mLoRA
1.0.0
Мор
Эффективная «фабрика» для построения нескольких адаптеров LORA

Mlora (он же Multi-Lora Fine-Tune)-это рамка с открытым исходным кодом, предназначенную для эффективной тонкой настройки нескольких крупных языковых моделей (LLMS) с использованием LORA и ее вариантов. Ключевые особенности Mlora включают:
Одновременная тонкая настройка нескольких адаптеров Lora.
Общая базовая модель среди нескольких адаптеров LORA.
Эффективный алгоритм параллелизма трубопровода.
Поддержка множества алгоритмов варианта LORA и различных базовых моделей.
Поддержка множественных алгоритмов выравнивания предпочтений обучения.
Сквозная архитектура mlora показана на рисунке:
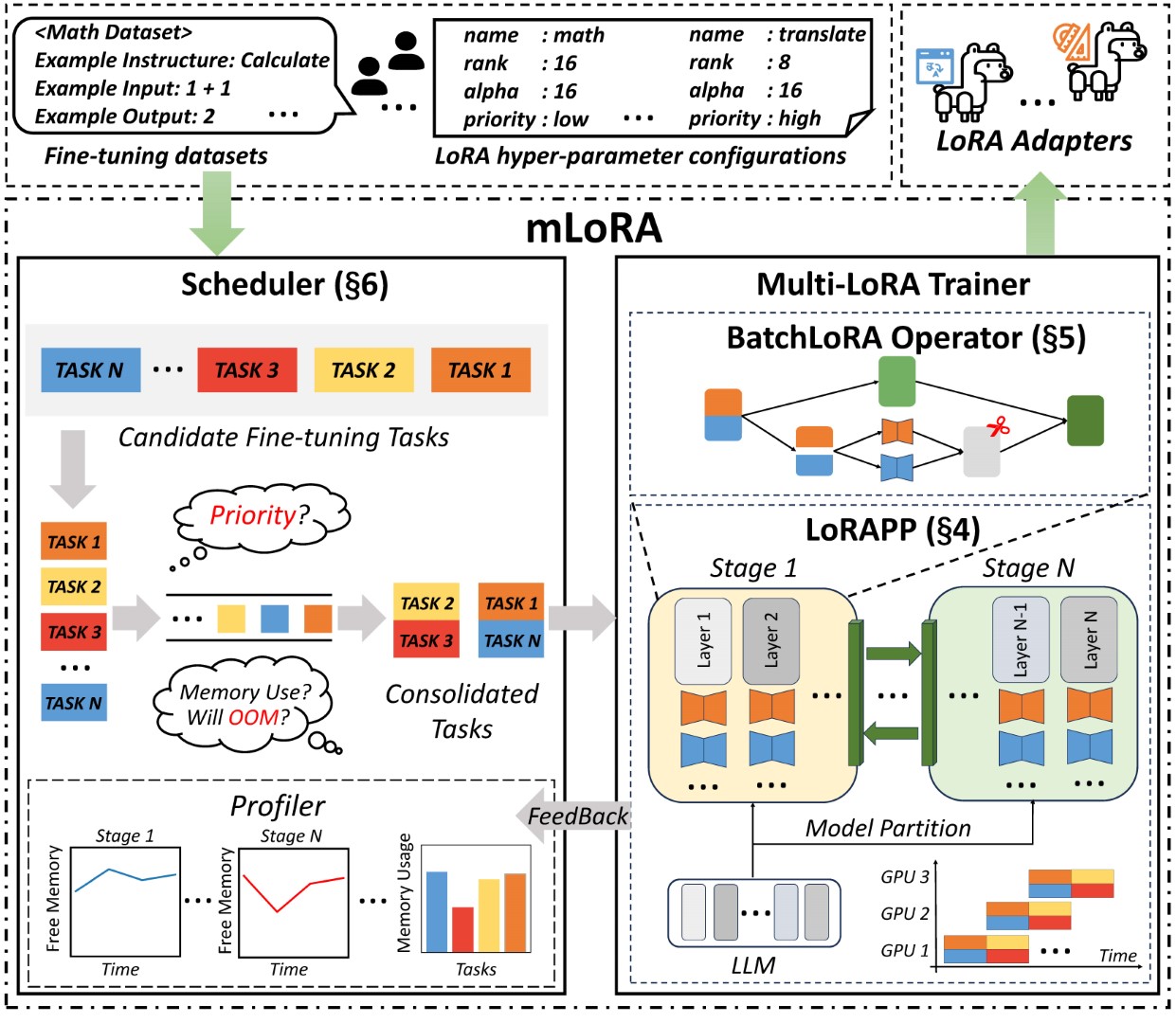
Во -первых, вы должны клонировать этот репозиторий и установить зависимости (или использовать наше изображение):
# Clone Repository
git clone https://github.com/TUDB-Labs/mLoRA
cd mLoRA
# Install requirements need the Python >= 3.12
pip install . Код mlora_train.py является отправной точкой для пакетной точной настройки адаптеров Lora.
python mlora_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yamlВы можете проверить конфигурацию адаптеров в демонстрационной папке, существует некоторая конфигурация в отношении использования различных вариантов LORA и алгоритмов выравнивания выравнивания обучения LORA.
Для получения дополнительной подробной информации об использовании, пожалуйста, используйте --help вариант:
python mlora_train.py --helpПодобно QuickStart, команда для начала в среде с двумя узлами выглядит следующим образом:
ПРИМЕЧАНИЕ1: Используйте переменные среды MASTER_ADDR/MASTER_PORT чтобы установить мастер -узл.
ПРИМЕЧАНИЕ2: Установите баланс, указывающий на количество слоев декодера, выделенных для каждого ранга.
# in the first node
export MASTER_ADDR=master.svc.cluster.local
export MASTER_PORT=12355
python mlora_pp_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yaml
--pipeline
--device " cuda:0 "
--rank 0
--balance 12 13
--no-recompute
--precision fp32
# in the second node
export MASTER_ADDR=master.svc.cluster.local
export MASTER_PORT=12355
python mlora_pp_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yaml
--pipeline
--device " cuda:1 "
--rank 1
--balance 12 13
--no-recompute
--precision fp32Mlora предлагает официальное изображение Docker для быстрого запуска и разработки, изображение доступно в реестре пакетов Dockerhub.
Во -первых, вы должны вытащить новейшее изображение (изображение также используется для разработки):
docker pull yezhengmaolove/mlora:latestРазвернуть и введите контейнер для запуска Mlora:
docker run -itd --runtime nvidia --gpus all
-v ~ /your_dataset_dir:/dataset
-v ~ /your_model_dir:/model
-p < host_port > :22
--name mlora
yezhengmaolove/mlora:latest
# when the container started, use the ssh to login
# the default password is mlora@123
ssh root@localhost -p < host_port >
# pull the latest code and run the mlora
cd /mLoRA
git pull
python mlora_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yamlМы можем развернуть MLOAR в качестве службы для постоянного получения запросов пользователей и выполнения задачи с точной настройкой.
Во -первых, вы должны вытащить последнее изображение (используйте то же изображение для развертывания):
docker pull yezhengmaolove/mlora:latestРазвернуть наш сервер MORA:
docker run -itd --runtime nvidia --gpus all
-v ~ /your_dataset_cache_dir:/cache
-v ~ /your_model_dir:/model
-p < host_port > :8000
--name mlora_server
-e " BASE_MODEL=TinyLlama/TinyLlama-1.1B-Chat-v0.4 "
-e " STORAGE_DIR=/cache "
yezhengmaolove/mlora:latest /bin/bash /opt/deploy.sh После того, как служба будет развернута, установите и используйте mlora_cli.py для взаимодействия с сервером.
# install the client tools
pip install mlora-cli
# use the mlora cli tool to connect to mlora server
mlora_cli
(mLoRA) set port < host_port >
(mLoRA) set host http:// < host_ip >
# and enjoy it!!docker pull yezhengmaolove/mlora:latest
pip install mlora-cli # first, we create a cache dir in host for cache some file
mkdir ~ /cache
# second, we manually download the model weights from Hugging Face.
mkdir ~ /model && cd ~ /model
git clone https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0
# we map port 8000 used by the mlora server to port 1288 on the host machine.
# the BASE_MODEL environment variable indicates the path of the base model used by mlora.
# the STORAGE_DIR environment variable indicates the path where datasets and lora adapters are stored.
# we use the script /opt/deploy.sh in container to start the server.
docker run -itd --runtime nvidia --gpus all
-v ~ /cache:/cache
-v ~ /model:/model
-p 1288:8000
--name mlora_server
-e " BASE_MODEL=/model/TinyLlama-1.1B-Chat-v1.0 "
-e " STORAGE_DIR=/cache "
yezhengmaolove/mlora:latest /bin/bash /opt/deploy.shМы используем ссылку mora_cli на сервер http://127.0.0.1:1288 (необходимо использовать протокал HTTP)
(mLoRA) set port 1288
(mLoRA) set host http://127.0.0.1Мы используем набор данных Стэнфордской альпаки в качестве демонстрации, данные, как и ниже:
[{ "instruction" : " " , "input" : " " , "output" : }, { ... }](mLoRA) file upload
? file type: train data
? name: alpaca
? file path: /home/yezhengmao/alpaca-lora/alpaca_data.jsonШаблон в файле YAML и написать путем шаблона языка jinja2, см. Файл Demo/raffit.yaml
Файл данных, который вы загружаете, можно рассматривать как данные массива, при этом элементы в массиве имеют словаря. Мы рассматриваем каждый элемент как точку данных в шаблоне.
(mLoRA) file upload
? file type: prompt template
? name: simple_prompt
? file path: /home/yezhengmao/mLoRA/demo/prompt.yaml Мы создаем набор данных, набор данных состоит из данных, шаблона и соответствующего проживания. Мы можем использовать команду dataset showcase , чтобы проверить, правильно ли созданы подсказки.
(mLoRA) dataset create
? name: alpaca_dataset
? train data file: alpaca
? prompt template file: simple_prompt
? prompter: instruction
? data preprocessing: default
(mLoRA) dataset showcase
? dataset name: alpaca_dataset Теперь мы можем использовать команду adapter create для создания адаптера для поезда.
Наконец, мы можем отправить задачу для обучения нашего адаптера, используя определенный набор данных. Примечание. Вы можете постоянно отправлять или тренировать терминальные задачи. Используйте adapter ls или task ls чтобы проверить статус задач
Использование Mlora может сохранить значительные вычислительные ресурсы и ресурсы памяти при одновременном обучении нескольких адаптеров.
Мы точно настроили несколько адаптеров LORA, используя четыре графические карты A6000 с точностью FP32 и без использования контрольно-пропускной пункты и любых методов квантования:
| Модель | МОРА (токены/с) | Пефт-лора с FSDP (токены/с) | Peft-Lora с TP (токены/с) |
|---|---|---|---|
| лама-2-7B (32FP) | 2364 | 1750 | 1500 |
| Llama-2-13b (32FP) | 1280 | Непрерывно | 875 |
| Модель | |
|---|---|
| ✓ | Лама |
| Вариант | |
|---|---|
| ✓ | Qlora, Nips, 2023 |
| ✓ | Лора+, ICML, 2024 |
| ✓ | Вера, ICLR, 2024 |
| ✓ | Дора, ICML, 2024 |
| Вариант | |
|---|---|
| ✓ | DPO, Neurips, 2024 |
| ✓ | CPO, ICML, 2024 |
| ✓ | Cit, Arxiv, 2024 |
Мы приветствуем вклад в улучшение этого репозитория! Пожалуйста, ознакомьтесь с руководящими принципами взноса перед отправкой запросов или проблем.
Вилка репозитория. Создайте новую ветку для вашей функции или исправления. Отправьте запрос на привлечение с подробным объяснением ваших изменений.
Вы можете использовать предварительную компанию для проверки вашего кода.
# Install requirements
pip install .[ci_test]
ln -s ../../.github/workflows/pre-commit .git/hooks/pre-commitИли просто позвоните в сценарий, чтобы проверить свой код
.github/workflows/pre-commitПожалуйста, цитируйте репо, если вы используете код в этом репо.
@misc { m-LoRA ,
author = { Zhengmao, Yetextsuperscript{*} and Dengchun, Litextsuperscript{*} and Jingqi, Tian and Tingfeng, Lan and Yanbo, Liang and Yexi, Jiang and Jie, Zuo and Hui, Lu and Lei, Duan and Mingjie, Tang } ,
title = { m-LoRA: Efficient LLM Model Fine-tune and Inference via Multi-Lora Optimization } ,
year = { 2023 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/TUDB-Labs/mLoRA} } ,
note = { textsuperscript{*}: these authors contributed equally to this work. }
}Copyright © 2024 Все права защищены.
Этот проект лицензирован по лицензии Apache 2.0.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


