mLoRA
1.0.0
mlora
Uma "fábrica" eficiente para construir vários adaptadores LORA

O Mlora (também conhecido como Tune Fine-Tune) é uma estrutura de código aberto projetado para ajustes finos eficientes de vários modelos de linguagem grande (LLMS) usando o LORA e suas variantes. Os principais recursos do mlora incluem:
Ajuste fino simultâneo de vários adaptadores LORA.
Modelo de base compartilhada entre vários adaptadores LORA.
Algoritmo de paralelismo eficiente do pipeline.
Suporte para vários algoritmos variantes Lora e vários modelos básicos.
Apoio a vários algoritmos de alinhamento de preferência de aprendizado de reforço.
A arquitetura de ponta a ponta da mlora é mostrada na figura:
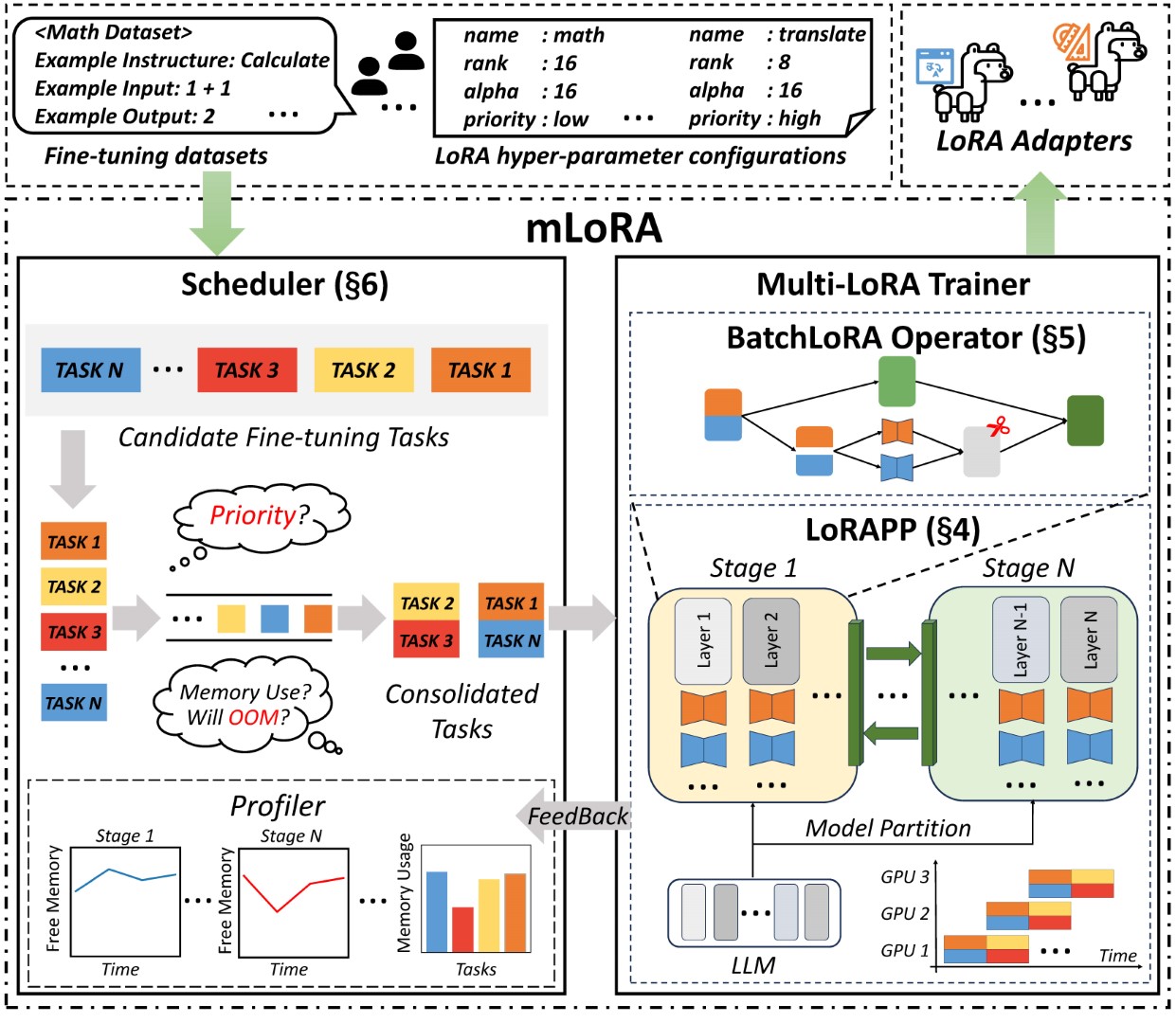
Em primeiro lugar, você deve clonar este repositório e instalar dependências (ou usar nossa imagem):
# Clone Repository
git clone https://github.com/TUDB-Labs/mLoRA
cd mLoRA
# Install requirements need the Python >= 3.12
pip install . O código mlora_train.py é um ponto de partida para os adaptadores LORA de ajuste fino em lote.
python mlora_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yamlVocê pode verificar a configuração dos adaptadores na pasta Demo, há alguma configuração em relação ao uso de diferentes variantes de LORA e algoritmos de alinhamento de preferência de aprendizado de reforço.
Para obter mais informações detalhadas sobre o uso, use --help Help:
python mlora_train.py --helpSemelhante ao QuickStart, o comando para iniciar em um ambiente de dois nós é o seguinte:
Nota 1: Use variáveis de ambiente MASTER_ADDR/MASTER_PORT para definir o nó principal.
Nota2: Defina o saldo, indicando o número de camadas do decodificador alocadas para cada classificação.
# in the first node
export MASTER_ADDR=master.svc.cluster.local
export MASTER_PORT=12355
python mlora_pp_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yaml
--pipeline
--device " cuda:0 "
--rank 0
--balance 12 13
--no-recompute
--precision fp32
# in the second node
export MASTER_ADDR=master.svc.cluster.local
export MASTER_PORT=12355
python mlora_pp_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yaml
--pipeline
--device " cuda:1 "
--rank 1
--balance 12 13
--no-recompute
--precision fp32Mlora oferece uma imagem oficial do Docker para início e desenvolvimento rápido, a imagem está disponível no registro de pacotes do DockerHub.
Primeiro, você deve puxar a imagem mais recente (a imagem também usa para desenvolvimento):
docker pull yezhengmaolove/mlora:latestImplante e insira um contêiner para executar Mlora:
docker run -itd --runtime nvidia --gpus all
-v ~ /your_dataset_dir:/dataset
-v ~ /your_model_dir:/model
-p < host_port > :22
--name mlora
yezhengmaolove/mlora:latest
# when the container started, use the ssh to login
# the default password is mlora@123
ssh root@localhost -p < host_port >
# pull the latest code and run the mlora
cd /mLoRA
git pull
python mlora_train.py
--base_model TinyLlama/TinyLlama-1.1B-Chat-v0.4
--config demo/lora/lora_case_1.yamlPodemos implantar o MLOAR como um serviço para receber continuamente solicitações de usuário e executar a tarefa de ajuste fino.
Primeiro, você deve puxar a imagem mais recente (use a mesma imagem para implantar):
docker pull yezhengmaolove/mlora:latestImplante nosso servidor Mlora:
docker run -itd --runtime nvidia --gpus all
-v ~ /your_dataset_cache_dir:/cache
-v ~ /your_model_dir:/model
-p < host_port > :8000
--name mlora_server
-e " BASE_MODEL=TinyLlama/TinyLlama-1.1B-Chat-v0.4 "
-e " STORAGE_DIR=/cache "
yezhengmaolove/mlora:latest /bin/bash /opt/deploy.sh Depois que o serviço for implantado, instale e use mlora_cli.py para interagir com o servidor.
# install the client tools
pip install mlora-cli
# use the mlora cli tool to connect to mlora server
mlora_cli
(mLoRA) set port < host_port >
(mLoRA) set host http:// < host_ip >
# and enjoy it!!docker pull yezhengmaolove/mlora:latest
pip install mlora-cli # first, we create a cache dir in host for cache some file
mkdir ~ /cache
# second, we manually download the model weights from Hugging Face.
mkdir ~ /model && cd ~ /model
git clone https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0
# we map port 8000 used by the mlora server to port 1288 on the host machine.
# the BASE_MODEL environment variable indicates the path of the base model used by mlora.
# the STORAGE_DIR environment variable indicates the path where datasets and lora adapters are stored.
# we use the script /opt/deploy.sh in container to start the server.
docker run -itd --runtime nvidia --gpus all
-v ~ /cache:/cache
-v ~ /model:/model
-p 1288:8000
--name mlora_server
-e " BASE_MODEL=/model/TinyLlama-1.1B-Chat-v1.0 "
-e " STORAGE_DIR=/cache "
yezhengmaolove/mlora:latest /bin/bash /opt/deploy.shUsamos o link mlora_cli para o servidor http://127.0.0.1:1288 (deve usar o protocal HTTP)
(mLoRA) set port 1288
(mLoRA) set host http://127.0.0.1Usamos o conjunto de dados Stanford Alpaca como uma demonstração, os dados como abaixo:
[{ "instruction" : " " , "input" : " " , "output" : }, { ... }](mLoRA) file upload
? file type: train data
? name: alpaca
? file path: /home/yezhengmao/alpaca-lora/alpaca_data.jsonO modelo em um arquivo YAML e escreva por modelos de idioma jinja2, consulte o arquivo de demonstração/prompt.yaml
O arquivo de dados que você carrega pode ser considerado como dados da matriz, com os elementos da matriz sendo do tipo de dicionário. Consideramos cada elemento como um ponto de dados no modelo.
(mLoRA) file upload
? file type: prompt template
? name: simple_prompt
? file path: /home/yezhengmao/mLoRA/demo/prompt.yaml Criamos um conjunto de dados, o conjunto de dados consiste em dados, um modelo e o Prompter correspondente. Podemos usar o comando dataset showcase para verificar se os prompts forem gerados corretamente.
(mLoRA) dataset create
? name: alpaca_dataset
? train data file: alpaca
? prompt template file: simple_prompt
? prompter: instruction
? data preprocessing: default
(mLoRA) dataset showcase
? dataset name: alpaca_dataset Agora, podemos usar o comando adapter create para criar um adaptador para o trem.
Por fim, podemos enviar a tarefa para treinar nosso adaptador usando o conjunto de dados definido. NOTA: Você pode enviar continuamente ou enviar tarefas de treinamento em terminal. Use o adapter ls ou task ls para verificar o status das tarefas
O uso do MLORA pode economizar recursos computacionais e de memória significativos ao treinar vários adaptadores simultaneamente.
Nós ajustamos vários adaptadores LORA usando quatro placas gráficas A6000 com precisão de FP32 e sem usar o check-se e nenhuma técnica de quantização:
| Modelo | mlora (tokens/s) | Peft-lora com fsdp (tokens/s) | Peft-lora com tp (tokens/s) |
|---|---|---|---|
| LLAMA-2-7B (32FP) | 2364 | 1750 | 1500 |
| LLAMA-2-13B (32FP) | 1280 | OOM | 875 |
| Modelo | |
|---|---|
| ✓ | Lhama |
| Variante | |
|---|---|
| ✓ | Qlora, Nips, 2023 |
| ✓ | Lora+, ICML, 2024 |
| ✓ | Vera, ICLR, 2024 |
| ✓ | Dora, ICML, 2024 |
| Variante | |
|---|---|
| ✓ | DPO, Neurips, 2024 |
| ✓ | CPO, ICML, 2024 |
| ✓ | Cit, Arxiv, 2024 |
Congratulamo -nos com contribuições para melhorar este repositório! Revise as diretrizes de contribuição antes de enviar solicitações ou problemas de puxar.
Fork o repositório. Crie uma nova filial para o seu recurso ou correção. Envie uma solicitação de tração com uma explicação detalhada de suas alterações.
Você pode usar o pré-compromisso para verificar seu código.
# Install requirements
pip install .[ci_test]
ln -s ../../.github/workflows/pre-commit .git/hooks/pre-commitOu basta ligar para o script para verificar seu código
.github/workflows/pre-commitCite o repositório se você usar o código neste repo.
@misc { m-LoRA ,
author = { Zhengmao, Yetextsuperscript{*} and Dengchun, Litextsuperscript{*} and Jingqi, Tian and Tingfeng, Lan and Yanbo, Liang and Yexi, Jiang and Jie, Zuo and Hui, Lu and Lei, Duan and Mingjie, Tang } ,
title = { m-LoRA: Efficient LLM Model Fine-tune and Inference via Multi-Lora Optimization } ,
year = { 2023 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/TUDB-Labs/mLoRA} } ,
note = { textsuperscript{*}: these authors contributed equally to this work. }
}Copyright © 2024 Todos os direitos reservados.
Este projeto está licenciado sob a licença Apache 2.0.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


