mLoRA
1.0.0
mlora
複数のLORAアダプターを構築するための効率的な「工場」

Mlora(別名Multi-Lora微調整)は、LORAとそのバリアントを使用した複数の大手言語モデル(LLMS)の効率的な微調整のために設計されたオープンソースフレームワークです。 Mloraの主な機能は次のとおりです。
複数のLORAアダプターの同時微調整。
複数のLORAアダプター間で共有ベースモデル。
効率的なパイプライン並列性アルゴリズム。
複数のLORAバリアントアルゴリズムとさまざまなベースモデルのサポート。
複数の強化学習優先アライメントアルゴリズムのサポート。
ムロラのエンドツーエンドアーキテクチャを図に示します。
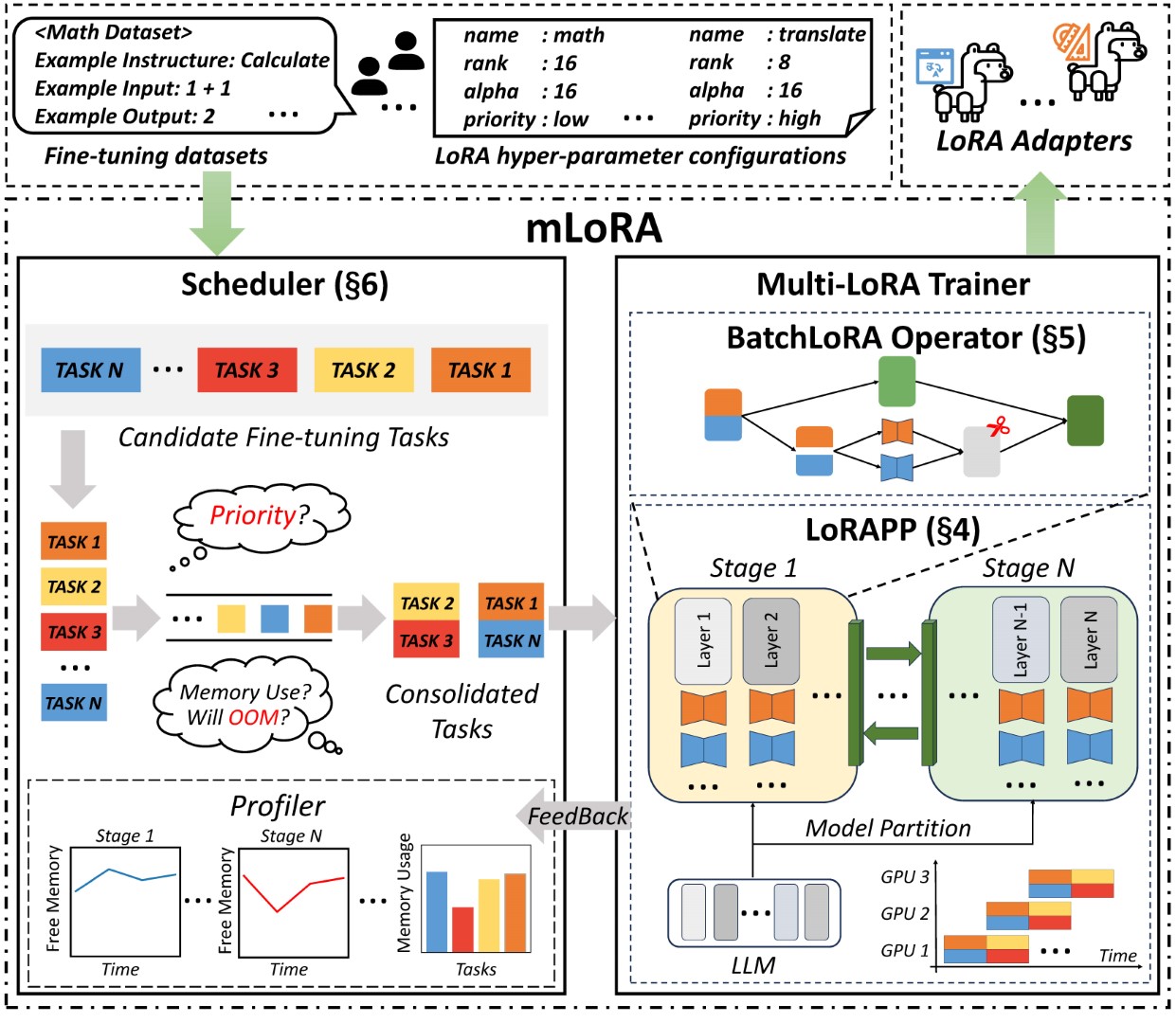
まず、このリポジトリをクローンし、依存関係をインストールする(または画像を使用)する必要があります。
# Clone Repository
git clone https://github.com/TUDB-Labs/mLoRA
cd mLoRA
# Install requirements need the Python >= 3.12
pip install . mlora_train.pyコードは、バッチ微調整loraアダプターの出発点です。
python mlora_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yamlデモフォルダーのアダプターの構成を確認できます。さまざまなLORAバリアントの使用と強化学習優先アライメントアルゴリズムに関する構成があります。
詳細な使用情報については、 --helpオプションを使用してください。
python mlora_train.py --helpQuickStartと同様に、2ノード環境で開始するコマンドは次のとおりです。
注1:環境変数MASTER_ADDR/MASTER_PORTを使用して、マスターノードを設定します。
Note2:バランスを設定し、各ランクに割り当てられたデコーダー層の数を示します。
# in the first node
export MASTER_ADDR=master.svc.cluster.local
export MASTER_PORT=12355
python mlora_pp_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yaml
--pipeline
--device " cuda:0 "
--rank 0
--balance 12 13
--no-recompute
--precision fp32
# in the second node
export MASTER_ADDR=master.svc.cluster.local
export MASTER_PORT=12355
python mlora_pp_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yaml
--pipeline
--device " cuda:1 "
--rank 1
--balance 12 13
--no-recompute
--precision fp32Mloraは、クイックスタートと開発のために公式のDocker画像を提供します。この画像はDockerHub Packagesレジストリで入手できます。
まず、最新の画像をプルする必要があります(画像は開発にも使用します):
docker pull yezhengmaolove/mlora:latestMloraを実行するためにコンテナを展開して入力します。
docker run -itd --runtime nvidia --gpus all
-v ~ /your_dataset_dir:/dataset
-v ~ /your_model_dir:/model
-p < host_port > :22
--name mlora
yezhengmaolove/mlora:latest
# when the container started, use the ssh to login
# the default password is mlora@123
ssh root@localhost -p < host_port >
# pull the latest code and run the mlora
cd /mLoRA
git pull
python mlora_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yamlMloarをサービスとして展開して、ユーザーリクエストを継続的に受け取り、微調整タスクを実行できます。
まず、最新の画像をプルする必要があります(展開には同じ画像を使用してください):
docker pull yezhengmaolove/mlora:latestMloraサーバーを展開します。
docker run -itd --runtime nvidia --gpus all
-v ~ /your_dataset_cache_dir:/cache
-v ~ /your_model_dir:/model
-p < host_port > :8000
--name mlora_server
-e " BASE_MODEL=TinyLlama/TinyLlama-1.1B-Chat-v0.4 "
-e " STORAGE_DIR=/cache "
yezhengmaolove/mlora:latest /bin/bash /opt/deploy.shサービスが展開されたら、 mlora_cli.pyをインストールして使用してサーバーと対話します。
# install the client tools
pip install mlora-cli
# use the mlora cli tool to connect to mlora server
mlora_cli
(mLoRA) set port < host_port >
(mLoRA) set host http:// < host_ip >
# and enjoy it!!docker pull yezhengmaolove/mlora:latest
pip install mlora-cli # first, we create a cache dir in host for cache some file
mkdir ~ /cache
# second, we manually download the model weights from Hugging Face.
mkdir ~ /model && cd ~ /model
git clone https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0
# we map port 8000 used by the mlora server to port 1288 on the host machine.
# the BASE_MODEL environment variable indicates the path of the base model used by mlora.
# the STORAGE_DIR environment variable indicates the path where datasets and lora adapters are stored.
# we use the script /opt/deploy.sh in container to start the server.
docker run -itd --runtime nvidia --gpus all
-v ~ /cache:/cache
-v ~ /model:/model
-p 1288:8000
--name mlora_server
-e " BASE_MODEL=/model/TinyLlama-1.1B-Chat-v1.0 "
-e " STORAGE_DIR=/cache "
yezhengmaolove/mlora:latest /bin/bash /opt/deploy.shサーバーへのmlora_cliリンクhttp://127.0.0.1:1288(HTTP Protocalを使用する必要があります)
(mLoRA) set port 1288
(mLoRA) set host http://127.0.0.1Stanford Alpaca Datasetをデモとして使用します。
[{ "instruction" : " " , "input" : " " , "output" : }, { ... }](mLoRA) file upload
? file type: train data
? name: alpaca
? file path: /home/yezhengmao/alpaca-lora/alpaca_data.jsonYAMLファイルのテンプレート、およびテンプレート言語Jinja2で書き込み、demo/prompt.yamlファイルを参照してください
アップロードするデータファイルは、配列データと見なすことができ、配列の要素は辞書タイプです。各要素は、テンプレートのデータポイントと見なします。
(mLoRA) file upload
? file type: prompt template
? name: simple_prompt
? file path: /home/yezhengmao/mLoRA/demo/prompt.yamlデータセットを作成し、データセットはデータ、テンプレート、および対応するプロンプターで構成されます。 dataset showcaseコマンドを使用して、プロンプトが正しく生成されているかどうかを確認できます。
(mLoRA) dataset create
? name: alpaca_dataset
? train data file: alpaca
? prompt template file: simple_prompt
? prompter: instruction
? data preprocessing: default
(mLoRA) dataset showcase
? dataset name: alpaca_datasetこれで、 adapter createコマンドを使用して、トレイン用のアダプターを作成できます。
最後に、定義されたデータセットを使用してアダプターをトレーニングするためにタスクを送信できます。注:継続的にトレーニングタスクを継続的に送信またはターミナルすることができます。 adapter lsまたはtask lsを使用して、タスクのステータスを確認します
Mloraを使用すると、複数のアダプターを同時にトレーニングするときに、重要な計算リソースとメモリリソースを節約できます。
FP32精度を備えた4つのA6000グラフィックスカードを使用して、チェックポイントと量子化技術を使用せずに、複数のLORAアダプターを微調整しました。
| モデル | mlora(トークン/s) | fsdp(トークン/s)のpeft-lora | TP(トークン/s)のpeft-lora |
|---|---|---|---|
| llama-2-7b(32fp) | 2364 | 1750 | 1500 |
| llama-2-13b(32fp) | 1280 | ooom | 875 |
| モデル | |
|---|---|
| ✓✓ | ラマ |
| 変異体 | |
|---|---|
| ✓✓ | Qlora、NIPS、2023 |
| ✓✓ | Lora+、ICML、2024 |
| ✓✓ | Vera、ICLR、2024 |
| ✓✓ | ドラ、ICML、2024 |
| 変異体 | |
|---|---|
| ✓✓ | DPO、ニューリップス、2024 |
| ✓✓ | CPO、ICML、2024 |
| ✓✓ | CIT、arxiv、2024 |
このリポジトリを改善するための貢献を歓迎します!プルリクエストまたは問題を送信する前に、貢献ガイドラインを確認してください。
リポジトリをフォークします。機能または修正用の新しいブランチを作成します。変更の詳細な説明を記載したプルリクエストを送信してください。
事前コミットを使用してコードを確認できます。
# Install requirements
pip install .[ci_test]
ln -s ../../.github/workflows/pre-commit .git/hooks/pre-commitまたは、スクリプトを呼び出してコードを確認してください
.github/workflows/pre-commitこのリポジトリでコードを使用する場合は、リポジトリを引用してください。
@misc { m-LoRA ,
author = { Zhengmao, Yetextsuperscript{*} and Dengchun, Litextsuperscript{*} and Jingqi, Tian and Tingfeng, Lan and Yanbo, Liang and Yexi, Jiang and Jie, Zuo and Hui, Lu and Lei, Duan and Mingjie, Tang } ,
title = { m-LoRA: Efficient LLM Model Fine-tune and Inference via Multi-Lora Optimization } ,
year = { 2023 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/TUDB-Labs/mLoRA} } ,
note = { textsuperscript{*}: these authors contributed equally to this work. }
}Copyright©2024 All Rights Reserved。
このプロジェクトは、Apache 2.0ライセンスの下でライセンスされています。
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


