mLoRA
1.0.0
mlora
Une "usine" efficace pour construire plusieurs adaptateurs LORA

MLORA (aka multi-lora aned-tune) est un cadre open source conçu pour un réglage fin efficace de plusieurs modèles de langues (LLM) en utilisant LORA et ses variantes. Les principales caractéristiques de la mlora comprennent:
Fonctionment simultané de plusieurs adaptateurs LORA.
Modèle de base partagé entre plusieurs adaptateurs LORA.
Algorithme de parallélisme de pipeline efficace.
Prise en charge de plusieurs algorithmes de variants LORA et de divers modèles de base.
Prise en charge des algorithmes d'alignement des préférences d'apprentissage multiples de renforcement.
L'architecture de bout en bout de la mlora est illustrée à la figure:
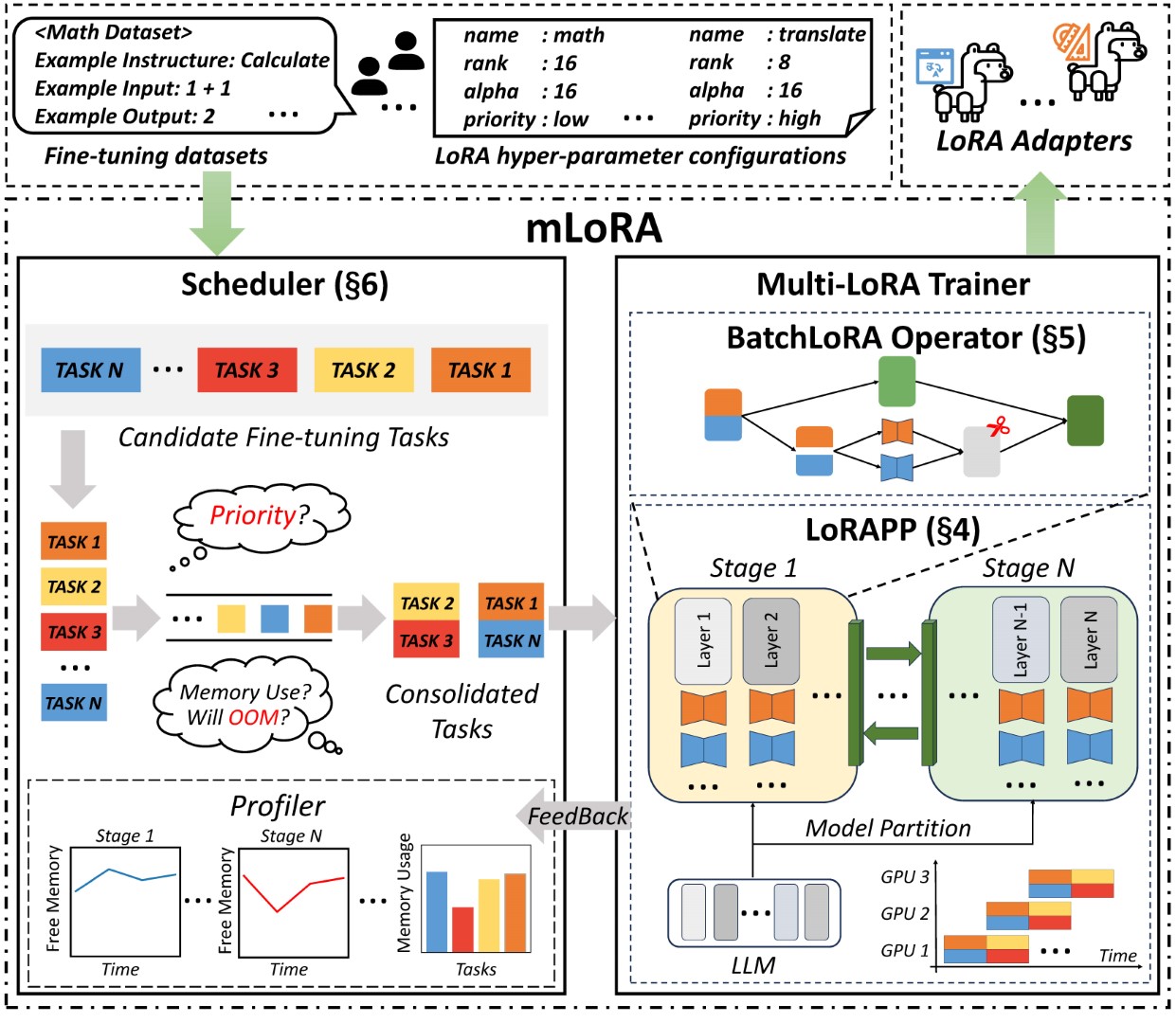
Tout d'abord, vous devez cloner ce référentiel et installer des dépendances (ou utiliser notre image):
# Clone Repository
git clone https://github.com/TUDB-Labs/mLoRA
cd mLoRA
# Install requirements need the Python >= 3.12
pip install . Le code mlora_train.py est un point de départ pour les adaptateurs LORA affinés par lots.
python mlora_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yamlVous pouvez vérifier la configuration des adaptateurs dans le dossier de démonstration, il existe une certaine configuration concernant l'utilisation de différentes variantes LORA et des algorithmes d'alignement de préférence d'apprentissage de renforcement.
Pour plus d'informations d'utilisation détaillées, veuillez utiliser --help Option-help:
python mlora_train.py --helpSemblable à QuickStart, la commande pour démarrer dans un environnement à deux nœuds est la suivante:
Remarque1: Utilisez des variables d'environnement MASTER_ADDR/MASTER_PORT pour définir le nœud maître.
Remarque2: Définissez l'équilibre, indiquant le nombre de couches de décodeur allouées à chaque rang.
# in the first node
export MASTER_ADDR=master.svc.cluster.local
export MASTER_PORT=12355
python mlora_pp_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yaml
--pipeline
--device " cuda:0 "
--rank 0
--balance 12 13
--no-recompute
--precision fp32
# in the second node
export MASTER_ADDR=master.svc.cluster.local
export MASTER_PORT=12355
python mlora_pp_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yaml
--pipeline
--device " cuda:1 "
--rank 1
--balance 12 13
--no-recompute
--precision fp32MLORA propose une image Docker officielle pour le démarrage et le développement rapides, l'image est disponible sur le registre DockerHub Packages.
Tout d'abord, vous devez extraire la dernière image (l'image utilise également pour le développement):
docker pull yezhengmaolove/mlora:latestDéployez et entrez un conteneur pour exécuter mlora:
docker run -itd --runtime nvidia --gpus all
-v ~ /your_dataset_dir:/dataset
-v ~ /your_model_dir:/model
-p < host_port > :22
--name mlora
yezhengmaolove/mlora:latest
# when the container started, use the ssh to login
# the default password is mlora@123
ssh root@localhost -p < host_port >
# pull the latest code and run the mlora
cd /mLoRA
git pull
python mlora_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yamlNous pouvons déployer Mloar en tant que service pour recevoir en continu les demandes des utilisateurs et effectuer une tâche de réglage fin.
Tout d'abord, vous devez extraire la dernière image (utilisez la même image pour le déploiement):
docker pull yezhengmaolove/mlora:latestDéployez notre serveur MLORA:
docker run -itd --runtime nvidia --gpus all
-v ~ /your_dataset_cache_dir:/cache
-v ~ /your_model_dir:/model
-p < host_port > :8000
--name mlora_server
-e " BASE_MODEL=TinyLlama/TinyLlama-1.1B-Chat-v0.4 "
-e " STORAGE_DIR=/cache "
yezhengmaolove/mlora:latest /bin/bash /opt/deploy.sh Une fois le service déployé, installez et utilisez mlora_cli.py pour interagir avec le serveur.
# install the client tools
pip install mlora-cli
# use the mlora cli tool to connect to mlora server
mlora_cli
(mLoRA) set port < host_port >
(mLoRA) set host http:// < host_ip >
# and enjoy it!!docker pull yezhengmaolove/mlora:latest
pip install mlora-cli # first, we create a cache dir in host for cache some file
mkdir ~ /cache
# second, we manually download the model weights from Hugging Face.
mkdir ~ /model && cd ~ /model
git clone https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0
# we map port 8000 used by the mlora server to port 1288 on the host machine.
# the BASE_MODEL environment variable indicates the path of the base model used by mlora.
# the STORAGE_DIR environment variable indicates the path where datasets and lora adapters are stored.
# we use the script /opt/deploy.sh in container to start the server.
docker run -itd --runtime nvidia --gpus all
-v ~ /cache:/cache
-v ~ /model:/model
-p 1288:8000
--name mlora_server
-e " BASE_MODEL=/model/TinyLlama-1.1B-Chat-v1.0 "
-e " STORAGE_DIR=/cache "
yezhengmaolove/mlora:latest /bin/bash /opt/deploy.shNous utilisons le lien mlora_cli vers le serveur http://127.0.0.1:1288 (Doit utiliser le protocal HTTP)
(mLoRA) set port 1288
(mLoRA) set host http://127.0.0.1Nous utilisons l'ensemble de données Alpaca Stanford comme démo, les données comme ci-dessous:
[{ "instruction" : " " , "input" : " " , "output" : }, { ... }](mLoRA) file upload
? file type: train data
? name: alpaca
? file path: /home/yezhengmao/alpaca-lora/alpaca_data.jsonLe modèle dans un fichier YAML et écrivez par la langue de l'immatriculation Jinja2, voir le fichier démo / prompt.yaml
Le fichier de données que vous téléchargez peut être considéré comme des données de tableau, les éléments du tableau étant de type dictionnaire. Nous considérons chaque élément comme un point de données dans le modèle.
(mLoRA) file upload
? file type: prompt template
? name: simple_prompt
? file path: /home/yezhengmao/mLoRA/demo/prompt.yaml Nous créons un ensemble de données, l'ensemble de données se compose de données, d'un modèle et du prompteur correspondant. Nous pouvons utiliser la commande dataset showcase pour vérifier si les invites sont générées correctement.
(mLoRA) dataset create
? name: alpaca_dataset
? train data file: alpaca
? prompt template file: simple_prompt
? prompter: instruction
? data preprocessing: default
(mLoRA) dataset showcase
? dataset name: alpaca_dataset Maintenant, nous pouvons utiliser adapter create Command pour créer un adaptateur pour Train.
Enfin, nous pouvons soumettre la tâche pour former notre adaptateur à l'aide de l'ensemble de données défini. Remarque: vous pouvez soumettre en permanence des tâches de formation terminale. Utilisez l' adapter ls ou task ls pour vérifier l'état des tâches
L'utilisation de MLORA peut économiser des ressources de calcul et de mémoire significatives lors de la formation de plusieurs adaptateurs simultanément.
Nous avons affiné plusieurs adaptateurs LORA en utilisant quatre cartes graphiques A6000 avec une précision FP32 et sans utiliser de poitrine de contrôle et toute technique de quantification:
| Modèle | mlora (jetons / s) | Peft-lora avec FSDP (jetons / s) | Peft-lora avec tp (jetons / s) |
|---|---|---|---|
| LLAMA-2-7B (32FP) | 2364 | 1750 | 1500 |
| LLAMA-2-13B (32FP) | 1280 | Oom | 875 |
| Modèle | |
|---|---|
| ✓ | Lama |
| Variante | |
|---|---|
| ✓ | Qlora, Nips, 2023 |
| ✓ | Lora +, ICML, 2024 |
| ✓ | Vera, ICLR, 2024 |
| ✓ | Dora, ICML, 2024 |
| Variante | |
|---|---|
| ✓ | DPO, INIPS, 2024 |
| ✓ | CPO, ICML, 2024 |
| ✓ | CIT, Arxiv, 2024 |
Nous saluons les contributions pour améliorer ce référentiel! Veuillez consulter les directives de contribution avant de soumettre des demandes ou des problèmes de traction.
Fourk le référentiel. Créez une nouvelle branche pour votre fonctionnalité ou votre correction. Soumettez une demande de traction avec une explication détaillée de vos modifications.
Vous pouvez utiliser le pré-engagement pour vérifier votre code.
# Install requirements
pip install .[ci_test]
ln -s ../../.github/workflows/pre-commit .git/hooks/pre-commitOu appelez simplement le script pour vérifier votre code
.github/workflows/pre-commitVeuillez citer le dépôt si vous utilisez le code dans ce dépôt.
@misc { m-LoRA ,
author = { Zhengmao, Yetextsuperscript{*} and Dengchun, Litextsuperscript{*} and Jingqi, Tian and Tingfeng, Lan and Yanbo, Liang and Yexi, Jiang and Jie, Zuo and Hui, Lu and Lei, Duan and Mingjie, Tang } ,
title = { m-LoRA: Efficient LLM Model Fine-tune and Inference via Multi-Lora Optimization } ,
year = { 2023 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/TUDB-Labs/mLoRA} } ,
note = { textsuperscript{*}: these authors contributed equally to this work. }
}Copyright © 2024 Tous droits réservés.
Ce projet est concédé sous licence Apache 2.0.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


