mLoRA
1.0.0
Mlora
Eine effiziente "Fabrik", um mehrere Lora -Adapter zu bauen

Mlora (auch bekannt als Multi-Lora-Fein-Tune) ist ein Open-Source-Framework, das für die effiziente Feinabstimmung mehrerer großer Sprachmodelle (LLMs) unter Verwendung von LORA und seinen Varianten entwickelt wurde. Zu den wichtigsten Merkmalen von Mlora gehören:
Gleichzeitige Feinabstimmung mehrerer Lora-Adapter.
Gemeinsames Basismodell unter mehreren Lora -Adaptern.
Effizienter Pipeline Parallelismus -Algorithmus.
Unterstützung für mehrere LORA -Variantenalgorithmen und verschiedene Basismodelle.
Unterstützung für Algorithmen für Verstärkungslernausrichtungsausrichtungen.
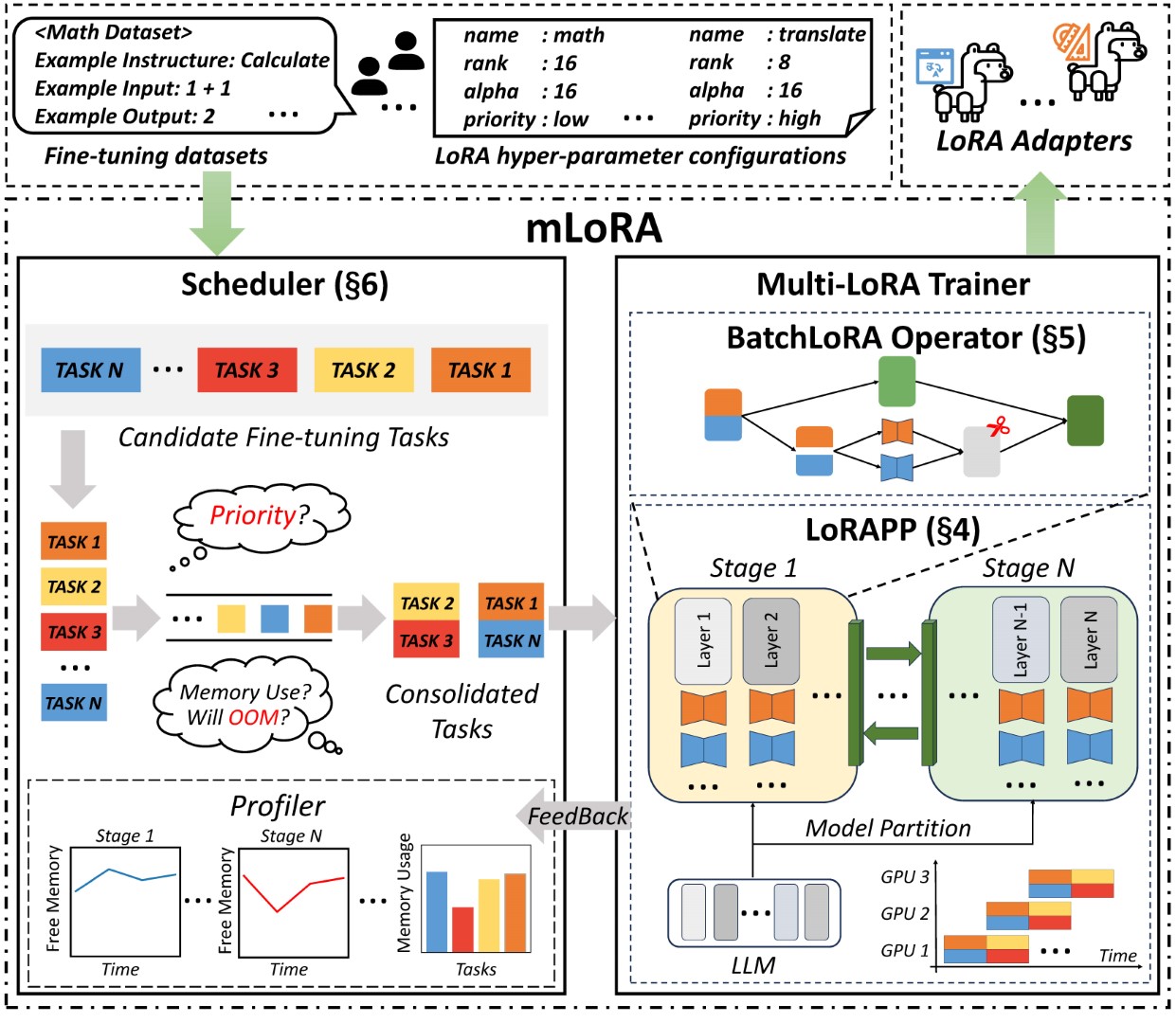
Die End-to-End-Architektur der Mlora ist in der Abbildung dargestellt:
Zunächst sollten Sie dieses Repository klonen und Abhängigkeiten installieren (oder unser Bild verwenden):
# Clone Repository
git clone https://github.com/TUDB-Labs/mLoRA
cd mLoRA
# Install requirements need the Python >= 3.12
pip install . Der Code mlora_train.py ist ein Ausgangspunkt für die Batch-Feinabstimmung von Lora-Adaptern.
python mlora_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yamlSie können die Konfiguration der Adapter im Demo -Ordner überprüfen. Es gibt eine gewisse Konfiguration in Bezug auf die Verwendung verschiedener LORA -Varianten und Verstärkungs -Lernpräferenz -Alignment -Algorithmen.
Für weitere detaillierte Nutzungsinformationen verwenden Sie bitte die Option --help : HELP:
python mlora_train.py --helpÄhnlich wie bei QuickStart lautet der Befehl, in einer Zwei-Knoten-Umgebung zu beginnen, wie folgt:
Hinweis 1: Verwenden Sie Umgebungsvariablen MASTER_ADDR/MASTER_PORT um den Masterknoten festzulegen.
Hinweis 2: Setzen Sie den Gleichgewicht und geben Sie die Anzahl der Decoderebenen an, die jedem Rang zugewiesen wurden.
# in the first node
export MASTER_ADDR=master.svc.cluster.local
export MASTER_PORT=12355
python mlora_pp_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yaml
--pipeline
--device " cuda:0 "
--rank 0
--balance 12 13
--no-recompute
--precision fp32
# in the second node
export MASTER_ADDR=master.svc.cluster.local
export MASTER_PORT=12355
python mlora_pp_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yaml
--pipeline
--device " cuda:1 "
--rank 1
--balance 12 13
--no-recompute
--precision fp32Mlora bietet ein offizielles Docker -Image für schnelle Start und Entwicklung. Das Bild ist in der Registrierung von DockerHub -Paketen verfügbar.
Zunächst sollten Sie das neueste Bild ziehen (das Bild auch für die Entwicklung verwendet):
docker pull yezhengmaolove/mlora:latestBereitstellen und geben Sie einen Container ein und geben Sie einen Container ein, um Mlora auszuführen:
docker run -itd --runtime nvidia --gpus all
-v ~ /your_dataset_dir:/dataset
-v ~ /your_model_dir:/model
-p < host_port > :22
--name mlora
yezhengmaolove/mlora:latest
# when the container started, use the ssh to login
# the default password is mlora@123
ssh root@localhost -p < host_port >
# pull the latest code and run the mlora
cd /mLoRA
git pull
python mlora_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yamlWir können MLOAR als Dienst bereitstellen, um Benutzeranfragen kontinuierlich zu empfangen und eine Feinabstimmungsaufgabe auszuführen.
Zunächst sollten Sie das neueste Bild abrufen (verwenden Sie das gleiche Bild für die Bereitstellung):
docker pull yezhengmaolove/mlora:latestStellen Sie unseren Mlora -Server ein:
docker run -itd --runtime nvidia --gpus all
-v ~ /your_dataset_cache_dir:/cache
-v ~ /your_model_dir:/model
-p < host_port > :8000
--name mlora_server
-e " BASE_MODEL=TinyLlama/TinyLlama-1.1B-Chat-v0.4 "
-e " STORAGE_DIR=/cache "
yezhengmaolove/mlora:latest /bin/bash /opt/deploy.sh Sobald der Dienst bereitgestellt wurde, installieren Sie und verwenden Sie mlora_cli.py , um mit dem Server zu interagieren.
# install the client tools
pip install mlora-cli
# use the mlora cli tool to connect to mlora server
mlora_cli
(mLoRA) set port < host_port >
(mLoRA) set host http:// < host_ip >
# and enjoy it!!docker pull yezhengmaolove/mlora:latest
pip install mlora-cli # first, we create a cache dir in host for cache some file
mkdir ~ /cache
# second, we manually download the model weights from Hugging Face.
mkdir ~ /model && cd ~ /model
git clone https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0
# we map port 8000 used by the mlora server to port 1288 on the host machine.
# the BASE_MODEL environment variable indicates the path of the base model used by mlora.
# the STORAGE_DIR environment variable indicates the path where datasets and lora adapters are stored.
# we use the script /opt/deploy.sh in container to start the server.
docker run -itd --runtime nvidia --gpus all
-v ~ /cache:/cache
-v ~ /model:/model
-p 1288:8000
--name mlora_server
-e " BASE_MODEL=/model/TinyLlama-1.1B-Chat-v1.0 "
-e " STORAGE_DIR=/cache "
yezhengmaolove/mlora:latest /bin/bash /opt/deploy.shWir verwenden den Link Mlora_Cli zum Server http://127.0.0.1:1288 (muss den HTTP -Protokal verwenden)
(mLoRA) set port 1288
(mLoRA) set host http://127.0.0.1Wir verwenden den Stanford Alpaca -Datensatz als Demo, die Daten genau wie unten:
[{ "instruction" : " " , "input" : " " , "output" : }, { ... }](mLoRA) file upload
? file type: train data
? name: alpaca
? file path: /home/yezhengmao/alpaca-lora/alpaca_data.jsonDie Vorlage in einer YAML -Datei und schreibe per Templating Language Jinja2 siehe die Datei deMo/prompt.yaml
Die von Ihnen hochgeladene Datendatei kann als Array -Daten betrachtet werden, wobei die Elemente im Array vom Wörterbuchtyp sind. Wir betrachten jedes Element als Datenpunkt in der Vorlage.
(mLoRA) file upload
? file type: prompt template
? name: simple_prompt
? file path: /home/yezhengmao/mLoRA/demo/prompt.yaml Wir erstellen einen Datensatz, der Datensatz besteht aus Daten, einer Vorlage und dem entsprechenden PromPter. Wir können den Befehl dataset showcase verwenden, um die Anweisungen zu überprüfen, die korrekt generiert werden.
(mLoRA) dataset create
? name: alpaca_dataset
? train data file: alpaca
? prompt template file: simple_prompt
? prompter: instruction
? data preprocessing: default
(mLoRA) dataset showcase
? dataset name: alpaca_dataset Jetzt können wir den Befehl adapter create verwenden, um einen Adapter für den Zug zu erstellen.
Schließlich können wir die Aufgabe einreichen, um unseren Adapter mit dem definierten Datensatz zu trainieren. HINWEIS: Sie können kontinuierliche Schulungsaufgaben einreichen oder terminalen. Verwenden Sie den adapter ls oder task ls um den Status der Aufgaben zu überprüfen
Die Verwendung von Mlora kann bei der gleichzeitigen Schulung mehrerer Adapter erhebliche Rechen- und Speicherressourcen sparen.
Wir haben mehrere LORA-Adapter mit vier A6000-Grafikkarten mit FP32-Präzision und ohne Checkpointing und alle Quantisierungstechniken abgestimmt:
| Modell | Mlora (Token/s) | Peft-Lora mit FSDP (Token/s) | Peft-Lora mit TP (Token/s) |
|---|---|---|---|
| LAMA-2-7B (32FP) | 2364 | 1750 | 1500 |
| LAMA-2-13B (32FP) | 1280 | Oom | 875 |
| Modell | |
|---|---|
| ✓ | Lama |
| Variante | |
|---|---|
| ✓ | Qlora, Nips, 2023 |
| ✓ | Lora+, ICML, 2024 |
| ✓ | Vera, ICLR, 2024 |
| ✓ | Dora, ICML, 2024 |
| Variante | |
|---|---|
| ✓ | DPO, Neurips, 2024 |
| ✓ | CPO, ICML, 2024 |
| ✓ | CIT, Arxiv, 2024 |
Wir begrüßen Beiträge, um dieses Repository zu verbessern! Bitte überprüfen Sie die Beitragsrichtlinien, bevor Sie Pull -Anfragen oder -fragen einreichen.
Geben Sie das Repository auf. Erstellen Sie eine neue Filiale für Ihre Funktion oder Ihr Fix. Senden Sie eine Pull -Anfrage mit einer detaillierten Erklärung Ihrer Änderungen.
Sie können den Vorkommit verwenden, um Ihren Code zu überprüfen.
# Install requirements
pip install .[ci_test]
ln -s ../../.github/workflows/pre-commit .git/hooks/pre-commitOder rufen Sie einfach das Skript an, um Ihren Code zu überprüfen
.github/workflows/pre-commitBitte zitieren Sie das Repo, wenn Sie den Code in diesem Repo verwenden.
@misc { m-LoRA ,
author = { Zhengmao, Yetextsuperscript{*} and Dengchun, Litextsuperscript{*} and Jingqi, Tian and Tingfeng, Lan and Yanbo, Liang and Yexi, Jiang and Jie, Zuo and Hui, Lu and Lei, Duan and Mingjie, Tang } ,
title = { m-LoRA: Efficient LLM Model Fine-tune and Inference via Multi-Lora Optimization } ,
year = { 2023 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/TUDB-Labs/mLoRA} } ,
note = { textsuperscript{*}: these authors contributed equally to this work. }
}Copyright © 2024 Alle Rechte vorbehalten.
Dieses Projekt ist unter der Apache 2.0 -Lizenz lizenziert.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


