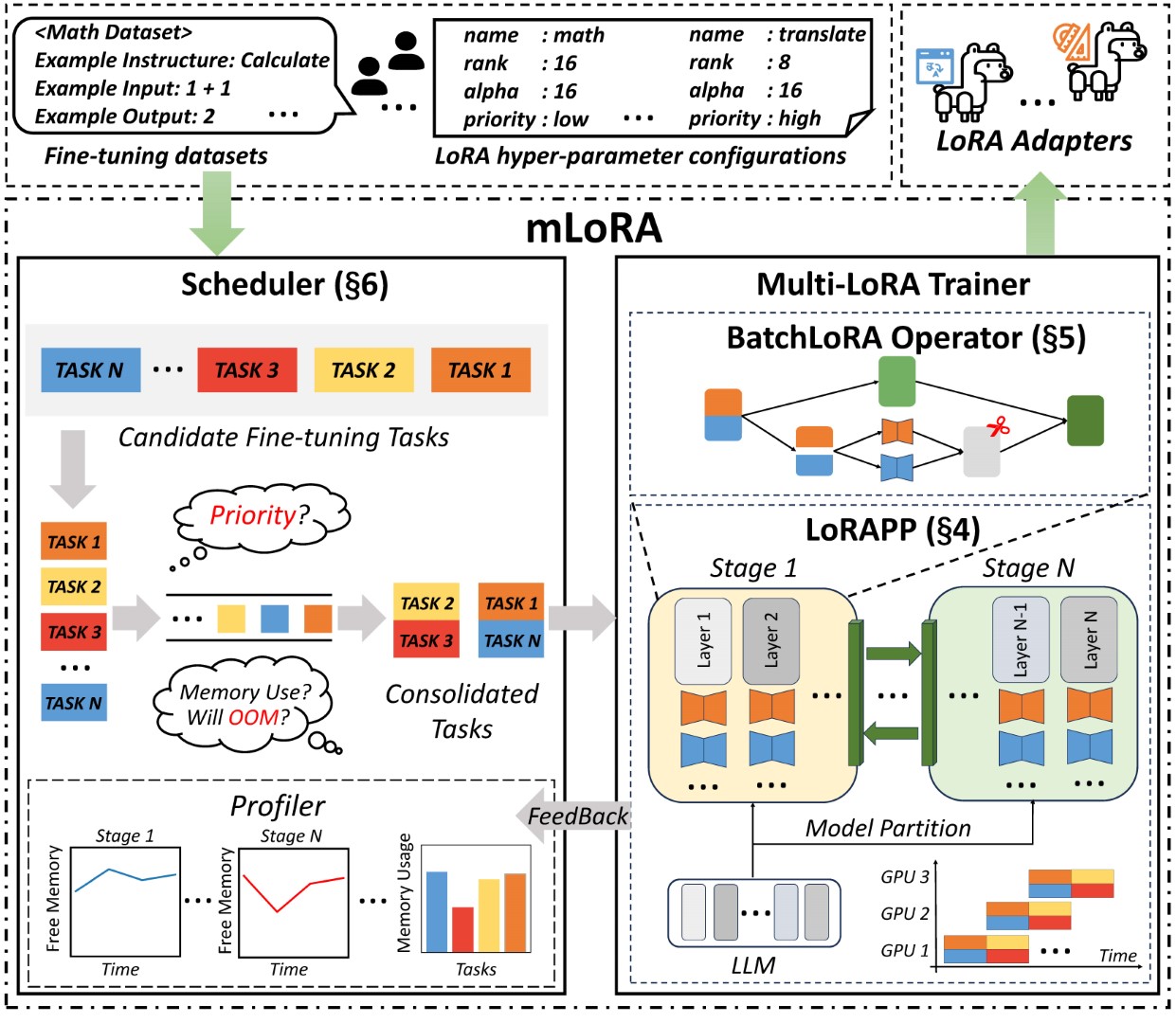
ประการแรกคุณควรโคลนพื้นที่เก็บข้อมูลนี้และติดตั้งการพึ่งพา (หรือใช้ภาพของเรา):
# Clone Repository
git clone https://github.com/TUDB-Labs/mLoRA
cd mLoRA
# Install requirements need the Python >= 3.12
pip install . รหัส mlora_train.py เป็นจุดเริ่มต้นสำหรับอะแดปเตอร์ LORA แบบปรับแต่งแบทช์
python mlora_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yamlคุณสามารถตรวจสอบการกำหนดค่าของอะแดปเตอร์ในโฟลเดอร์สาธิตมีการกำหนดค่าบางอย่างเกี่ยวกับการใช้ตัวแปร LORA ที่แตกต่างกันและอัลกอริทึมการจัดตำแหน่งการจัดเรียงการปรับแต่ง
สำหรับข้อมูลการใช้งานโดยละเอียดเพิ่มเติมโปรดใช้ --help ตัวเลือกการช่วยเหลือ:
python mlora_train.py --helpคล้ายกับ QuickStart คำสั่งที่จะเริ่มในสภาพแวดล้อมสองโหนดมีดังนี้:
หมายเหตุ 1: ใช้ตัวแปรสภาพแวดล้อม MASTER_ADDR/MASTER_PORT เพื่อตั้งค่าโหนดหลัก
หมายเหตุ 2: ตั้งค่าสมดุลซึ่งระบุจำนวนเลเยอร์ถอดรหัสที่จัดสรรให้กับแต่ละอันดับ
# in the first node
export MASTER_ADDR=master.svc.cluster.local
export MASTER_PORT=12355
python mlora_pp_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yaml
--pipeline
--device " cuda:0 "
--rank 0
--balance 12 13
--no-recompute
--precision fp32
# in the second node
export MASTER_ADDR=master.svc.cluster.local
export MASTER_PORT=12355
python mlora_pp_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yaml
--pipeline
--device " cuda:1 "
--rank 1
--balance 12 13
--no-recompute
--precision fp32Mlora เสนอภาพนักเทียบท่าอย่างเป็นทางการสำหรับการเริ่มต้นและการพัฒนาอย่างรวดเร็วรูปภาพมีอยู่ในรีจิสทรีแพ็คเกจ DockerHub
ก่อนอื่นคุณควรดึงภาพล่าสุด (ภาพใช้เพื่อการพัฒนา):
docker pull yezhengmaolove/mlora:latestปรับใช้และป้อนคอนเทนเนอร์เพื่อเรียกใช้ Mlora:
docker run -itd --runtime nvidia --gpus all
-v ~ /your_dataset_dir:/dataset
-v ~ /your_model_dir:/model
-p < host_port > :22
--name mlora
yezhengmaolove/mlora:latest
# when the container started, use the ssh to login
# the default password is mlora@123
ssh root@localhost -p < host_port >
# pull the latest code and run the mlora
cd /mLoRA
git pull
python mlora_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yamlเราสามารถปรับใช้ mloar เป็นบริการเพื่อรับคำขอของผู้ใช้อย่างต่อเนื่องและดำเนินงานปรับแต่ง
ก่อนอื่นคุณควรดึงภาพล่าสุด (ใช้ภาพเดียวกันสำหรับการปรับใช้):
docker pull yezhengmaolove/mlora:latestปรับใช้เซิร์ฟเวอร์ Mlora ของเรา:
docker run -itd --runtime nvidia --gpus all
-v ~ /your_dataset_cache_dir:/cache
-v ~ /your_model_dir:/model
-p < host_port > :8000
--name mlora_server
-e " BASE_MODEL=TinyLlama/TinyLlama-1.1B-Chat-v0.4 "
-e " STORAGE_DIR=/cache "
yezhengmaolove/mlora:latest /bin/bash /opt/deploy.sh เมื่อบริการถูกปรับใช้ให้ติดตั้งและใช้ mlora_cli.py เพื่อโต้ตอบกับเซิร์ฟเวอร์
# install the client tools
pip install mlora-cli
# use the mlora cli tool to connect to mlora server
mlora_cli
(mLoRA) set port < host_port >
(mLoRA) set host http:// < host_ip >
# and enjoy it!!docker pull yezhengmaolove/mlora:latest
pip install mlora-cli # first, we create a cache dir in host for cache some file
mkdir ~ /cache
# second, we manually download the model weights from Hugging Face.
mkdir ~ /model && cd ~ /model
git clone https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0
# we map port 8000 used by the mlora server to port 1288 on the host machine.
# the BASE_MODEL environment variable indicates the path of the base model used by mlora.
# the STORAGE_DIR environment variable indicates the path where datasets and lora adapters are stored.
# we use the script /opt/deploy.sh in container to start the server.
docker run -itd --runtime nvidia --gpus all
-v ~ /cache:/cache
-v ~ /model:/model
-p 1288:8000
--name mlora_server
-e " BASE_MODEL=/model/TinyLlama-1.1B-Chat-v1.0 "
-e " STORAGE_DIR=/cache "
yezhengmaolove/mlora:latest /bin/bash /opt/deploy.shเราใช้ลิงก์ mlora_cli ไปยังเซิร์ฟเวอร์ http://127.0.0.1:1288 (ต้องใช้ http protocal)
(mLoRA) set port 1288
(mLoRA) set host http://127.0.0.1เราใช้ชุดข้อมูล Stanford Alpaca เป็นตัวอย่างข้อมูลเช่นเดียวกับด้านล่าง:
[{ "instruction" : " " , "input" : " " , "output" : }, { ... }](mLoRA) file upload
? file type: train data
? name: alpaca
? file path: /home/yezhengmao/alpaca-lora/alpaca_data.jsonเทมเพลตในไฟล์ yaml และเขียนโดย templating ภาษา jinja2 ดูไฟล์ demo/prompt.yaml
ไฟล์ข้อมูลที่คุณอัปโหลดถือได้ว่าเป็นข้อมูลอาร์เรย์โดยมีองค์ประกอบในอาร์เรย์ที่เป็นประเภทพจนานุกรม เราพิจารณาแต่ละองค์ประกอบเป็นจุดข้อมูลในเทมเพลต
(mLoRA) file upload
? file type: prompt template
? name: simple_prompt
? file path: /home/yezhengmao/mLoRA/demo/prompt.yaml เราสร้างชุดข้อมูลชุดข้อมูลประกอบด้วยข้อมูลเทมเพลตและ prompter ที่เกี่ยวข้อง เราสามารถใช้คำสั่ง dataset showcase เพื่อตรวจสอบว่ามีการสร้างพรอมต์อย่างถูกต้องหรือไม่
(mLoRA) dataset create
? name: alpaca_dataset
? train data file: alpaca
? prompt template file: simple_prompt
? prompter: instruction
? data preprocessing: default
(mLoRA) dataset showcase
? dataset name: alpaca_dataset ตอนนี้เราสามารถใช้คำสั่ง adapter create เพื่อสร้างอะแดปเตอร์สำหรับรถไฟ
ในที่สุดเราสามารถส่งงานเพื่อฝึกอะแดปเตอร์ของเราโดยใช้ชุดข้อมูลที่กำหนดไว้ หมายเหตุ: คุณสามารถส่งหรืองานฝึกอบรมอย่างต่อเนื่อง ใช้ adapter ls หรือ task ls เพื่อตรวจสอบสถานะของงาน
การใช้ MLORA สามารถประหยัดทรัพยากรการคำนวณและหน่วยความจำที่สำคัญเมื่อฝึกอบรมอะแดปเตอร์หลายตัวพร้อมกัน
เราปรับอะแดปเตอร์ LORA หลายตัวโดยใช้กราฟิก A6000 สี่ตัวที่มีความแม่นยำ FP32 และไม่ต้องใช้ด่านตรวจและเทคนิคการหาปริมาณใด ๆ :
| แบบอย่าง | Mlora (โทเค็น/s) | Peft-lora กับ FSDP (โทเค็น/s) | Peft-lora กับ TP (โทเค็น/s) |
|---|---|---|---|
| LLAMA-2-7B (32FP) | 2364 | 2293 | 1500 |
| LLAMA-2-13B (32FP) | 1280 | สิ่งที่น่าเบื่อหน่าย | 875 |
| แบบอย่าง | |
|---|---|
| ลาม่า |
| แตกต่างกันไป | |
|---|---|
| Qlora, NIPS, 2023 | |
| Lora+, ICML, 2024 | |
| Vera, ICLR, 2024 | |
| Dora, ICML, 2024 |
| แตกต่างกันไป | |
|---|---|
| DPO, Neurips, 2024 | |
| CPO, ICML, 2024 | |
| cit, arxiv, 2024 |
เรายินดีต้อนรับการมีส่วนร่วมในการปรับปรุงที่เก็บนี้! โปรดตรวจสอบแนวทางการบริจาคก่อนที่จะส่งคำขอหรือปัญหาการดึง
แยกที่เก็บ สร้างสาขาใหม่สำหรับคุณสมบัติหรือการแก้ไขของคุณ ส่งคำขอดึงพร้อมคำอธิบายโดยละเอียดเกี่ยวกับการเปลี่ยนแปลงของคุณ
คุณสามารถใช้ pre-commit เพื่อตรวจสอบรหัสของคุณ
# Install requirements
pip install .[ci_test]
ln -s ../../.github/workflows/pre-commit .git/hooks/pre-commitหรือเพียงแค่เรียกสคริปต์เพื่อตรวจสอบรหัสของคุณ
.github/workflows/pre-commitโปรดอ้างอิง repo หากคุณใช้รหัสใน repo นี้
@misc { m-LoRA ,
author = { Zhengmao, Yetextsuperscript{*} and Dengchun, Litextsuperscript{*} and Jingqi, Tian and Tingfeng, Lan and Yanbo, Liang and Yexi, Jiang and Jie, Zuo and Hui, Lu and Lei, Duan and Mingjie, Tang } ,
title = { m-LoRA: Efficient LLM Model Fine-tune and Inference via Multi-Lora Optimization } ,
year = { 2023 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/TUDB-Labs/mLoRA} } ,
note = { textsuperscript{*}: these authors contributed equally to this work. }
}ลิขสิทธิ์© 2024 สงวนลิขสิทธิ์
โครงการนี้ได้รับใบอนุญาตภายใต้ใบอนุญาต Apache 2.0
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


