Grad TTS Chinese
release grad-tts-cfm
โครงการอัลกอริทึม TTS เพื่อการเรียนรู้มีความเร็วในการใช้เหตุผลช้า แต่การแพร่กระจายเป็นเทรนด์ที่ยิ่งใหญ่
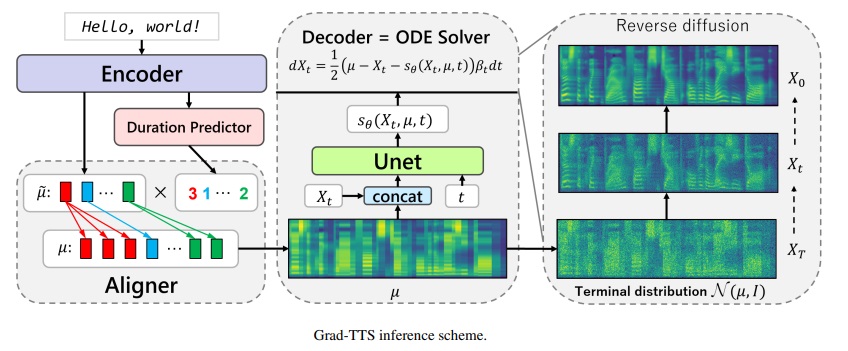
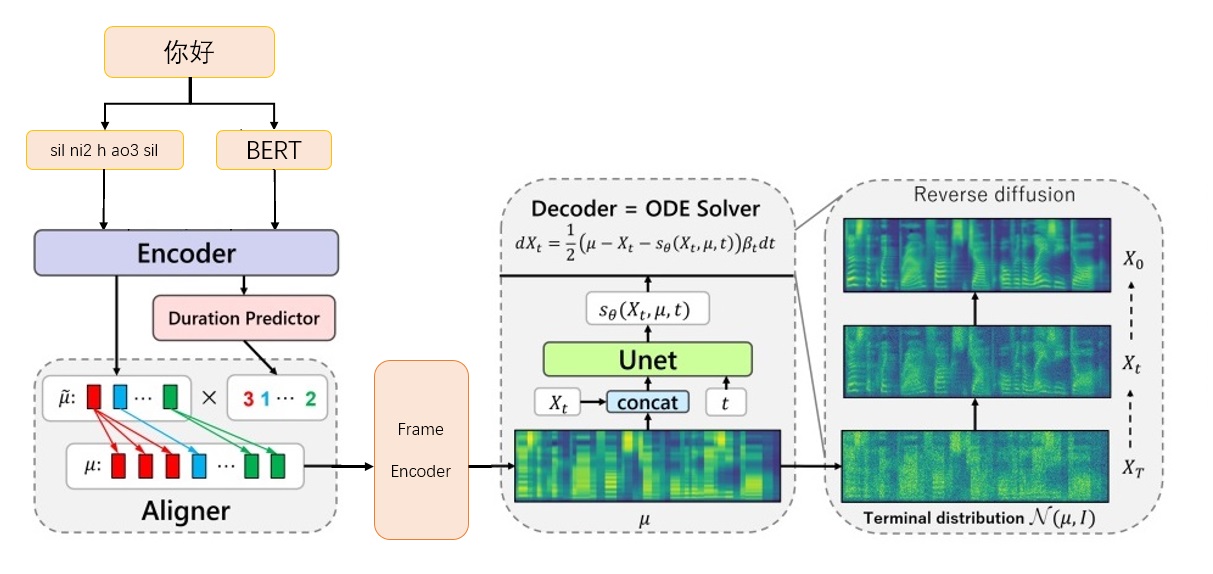 เฟรมเวิร์ก Grad-CFM
เฟรมเวิร์ก Grad-CFM
ดาวน์โหลดโมเดล Vocoder bigvgan_base_24khz_100band จาก nvidia/bigvgan
ใส่ g_05000000 ใน./bigvgan_pretrain/g_0500000
ดาวน์โหลด bert prosody_model จาก Executedone/Chinese-FastSpeech2
เปลี่ยนชื่อ best_model.pt เป็น prosody_model.pt และวางไว้ใน ./bert/prosody_model.pt
ดาวน์โหลดรุ่น TTS จากหน้าเผยแพร่ grad_tts.pt จากหน้ารีลีส
ใส่ grad_tts.pt ในไดเรกทอรีปัจจุบันหรือที่ใดก็ได้
การพึ่งพาสภาพแวดล้อมการติดตั้ง
PIP Install -r rechent.txt
cd ./grad/monotonic_align
python setup.py build_ext ---lapl
ซีดี -
การทดสอบการอนุมาน
Python การอนุมาน.py -ไฟล์ test.txt -Checkpoint Grad_tts.pt -Timesteps 10 -อุณหภูมิ 1.015
สร้างเสียงใน ./inference_out
ยิ่ง timesteps ใหญ่ขึ้นเท่าไหร่ก็ยิ่งมีผลกระทบมากขึ้นเท่านั้น เมื่อตั้งค่าเป็น 0 การแพร่กระจายจะถูกข้ามและสเปกตรัม MEL ที่สร้างขึ้นโดย FrameConder จะถูกส่งออก
temperature กำหนดปริมาณของเสียงที่เพิ่มขึ้นโดยการใช้เหตุผลการแพร่กระจายและจำเป็นต้องดีบักค่าที่ดีที่สุด
ดาวน์โหลดลิงค์อย่างเป็นทางการของข้อมูล biaobei: https://www.data-baker.com/data/index/tntts/
ใส่ Waves ใน./data/waves
ใส่ 000001-010000.txt ใน ./data/000001-010000.txt
การสุ่มตัวอย่างเป็น 24kHz เป็นรุ่น Bigvgan 24K ใช้
Python Tools/preprocess_a.py -w ./data/wave/ -o ./data/wavs -s
24000
แยกสเปกตรัม MEL และแทนที่ Vocoder คุณต้องให้ความสนใจกับพารามิเตอร์ MEL ที่เขียนไว้ในรหัส
Python Tools/preprocess_m.py -wav data/wavs/ -out data/mels/
แยกเวกเตอร์การออกเสียง Bert และสร้างไฟล์ดัชนีการฝึกอบรม train.txt และ valid.txt ในเวลาเดียวกัน
Python Tools/preprocess_b.py
เอาต์พุตรวมถึง data/berts/ และ data/files
หมายเหตุ: ข้อมูลการพิมพ์คือการลบ儿化音(โครงการเป็นการสาธิตอัลกอริทึมและไม่ทำการผลิต)
คำแนะนำเพิ่มเติม
ฉลากดั้งเดิม
000001 卡尔普#2陪外孙#1玩滑梯#4。
ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
000002 假语村言#2别再#1拥抱我#4。
jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3 มันจะต้องถูกทำเครื่องหมายว่าเบิร์ตต้องใช้ตัวละครจีน卡尔普陪外孙玩滑梯。 (รวมถึงเครื่องหมายวรรคตอน), tts ต้องการเสียงสระสุดท้าย sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
000001 卡尔普陪外孙玩滑梯。
ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
000002 假语村言别再拥抱我。
jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3
sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp silฉลาก
./data/wavs/000001.wav|./data/mels/000001.pt|./data/berts/000001.npy|sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
./data/wavs/000002.wav|./data/mels/000002.pt|./data/berts/000002.npy|sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp sil
ประโยคนี้จะทำให้เกิดข้อผิดพลาด
002365 这图#2难不成#2是#1P过的#4?
zhe4 tu2 nan2 bu4 cheng2 shi4 P IY1 guo4 de5
ชุดข้อมูลการดีบัก
Python Tools/preprocess_d.py
เริ่มการฝึกอบรม
Python Train.py
การฝึกอบรมการกู้คืน
python train.py -p logs/new_exp/grad_tts _ ***. pt.
Python การอนุมาน.py -ไฟล์ test.txt -Checkpoint ./logs/New_Exp/grad_tts_***.pt -Timesteps 20 -อุณหภูมิ 1.15
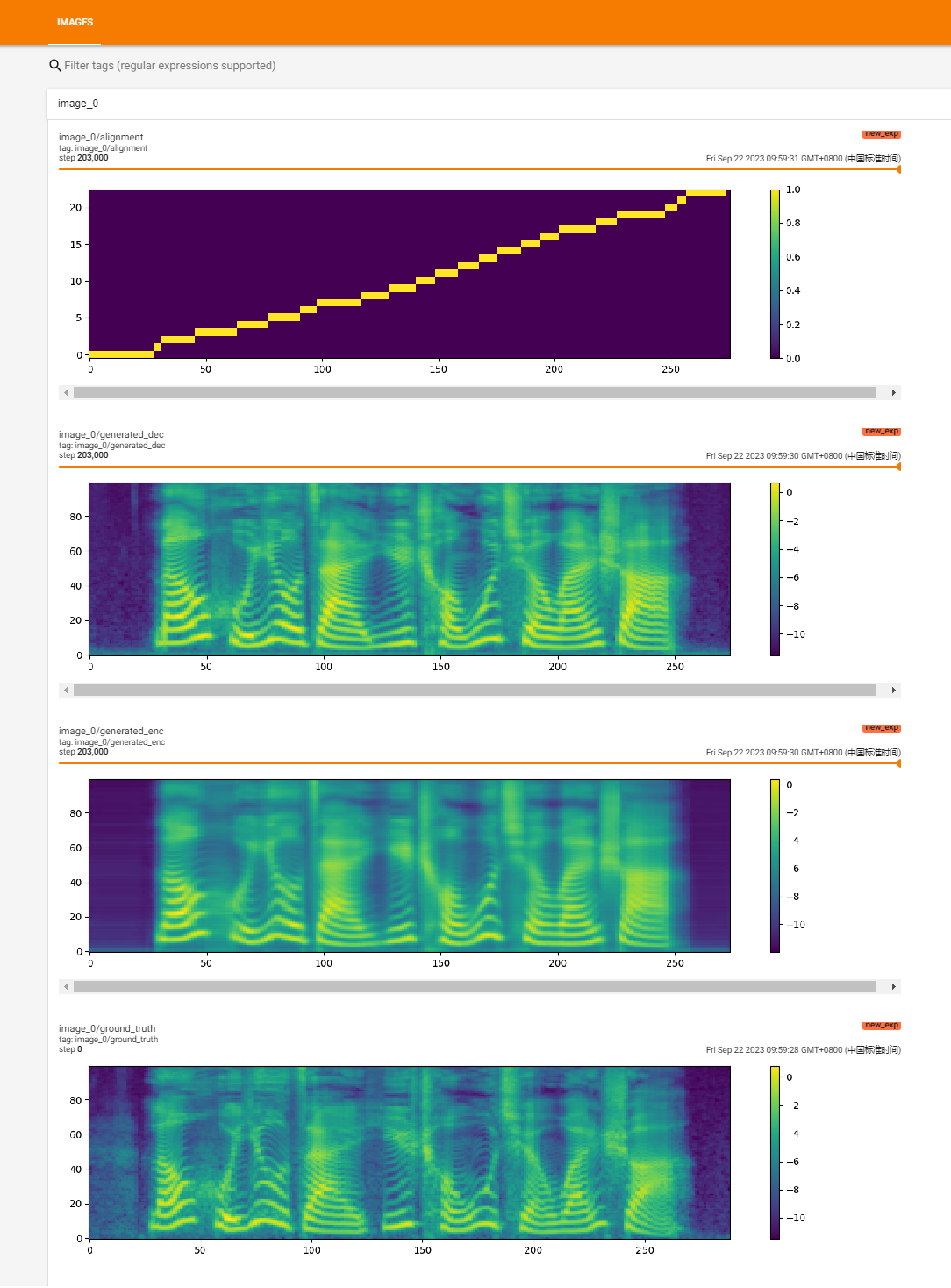
https://github.com/huawei-noah/speech-backbones/blob/main/grad-tts
https://github.com/shivammehta25/matcha-tts
https://github.com/thuhcsi/lightgrad
https://github.com/executedone/chinese-fastspeech2
https://github.com/playvoice/vits_chinese
https://github.com/nvidia/bigvgan
การดำเนินการอย่างเป็นทางการของโมเดล Grad-TTS ตามการสร้างแบบจำลองความน่าจะเป็นในการแพร่กระจาย สำหรับรายละเอียดทั้งหมดตรวจสอบบทความของเราที่ได้รับการยอมรับจาก ICML 2021 ผ่านลิงค์นี้
ผู้เขียน : Vadim Popov*, Ivan Vovk*, Vladimir Gogoryan, Tasnima Sadekova, Mikhail Kudinov
*การมีส่วนร่วมที่เท่าเทียมกัน
หน้าสาธิต พร้อมบทคัดย่อที่เปล่งออกมา: ลิงก์
เมื่อเร็ว ๆ นี้แบบจำลองความน่าจะเป็นของการแพร่กระจายและการจับคู่คะแนนทั่วไปได้แสดงให้เห็นถึงศักยภาพสูงในการสร้างแบบจำลองการแจกแจงข้อมูลที่ซับซ้อนในขณะที่การคำนวณแบบสุ่มได้ให้มุมมองแบบครบวงจรเกี่ยวกับเทคนิคเหล่านี้ช่วยให้แผนการอนุมานที่ยืดหยุ่น ในบทความนี้เราแนะนำ Grad-TTS ซึ่งเป็นแบบจำลองข้อความเป็นคำพูดแบบใหม่ที่มีตัวถอดรหัสที่ทำคะแนนให้สร้าง mel-spectrograms โดยค่อยๆเปลี่ยนเสียงรบกวนที่คาดการณ์ไว้โดย encoder และจัดแนวด้วยการป้อนข้อมูลข้อความโดยใช้การค้นหาการจัดตำแหน่งแบบโมโนโทนิก เฟรมเวิร์กของสมการเชิงอนุพันธ์สุ่มช่วยให้เราสามารถสรุปแบบจำลองความน่าจะเป็นที่แตกต่างกันทั่วไปในกรณีของการสร้างข้อมูลใหม่จากเสียงรบกวนด้วยพารามิเตอร์ที่แตกต่างกันและช่วยให้การสร้างใหม่นี้มีความยืดหยุ่นโดยการควบคุมการแลกเปลี่ยนระหว่างคุณภาพเสียงและความเร็วในการอนุมานอย่างชัดเจน การประเมินผลของมนุษย์แบบอัตนัยแสดงให้เห็นว่าผู้สำเร็จการศึกษา TTS มีการแข่งขันด้วยวิธีการพูดข้อความที่ทันสมัยในแง่ของคะแนนความคิดเห็นเฉลี่ย
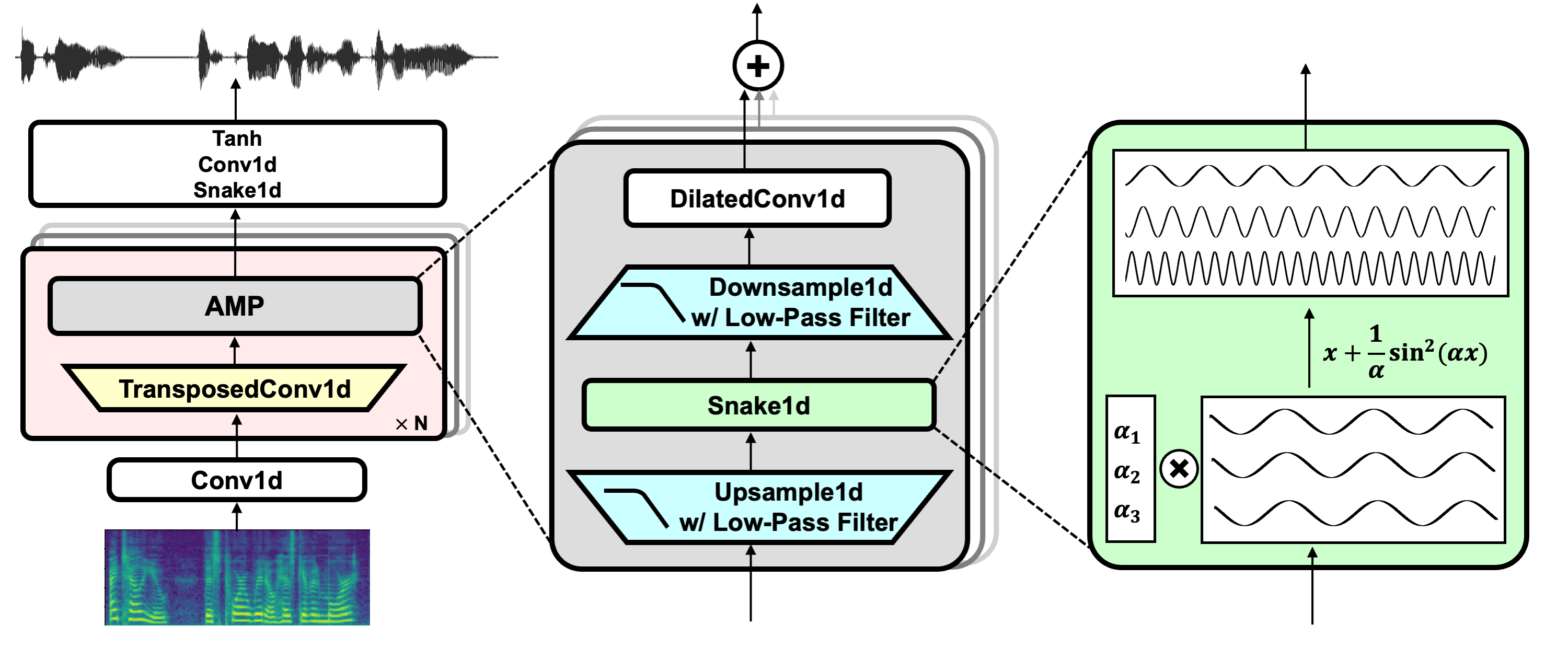
ลิงค์โครงการ: https://github.com/nvidia/bigvgan
ดาวน์โหลด pretrain model bigvgan_base_24khz_100band
python bigvgan/inference.py
--input_wavs_dir bigvgan_debug
--output_dir bigvgan_outpython bigvgan/train.py -config bigvgan_pretrain/config.json
hifi-gan (สำหรับเครื่องกำเนิดไฟฟ้าและ discriminator หลายช่วงเวลา)
งู (สำหรับการเปิดใช้งานเป็นระยะ)
นามแฝง-Free-Torch (สำหรับการต่อต้านนามแฝง)
Julius (สำหรับตัวกรอง Low-Pass)
univnet (สำหรับ discriminator ความละเอียดหลายตัว)


