mLoRA
1.0.0
mora
Una "fábrica" eficiente para construir múltiples adaptadores de lora

Mlora (también conocido como Tune Fine MultiLora) es un marco de código abierto diseñado para ajuste fino eficiente de múltiples modelos de lenguaje grande (LLM) utilizando Lora y sus variantes. Las características clave de Mlora incluyen:
Ajuste fino concurrente de múltiples adaptadores de lora.
Modelo base compartido entre múltiples adaptadores Lora.
Algoritmo eficiente de paralelismo de la tubería.
Soporte para múltiples algoritmos de variantes LORA y varios modelos base.
Soporte para algoritmos de alineación de preferencia de aprendizaje de refuerzo múltiple.
La arquitectura de extremo a extremo de la Mlora se muestra en la figura:
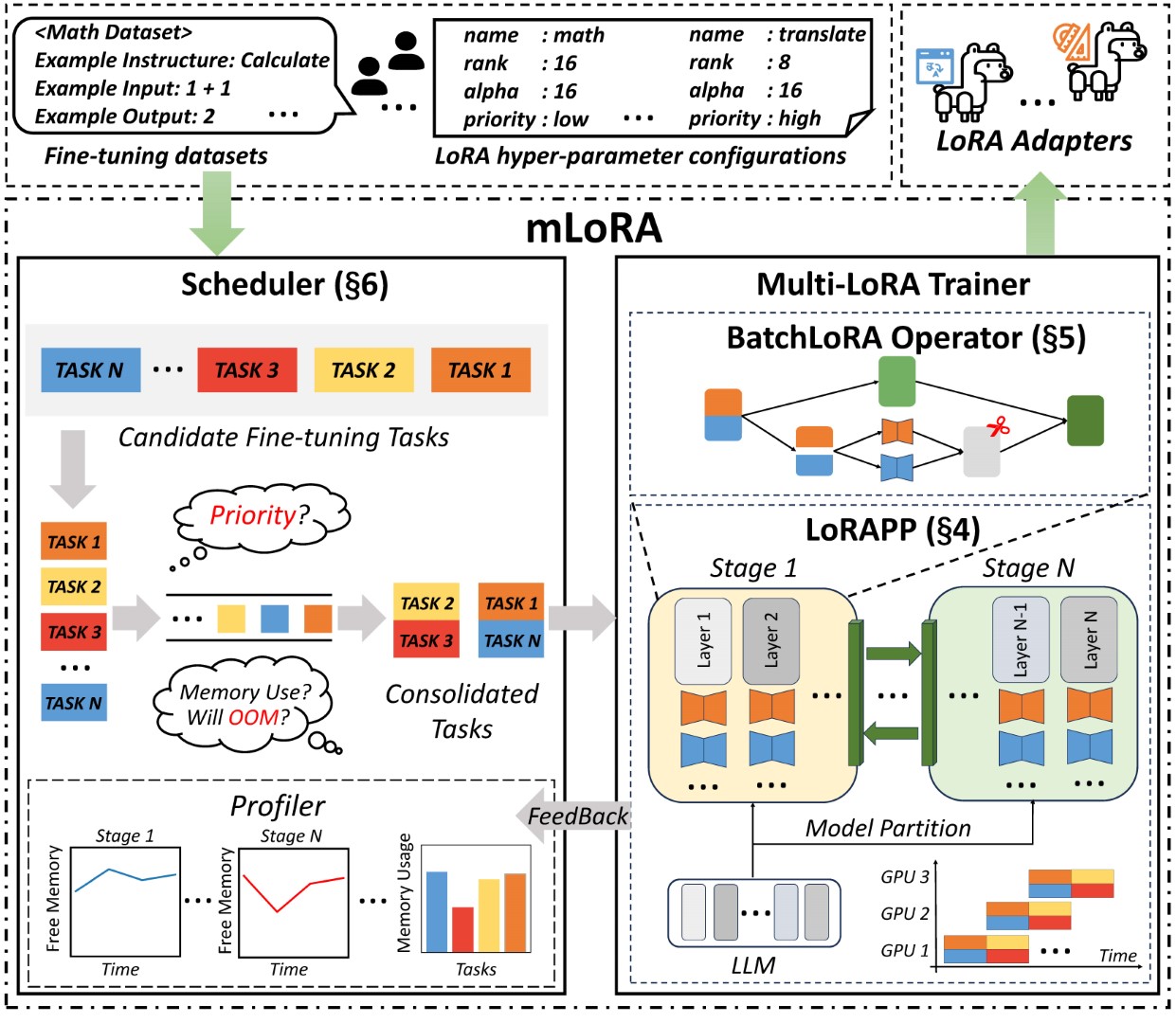
En primer lugar, debe clonar este repositorio e instalar dependencias (o usar nuestra imagen):
# Clone Repository
git clone https://github.com/TUDB-Labs/mLoRA
cd mLoRA
# Install requirements need the Python >= 3.12
pip install . El código mlora_train.py es un punto de partida para adaptadores Lora de ajuste fino por lotes.
python mlora_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yamlPuede verificar la configuración de los adaptadores en la carpeta de demostración, hay alguna configuración con respecto al uso de diferentes variantes de Lora y algoritmos de alineación de preferencia de aprendizaje de refuerzo.
Para obtener más información sobre el uso detallada, utilice la opción --help :
python mlora_train.py --helpSimilar a QuickStart, el comando para comenzar en un entorno de dos nodos es el siguiente:
Nota1: Use las variables de entorno MASTER_ADDR/MASTER_PORT para establecer el nodo maestro.
Nota 2: Establecer Balance, indicando el número de capas de decodificadores asignadas a cada rango.
# in the first node
export MASTER_ADDR=master.svc.cluster.local
export MASTER_PORT=12355
python mlora_pp_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yaml
--pipeline
--device " cuda:0 "
--rank 0
--balance 12 13
--no-recompute
--precision fp32
# in the second node
export MASTER_ADDR=master.svc.cluster.local
export MASTER_PORT=12355
python mlora_pp_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yaml
--pipeline
--device " cuda:1 "
--rank 1
--balance 12 13
--no-recompute
--precision fp32Mlora ofrece una imagen oficial de Docker para inicio y desarrollo rápido, la imagen está disponible en el registro de paquetes DockerHub.
Primero, debe extraer la última imagen (la imagen también se usa para el desarrollo):
docker pull yezhengmaolove/mlora:latestImplementar e ingrese un contenedor para ejecutar MLORA:
docker run -itd --runtime nvidia --gpus all
-v ~ /your_dataset_dir:/dataset
-v ~ /your_model_dir:/model
-p < host_port > :22
--name mlora
yezhengmaolove/mlora:latest
# when the container started, use the ssh to login
# the default password is mlora@123
ssh root@localhost -p < host_port >
# pull the latest code and run the mlora
cd /mLoRA
git pull
python mlora_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yamlPodemos implementar mloar como un servicio para recibir continuamente las solicitudes de los usuarios y realizar tareas de ajuste fino.
Primero, debe extraer la última imagen (use la misma imagen para implementar):
docker pull yezhengmaolove/mlora:latestImplementar nuestro servidor Mlora:
docker run -itd --runtime nvidia --gpus all
-v ~ /your_dataset_cache_dir:/cache
-v ~ /your_model_dir:/model
-p < host_port > :8000
--name mlora_server
-e " BASE_MODEL=TinyLlama/TinyLlama-1.1B-Chat-v0.4 "
-e " STORAGE_DIR=/cache "
yezhengmaolove/mlora:latest /bin/bash /opt/deploy.sh Una vez que se implementa el servicio, instale y use mlora_cli.py para interactuar con el servidor.
# install the client tools
pip install mlora-cli
# use the mlora cli tool to connect to mlora server
mlora_cli
(mLoRA) set port < host_port >
(mLoRA) set host http:// < host_ip >
# and enjoy it!!docker pull yezhengmaolove/mlora:latest
pip install mlora-cli # first, we create a cache dir in host for cache some file
mkdir ~ /cache
# second, we manually download the model weights from Hugging Face.
mkdir ~ /model && cd ~ /model
git clone https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0
# we map port 8000 used by the mlora server to port 1288 on the host machine.
# the BASE_MODEL environment variable indicates the path of the base model used by mlora.
# the STORAGE_DIR environment variable indicates the path where datasets and lora adapters are stored.
# we use the script /opt/deploy.sh in container to start the server.
docker run -itd --runtime nvidia --gpus all
-v ~ /cache:/cache
-v ~ /model:/model
-p 1288:8000
--name mlora_server
-e " BASE_MODEL=/model/TinyLlama-1.1B-Chat-v1.0 "
-e " STORAGE_DIR=/cache "
yezhengmaolove/mlora:latest /bin/bash /opt/deploy.shUsamos el enlace Mlora_cli al servidor http://127.0.0.1:1288 (debe usar la protocal HTTP)
(mLoRA) set port 1288
(mLoRA) set host http://127.0.0.1Utilizamos el conjunto de datos Stanford Alpaca como una demostración, los datos al igual que a continuación:
[{ "instruction" : " " , "input" : " " , "output" : }, { ... }](mLoRA) file upload
? file type: train data
? name: alpaca
? file path: /home/yezhengmao/alpaca-lora/alpaca_data.jsonLa plantilla en un archivo YAML, y escriba mediante la plantilla del lenguaje Jinja2, consulte el archivo Demo/Proltic.yaml
El archivo de datos que carga puede considerarse como datos de matriz, con los elementos en la matriz de tipo de diccionario. Consideramos cada elemento como un punto de datos en la plantilla.
(mLoRA) file upload
? file type: prompt template
? name: simple_prompt
? file path: /home/yezhengmao/mLoRA/demo/prompt.yaml Creamos un conjunto de datos, el conjunto de datos consiste en datos, una plantilla y el aportador correspondiente. Podemos usar el comando dataset showcase para verificar si las indicaciones se generan correctamente.
(mLoRA) dataset create
? name: alpaca_dataset
? train data file: alpaca
? prompt template file: simple_prompt
? prompter: instruction
? data preprocessing: default
(mLoRA) dataset showcase
? dataset name: alpaca_dataset Ahora podemos usar el comando adapter create para crear un adaptador para el tren.
Finalmente, podemos enviar la tarea para entrenar nuestro adaptador utilizando el conjunto de datos definidos. Nota: Puede enviar continuamente o Tareas de capacitación terminal. Use el adapter ls o task ls para verificar el estado de las tareas
El uso de MLORA puede guardar recursos computacionales y de memoria significativos al capacitar a múltiples adaptadores simultáneamente.
Atentamos múltiples adaptadores de Lora utilizando cuatro tarjetas gráficas A6000 con precisión FP32 y sin usar puntos de control y ninguna técnica de cuantización:
| Modelo | Mlora (tokens/s) | Peft-Lora con FSDP (tokens/s) | Peft-Lora con TP (tokens/s) |
|---|---|---|---|
| LLAMA-2-7B (32FP) | 2364 | 1750 | 1500 |
| LLAMA-2-13B (32FP) | 1280 | Oom | 875 |
| Modelo | |
|---|---|
| ✓ | Llama |
| Variante | |
|---|---|
| ✓ | Qlora, NIPS, 2023 |
| ✓ | Lora+, ICML, 2024 |
| ✓ | Vera, ICLR, 2024 |
| ✓ | Dora, ICML, 2024 |
| Variante | |
|---|---|
| ✓ | DPO, Neurips, 2024 |
| ✓ | CPO, ICML, 2024 |
| ✓ | CIT, ARXIV, 2024 |
¡Agradecemos contribuciones para mejorar este repositorio! Revise las pautas de contribución antes de enviar solicitudes o problemas de extracción.
Bifurca el repositorio. Cree una nueva rama para su característica o solución. Envíe una solicitud de extracción con una explicación detallada de sus cambios.
Puede usar el pre-Commit para verificar su código.
# Install requirements
pip install .[ci_test]
ln -s ../../.github/workflows/pre-commit .git/hooks/pre-commitO simplemente llame al script para verificar su código
.github/workflows/pre-commitCite el repositorio si usa el código en este repositorio.
@misc { m-LoRA ,
author = { Zhengmao, Yetextsuperscript{*} and Dengchun, Litextsuperscript{*} and Jingqi, Tian and Tingfeng, Lan and Yanbo, Liang and Yexi, Jiang and Jie, Zuo and Hui, Lu and Lei, Duan and Mingjie, Tang } ,
title = { m-LoRA: Efficient LLM Model Fine-tune and Inference via Multi-Lora Optimization } ,
year = { 2023 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/TUDB-Labs/mLoRA} } ,
note = { textsuperscript{*}: these authors contributed equally to this work. }
}Copyright © 2024 Todos los derechos reservados.
Este proyecto tiene licencia bajo la licencia Apache 2.0.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


