mLoRA
1.0.0
Mlora
"مصنع" فعال لبناء محولات Lora متعددة

Mlora (AKA Multi-Lora Fine-Tune) هو إطار عمل مفتوح المصدر مصمم لضبط فعال من نماذج لغة كبيرة متعددة (LLMs) باستخدام LORA ومتغيراتها. تتضمن الميزات الرئيسية لـ Mlora:
صقل متزامن لمحولات Lora متعددة.
نموذج قاعدة مشتركة بين محولات Lora متعددة.
خوارزمية التوازي الفعالة لخط الأنابيب.
دعم لخوارزميات متغيرة متعددة Lora ونماذج أساسية مختلفة.
دعم لخوارزميات محاذاة تفضيلات التعلم المتعددة.
يوضح الشكل البنية من طرف إلى طرف من Mora في الشكل:
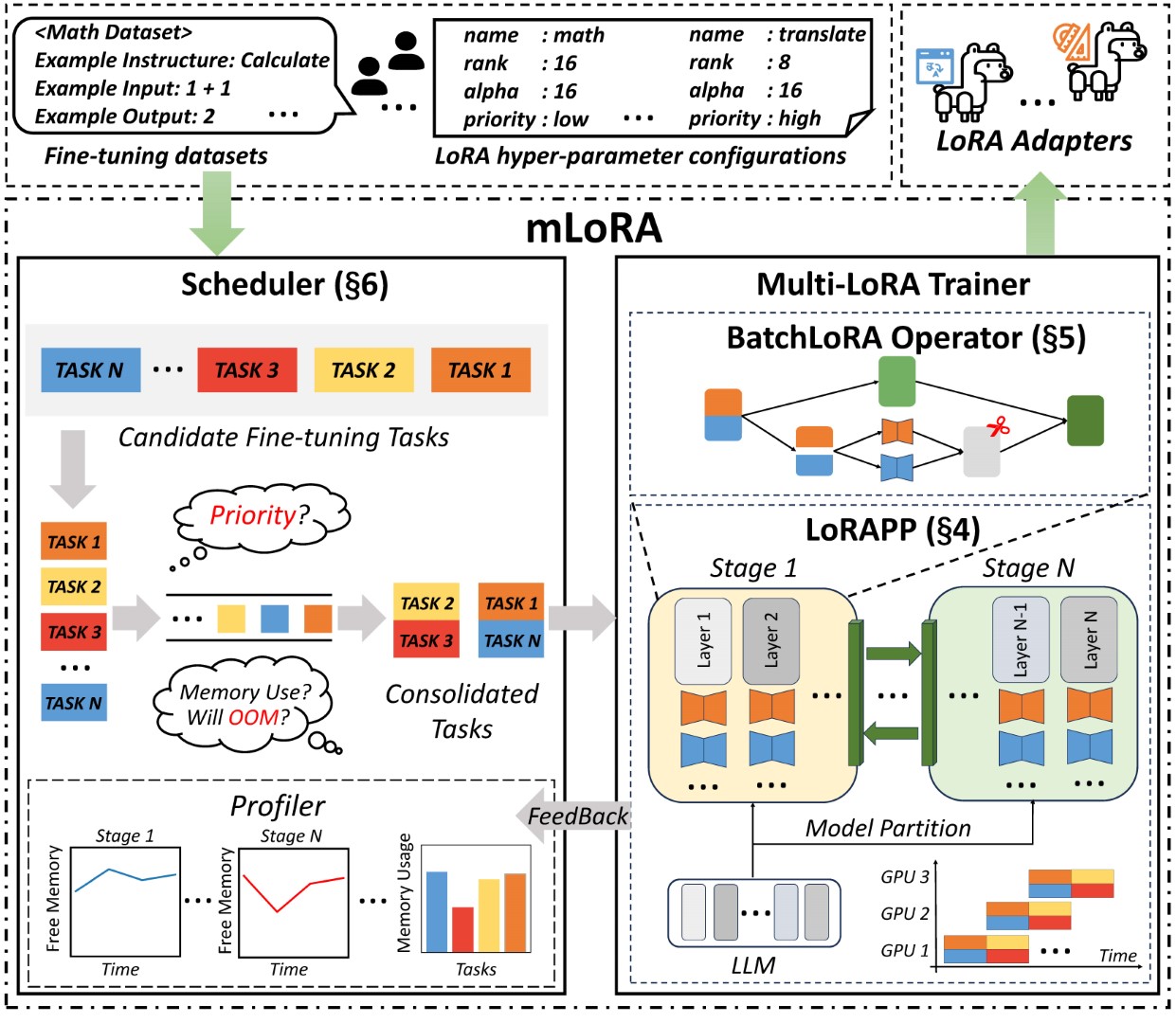
أولاً ، يجب عليك استنساخ هذا المستودع وتثبيت التبعيات (أو استخدام صورتنا):
# Clone Repository
git clone https://github.com/TUDB-Labs/mLoRA
cd mLoRA
# Install requirements need the Python >= 3.12
pip install . رمز mlora_train.py هو نقطة انطلاق لمحولات Lora الدفعة.
python mlora_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yamlيمكنك التحقق من تكوين المحولات في المجلد التجريبي ، وهناك بعض التكوين فيما يتعلق باستخدام متغيرات LORA المختلفة وخوارزميات محاذاة تفضيلات التعلم التعزيز.
لمزيد من معلومات الاستخدام التفصيلية ، يرجى الاستخدام --help -الخيار:
python mlora_train.py --helpعلى غرار QuickStart ، فإن الأمر الذي يبدأ في بيئة عقدة ثنائية هو كما يلي:
ملاحظة 1: استخدم متغيرات البيئة MASTER_ADDR/MASTER_PORT لتعيين العقدة الرئيسية.
ملاحظة 2: حدد الرصيد ، مما يشير إلى عدد طبقات فك التشفير المخصصة لكل رتبة.
# in the first node
export MASTER_ADDR=master.svc.cluster.local
export MASTER_PORT=12355
python mlora_pp_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yaml
--pipeline
--device " cuda:0 "
--rank 0
--balance 12 13
--no-recompute
--precision fp32
# in the second node
export MASTER_ADDR=master.svc.cluster.local
export MASTER_PORT=12355
python mlora_pp_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yaml
--pipeline
--device " cuda:1 "
--rank 1
--balance 12 13
--no-recompute
--precision fp32تقدم Mlora صورة Docker الرسمية للبدء السريع والتطوير ، وتتوفر الصورة في سجل حزم DockerHub.
أولاً ، يجب عليك سحب أحدث صورة (تستخدم الصورة أيضًا للتطوير):
docker pull yezhengmaolove/mlora:latestنشر وأدخل حاوية لتشغيل Mlora:
docker run -itd --runtime nvidia --gpus all
-v ~ /your_dataset_dir:/dataset
-v ~ /your_model_dir:/model
-p < host_port > :22
--name mlora
yezhengmaolove/mlora:latest
# when the container started, use the ssh to login
# the default password is mlora@123
ssh root@localhost -p < host_port >
# pull the latest code and run the mlora
cd /mLoRA
git pull
python mlora_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yamlيمكننا نشر Mloar كخدمة لتلقي طلبات المستخدم بشكل مستمر وإجراء مهمة صقل.
أولاً ، يجب عليك سحب أحدث صورة (استخدم نفس الصورة للنشر):
docker pull yezhengmaolove/mlora:latestنشر خادم Mlora الخاص بنا:
docker run -itd --runtime nvidia --gpus all
-v ~ /your_dataset_cache_dir:/cache
-v ~ /your_model_dir:/model
-p < host_port > :8000
--name mlora_server
-e " BASE_MODEL=TinyLlama/TinyLlama-1.1B-Chat-v0.4 "
-e " STORAGE_DIR=/cache "
yezhengmaolove/mlora:latest /bin/bash /opt/deploy.sh بمجرد نشر الخدمة ، قم بتثبيت واستخدام mlora_cli.py للتفاعل مع الخادم.
# install the client tools
pip install mlora-cli
# use the mlora cli tool to connect to mlora server
mlora_cli
(mLoRA) set port < host_port >
(mLoRA) set host http:// < host_ip >
# and enjoy it!!docker pull yezhengmaolove/mlora:latest
pip install mlora-cli # first, we create a cache dir in host for cache some file
mkdir ~ /cache
# second, we manually download the model weights from Hugging Face.
mkdir ~ /model && cd ~ /model
git clone https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0
# we map port 8000 used by the mlora server to port 1288 on the host machine.
# the BASE_MODEL environment variable indicates the path of the base model used by mlora.
# the STORAGE_DIR environment variable indicates the path where datasets and lora adapters are stored.
# we use the script /opt/deploy.sh in container to start the server.
docker run -itd --runtime nvidia --gpus all
-v ~ /cache:/cache
-v ~ /model:/model
-p 1288:8000
--name mlora_server
-e " BASE_MODEL=/model/TinyLlama-1.1B-Chat-v1.0 "
-e " STORAGE_DIR=/cache "
yezhengmaolove/mlora:latest /bin/bash /opt/deploy.shنستخدم رابط mlora_cli للخادم http://127.0.0.1:1288 (يجب استخدام protocal HTTP)
(mLoRA) set port 1288
(mLoRA) set host http://127.0.0.1نستخدم مجموعة بيانات Stanford Alpaca كعرض تجريبي ، كما هو الحال أدناه:
[{ "instruction" : " " , "input" : " " , "output" : }, { ... }](mLoRA) file upload
? file type: train data
? name: alpaca
? file path: /home/yezhengmao/alpaca-lora/alpaca_data.jsonالقالب في ملف yaml ، واكتب عن طريق ترتيب اللغة Jinja2 ، راجع ملف التوضيح/orger.yaml
يمكن اعتبار ملف البيانات الذي تقوم بتحميله كبيانات صفيف ، حيث تكون العناصر الموجودة في الصفيف من نوع القاموس. نحن نعتبر كل عنصر نقطة بيانات في القالب.
(mLoRA) file upload
? file type: prompt template
? name: simple_prompt
? file path: /home/yezhengmao/mLoRA/demo/prompt.yaml نقوم بإنشاء مجموعة بيانات ، وتتكون مجموعة البيانات من البيانات والقالب والمحضر المقابل. يمكننا استخدام أمر dataset showcase للتحقق مما إذا تم إنشاء المطالبات بشكل صحيح.
(mLoRA) dataset create
? name: alpaca_dataset
? train data file: alpaca
? prompt template file: simple_prompt
? prompter: instruction
? data preprocessing: default
(mLoRA) dataset showcase
? dataset name: alpaca_dataset الآن يمكننا استخدام أمر adapter create لإنشاء محول للقطار.
أخيرًا ، يمكننا تقديم المهمة لتدريب محولنا باستخدام مجموعة البيانات المحددة. ملاحظة: يمكنك تقديم مهام التدريب الطرفية بشكل مستمر. استخدم adapter ls أو task ls للتحقق من حالة المهام
يمكن أن يؤدي استخدام MLORA إلى توفير موارد حسابية وذاكرة كبيرة عند تدريب محولات متعددة في وقت واحد.
قمنا بصنع محولات LORA متعددة باستخدام أربع بطاقات رسومات A6000 مع دقة FP32 وبدون استخدام تحديد الفحص وأي تقنيات القياس الكمي:
| نموذج | Mlora (الرموز/s) | PEFT-LORA مع FSDP (الرموز/S) | peft-lora مع TP (الرموز/s) |
|---|---|---|---|
| Llama-2-7b (32FP) | 2364 | 1750 | 1500 |
| Llama-2-13b (32FP) | 1280 | أووم | 875 |
| نموذج | |
|---|---|
| ✓ | لاما |
| البديل | |
|---|---|
| ✓ | Qlora ، Nips ، 2023 |
| ✓ | Lora+، ICML ، 2024 |
| ✓ | Vera ، ICLR ، 2024 |
| ✓ | درة ، ICML ، 2024 |
| البديل | |
|---|---|
| ✓ | DPO ، Neups ، 2024 |
| ✓ | CPO ، ICML ، 2024 |
| ✓ | CIT ، Arxiv ، 2024 |
نرحب بالمساهمات لتحسين هذا المستودع! يرجى مراجعة إرشادات المساهمة قبل تقديم طلبات السحب أو المشكلات.
شوكة المستودع. قم بإنشاء فرع جديد للميزة أو الإصلاح. إرسال طلب سحب مع شرح مفصل للتغييرات الخاصة بك.
يمكنك استخدام اللبلاب المسبق للتحقق من الرمز الخاص بك.
# Install requirements
pip install .[ci_test]
ln -s ../../.github/workflows/pre-commit .git/hooks/pre-commitأو فقط اتصل بالبرنامج النصي للتحقق من الكود الخاص بك
.github/workflows/pre-commitيرجى الاستشهاد بالربط إذا كنت تستخدم الرمز في هذا الريبو.
@misc { m-LoRA ,
author = { Zhengmao, Yetextsuperscript{*} and Dengchun, Litextsuperscript{*} and Jingqi, Tian and Tingfeng, Lan and Yanbo, Liang and Yexi, Jiang and Jie, Zuo and Hui, Lu and Lei, Duan and Mingjie, Tang } ,
title = { m-LoRA: Efficient LLM Model Fine-tune and Inference via Multi-Lora Optimization } ,
year = { 2023 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/TUDB-Labs/mLoRA} } ,
note = { textsuperscript{*}: these authors contributed equally to this work. }
}حقوق الطبع والنشر © 2024 جميع الحقوق محفوظة.
هذا المشروع مرخص بموجب ترخيص Apache 2.0.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


