mLoRA
1.0.0
mlora
"Pabrik" yang efisien untuk membangun beberapa adaptor Lora

Mlora (alias multi-lora fine-tune) adalah kerangka kerja open-source yang dirancang untuk penyempurnaan yang efisien dari beberapa model bahasa besar (LLM) menggunakan LORA dan variannya. Fitur utama mlora meliputi:
Penyetelan kesetiaan yang bersamaan dari beberapa adaptor Lora.
Model dasar bersama di antara beberapa adaptor Lora.
Algoritma paralelisme pipa yang efisien.
Dukungan untuk beberapa algoritma varian LORA dan berbagai model dasar.
Dukungan untuk beberapa algoritma penyelarasan preferensi penguatan.
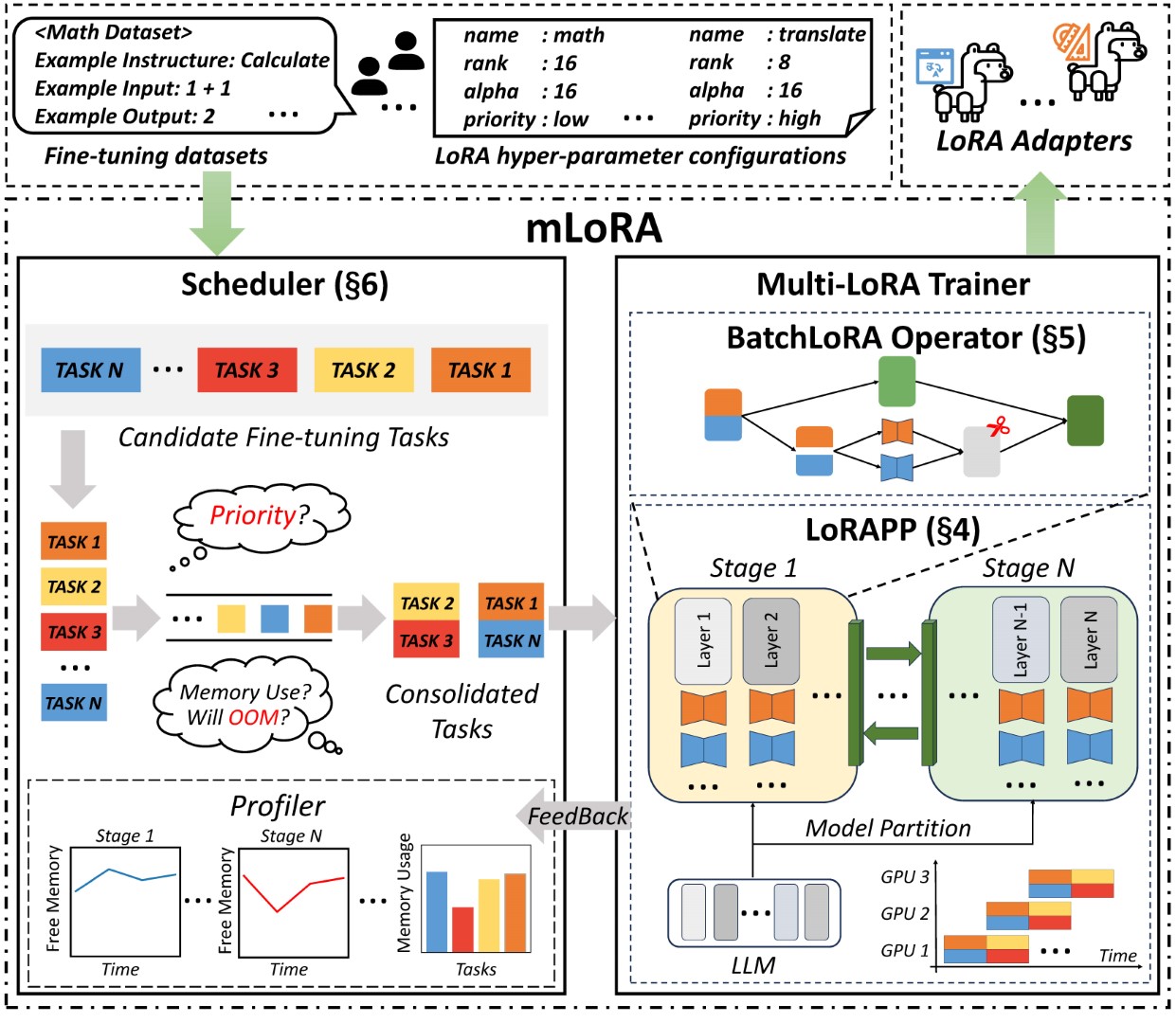
Arsitektur mlora ujung ke ujung ditunjukkan pada gambar:
Pertama, Anda harus mengkloning repositori ini dan menginstal dependensi (atau menggunakan gambar kami):
# Clone Repository
git clone https://github.com/TUDB-Labs/mLoRA
cd mLoRA
# Install requirements need the Python >= 3.12
pip install . Kode mlora_train.py adalah titik awal untuk adaptor Lora yang menyempurnakan batch.
python mlora_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yamlAnda dapat memeriksa konfigurasi adaptor di folder demo, ada beberapa konfigurasi mengenai penggunaan berbagai varian LORA dan algoritma penyelarasan preferensi penguatan.
Untuk informasi penggunaan terperinci lebih lanjut, silakan gunakan --help OPTION:
python mlora_train.py --helpMirip dengan QuickStart, perintah untuk memulai di lingkungan dua-simpul adalah sebagai berikut:
Note1: Gunakan variabel lingkungan MASTER_ADDR/MASTER_PORT untuk mengatur master node.
Note2: Set Saldo, menunjukkan jumlah lapisan dekoder yang dialokasikan untuk setiap peringkat.
# in the first node
export MASTER_ADDR=master.svc.cluster.local
export MASTER_PORT=12355
python mlora_pp_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yaml
--pipeline
--device " cuda:0 "
--rank 0
--balance 12 13
--no-recompute
--precision fp32
# in the second node
export MASTER_ADDR=master.svc.cluster.local
export MASTER_PORT=12355
python mlora_pp_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yaml
--pipeline
--device " cuda:1 "
--rank 1
--balance 12 13
--no-recompute
--precision fp32Mlora menawarkan gambar Docker resmi untuk awal dan pengembangan yang cepat, gambar tersedia di Dockerhub Packages Registry.
Pertama, Anda harus menarik gambar terbaru (gambar juga digunakan untuk pengembangan):
docker pull yezhengmaolove/mlora:latestMenyebarkan dan memasukkan wadah untuk menjalankan mlora:
docker run -itd --runtime nvidia --gpus all
-v ~ /your_dataset_dir:/dataset
-v ~ /your_model_dir:/model
-p < host_port > :22
--name mlora
yezhengmaolove/mlora:latest
# when the container started, use the ssh to login
# the default password is mlora@123
ssh root@localhost -p < host_port >
# pull the latest code and run the mlora
cd /mLoRA
git pull
python mlora_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yamlKami dapat menggunakan MLOAR sebagai layanan untuk terus menerima permintaan pengguna dan melakukan tugas yang menyempurnakan.
Pertama, Anda harus menarik gambar terbaru (gunakan gambar yang sama untuk digunakan):
docker pull yezhengmaolove/mlora:latestMenyebarkan server mlora kami:
docker run -itd --runtime nvidia --gpus all
-v ~ /your_dataset_cache_dir:/cache
-v ~ /your_model_dir:/model
-p < host_port > :8000
--name mlora_server
-e " BASE_MODEL=TinyLlama/TinyLlama-1.1B-Chat-v0.4 "
-e " STORAGE_DIR=/cache "
yezhengmaolove/mlora:latest /bin/bash /opt/deploy.sh Setelah layanan digunakan, instal dan gunakan mlora_cli.py untuk berinteraksi dengan server.
# install the client tools
pip install mlora-cli
# use the mlora cli tool to connect to mlora server
mlora_cli
(mLoRA) set port < host_port >
(mLoRA) set host http:// < host_ip >
# and enjoy it!!docker pull yezhengmaolove/mlora:latest
pip install mlora-cli # first, we create a cache dir in host for cache some file
mkdir ~ /cache
# second, we manually download the model weights from Hugging Face.
mkdir ~ /model && cd ~ /model
git clone https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0
# we map port 8000 used by the mlora server to port 1288 on the host machine.
# the BASE_MODEL environment variable indicates the path of the base model used by mlora.
# the STORAGE_DIR environment variable indicates the path where datasets and lora adapters are stored.
# we use the script /opt/deploy.sh in container to start the server.
docker run -itd --runtime nvidia --gpus all
-v ~ /cache:/cache
-v ~ /model:/model
-p 1288:8000
--name mlora_server
-e " BASE_MODEL=/model/TinyLlama-1.1B-Chat-v1.0 "
-e " STORAGE_DIR=/cache "
yezhengmaolove/mlora:latest /bin/bash /opt/deploy.shKami menggunakan tautan mlora_cli ke server http://127.0.0.1:1288 (harus menggunakan protokal http)
(mLoRA) set port 1288
(mLoRA) set host http://127.0.0.1Kami menggunakan dataset Stanford Alpaca sebagai demo, data seperti di bawah ini:
[{ "instruction" : " " , "input" : " " , "output" : }, { ... }](mLoRA) file upload
? file type: train data
? name: alpaca
? file path: /home/yezhengmao/alpaca-lora/alpaca_data.jsonTemplat dalam file YAML, dan tulis dengan Templating Language Jinja2, lihat file demo/prompt.yaml
File data yang Anda unggah dapat dianggap sebagai data array, dengan elemen -elemen dalam array yang menjadi tipe kamus. Kami menganggap setiap elemen sebagai titik data dalam templat.
(mLoRA) file upload
? file type: prompt template
? name: simple_prompt
? file path: /home/yezhengmao/mLoRA/demo/prompt.yaml Kami membuat dataset, dataset terdiri dari data, templat, dan prompter yang sesuai. Kami dapat menggunakan perintah dataset showcase untuk memeriksa apakah prompt dihasilkan dengan benar.
(mLoRA) dataset create
? name: alpaca_dataset
? train data file: alpaca
? prompt template file: simple_prompt
? prompter: instruction
? data preprocessing: default
(mLoRA) dataset showcase
? dataset name: alpaca_dataset Sekarang kita dapat menggunakan perintah adapter create untuk membuat adaptor untuk kereta api.
Akhirnya, kami dapat mengirimkan tugas untuk melatih adaptor kami menggunakan dataset yang ditentukan. Catatan: Anda dapat terus mengirimkan atau tugas pelatihan terminal. Gunakan adapter ls atau task ls untuk memeriksa status tugas
Menggunakan Mlora dapat menghemat sumber daya komputasi dan memori yang signifikan saat melatih banyak adaptor secara bersamaan.
Kami menyempurnakan beberapa adaptor LORA menggunakan empat kartu grafis A6000 dengan presisi FP32 dan tanpa menggunakan pos pemeriksaan dan teknik kuantisasi apa pun:
| Model | mlora (token/s) | Peft-lora dengan fsdp (token/s) | Peft-lora dengan tp (token/s) |
|---|---|---|---|
| Llama-2-7B (32FP) | 2364 | 1750 | 1500 |
| Llama-2-13b (32FP) | 1280 | Oom | 875 |
| Model | |
|---|---|
| ✓ | Llama |
| Variasi | |
|---|---|
| ✓ | Qlora, Nips, 2023 |
| ✓ | Lora+, ICML, 2024 |
| ✓ | Vera, iclr, 2024 |
| ✓ | Dora, ICML, 2024 |
| Variasi | |
|---|---|
| ✓ | DPO, Neurips, 2024 |
| ✓ | CPO, ICML, 2024 |
| ✓ | Cit, arxiv, 2024 |
Kami menyambut kontribusi untuk meningkatkan repositori ini! Harap tinjau pedoman kontribusi sebelum mengirimkan permintaan atau masalah tarik.
Garpu repositori. Buat cabang baru untuk fitur atau perbaiki Anda. Kirimkan permintaan tarik dengan penjelasan terperinci tentang perubahan Anda.
Anda dapat menggunakan pra-komit untuk memeriksa kode Anda.
# Install requirements
pip install .[ci_test]
ln -s ../../.github/workflows/pre-commit .git/hooks/pre-commitAtau hubungi skrip untuk memeriksa kode Anda
.github/workflows/pre-commitHarap kutip repo jika Anda menggunakan kode dalam repo ini.
@misc { m-LoRA ,
author = { Zhengmao, Yetextsuperscript{*} and Dengchun, Litextsuperscript{*} and Jingqi, Tian and Tingfeng, Lan and Yanbo, Liang and Yexi, Jiang and Jie, Zuo and Hui, Lu and Lei, Duan and Mingjie, Tang } ,
title = { m-LoRA: Efficient LLM Model Fine-tune and Inference via Multi-Lora Optimization } ,
year = { 2023 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/TUDB-Labs/mLoRA} } ,
note = { textsuperscript{*}: these authors contributed equally to this work. }
}Hak Cipta © 2024 Hak Dilindungi Undang -Undang.
Proyek ini dilisensikan di bawah lisensi Apache 2.0.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


