Grad TTS Chinese
release grad-tts-cfm
مشروع خوارزمية TTS للتعلم بطيئة في سرعة التفكير ، ولكن الانتشار هو اتجاه كبير
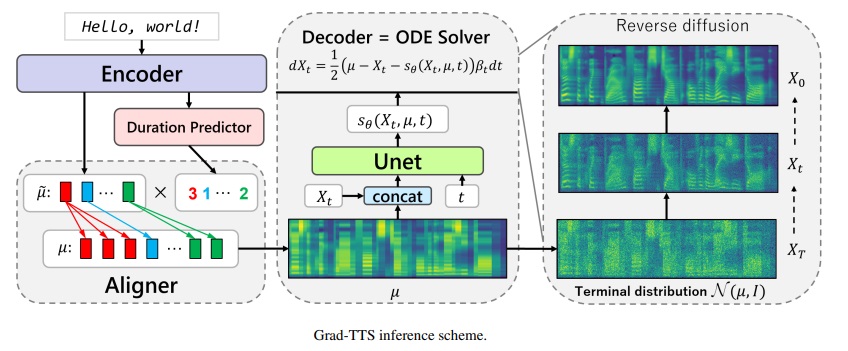
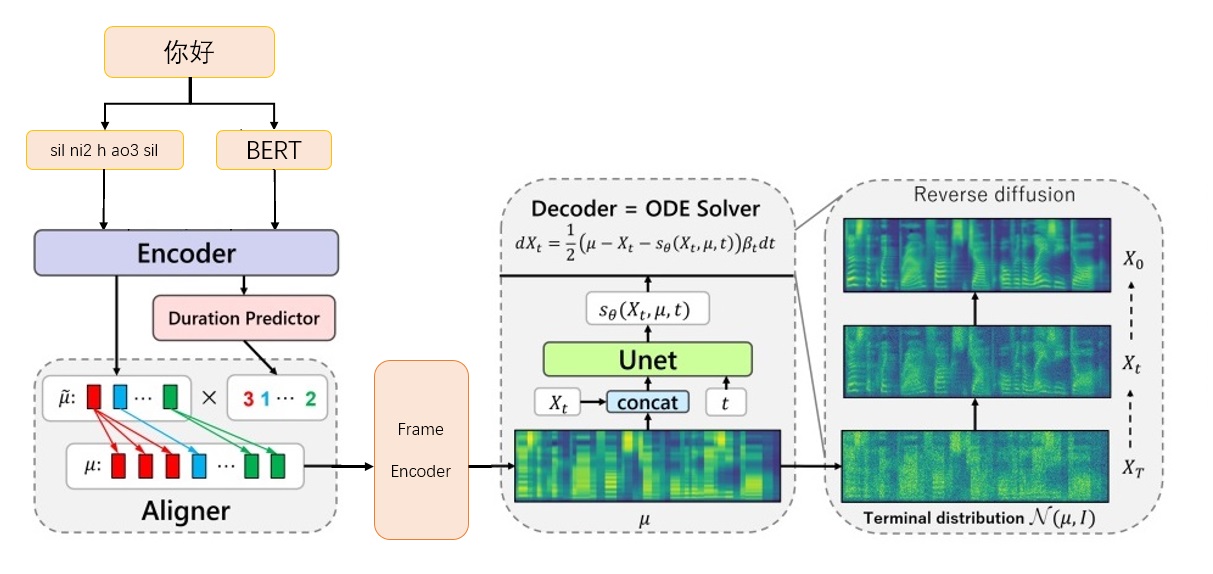 إطار Grad-TTS-CFM
إطار Grad-TTS-CFM
قم بتنزيل نموذج Vocoder BigVgan_Base_24KHZ_100BAND من NVIDIA/BIGVGAN
ضع G_05000000 في ./bigvgan_pretrain/g_0500000
قم بتنزيل Bert Prosody_Model من ExevedOne/Chinese-Fastspeech2
إعادة تسمية Best_Model.pt إلى prosody_model.pt ووضعه في ./bert/prosody_model.pt
قم بتنزيل نموذج TTS من صفحة الإصدار grad_tts.pt من صفحة الإصدار
ضع grad_tts.pt في الدليل الحالي ، أو في أي مكان
التبعية بيئة التثبيت
PIP تثبيت -r متطلبات. txt
CD ./grad/monotonic_align
python setup.py build_ext -مكانه
قرص مضغوط -
اختبار الاستنتاج
Python Interference.py -File Test.txt -CheckPoint Grad_tts.pt -Timesteps 10 -درجة الحرارة 1.015
إنشاء الصوت في ./inference_out
كلما زادت timesteps ، كلما كان التأثير أفضل ، كلما طال وقت التفكير ؛ عند التعيين على 0 ، سيتم تخطي الانتشار وسيتم إخراج طيف MEL الذي تم إنشاؤه بواسطة FrameNcoder.
تحدد temperature مقدار الضوضاء المضافة عن طريق تفكير الانتشار ، وتحتاج إلى تصحيح أفضل قيمة.
قم بتنزيل الرابط الرسمي لبيانات Biaobei: https://www.data-baker.com/data/index/tntts/
ضع Waves في ./data/waves
ضع 000001-010000.txt في ./data/000001-010000.txt
إعادة تشكيل إلى 24 كيلو هرتز ، حيث يتم استخدام نموذج BigVgan 24K
أدوات Python/preprocess_a.py -w ./data/wave/-o ./data/wavs -s
24000
استخراج طيف MEL واستبدال Vocoder ، تحتاج إلى الانتباه إلى معلمات MEL المكتوبة في الكود.
أدوات Python/Preprocess_M.Py -بيانات/WAVS/ -بيانات/MELS/
استخراج متجه نطق BERT وإنشاء ملفات فهرس التدريب train.txt و valid.txt في نفس الوقت
أدوات Python/preprocess_b.py
يتضمن الإخراج data/berts/ والبيانات data/files
ملاحظة: معلومات الطباعة هي إزالة儿化音(المشروع هو عرضية خوارزمية ولا يقوم بالإنتاج)
تعليمات إضافية
التسمية الأصلية
000001 卡尔普#2陪外孙#1玩滑梯#4。
ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
000002 假语村言#2别再#1拥抱我#4。
jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3 يجب تمييزه لأن Bert يتطلب من الشخصيات الصينية卡尔普陪外孙玩滑梯。 (بما في ذلك علامات الترقيم) ، يتطلب TTS حرف العلة النهائي sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
000001 卡尔普陪外孙玩滑梯。
ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
000002 假语村言别再拥抱我。
jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3
sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp silتسمية التدريب
./data/wavs/000001.wav|./data/mels/000001.pt|./data/berts/000001.npy|sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
./data/wavs/000002.wav|./data/mels/000002.pt|./data/berts/000002.npy|sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp sil
هذه الجملة سترتكب خطأ
002365 这图#2难不成#2是#1P过的#4?
zhe4 tu2 nan2 bu4 cheng2 shi4 P IY1 guo4 de5
مجموعة بيانات التصحيح
أدوات Python/preprocess_d.py
ابدأ التدريب
Python Train.py
التدريب على الانتعاش
Python Train.py -P logs/new_exp/grad_tts _ ***. pt
Python inference.py -file test.txt -checkpoint ./logs/new_exp/grad_tts_***
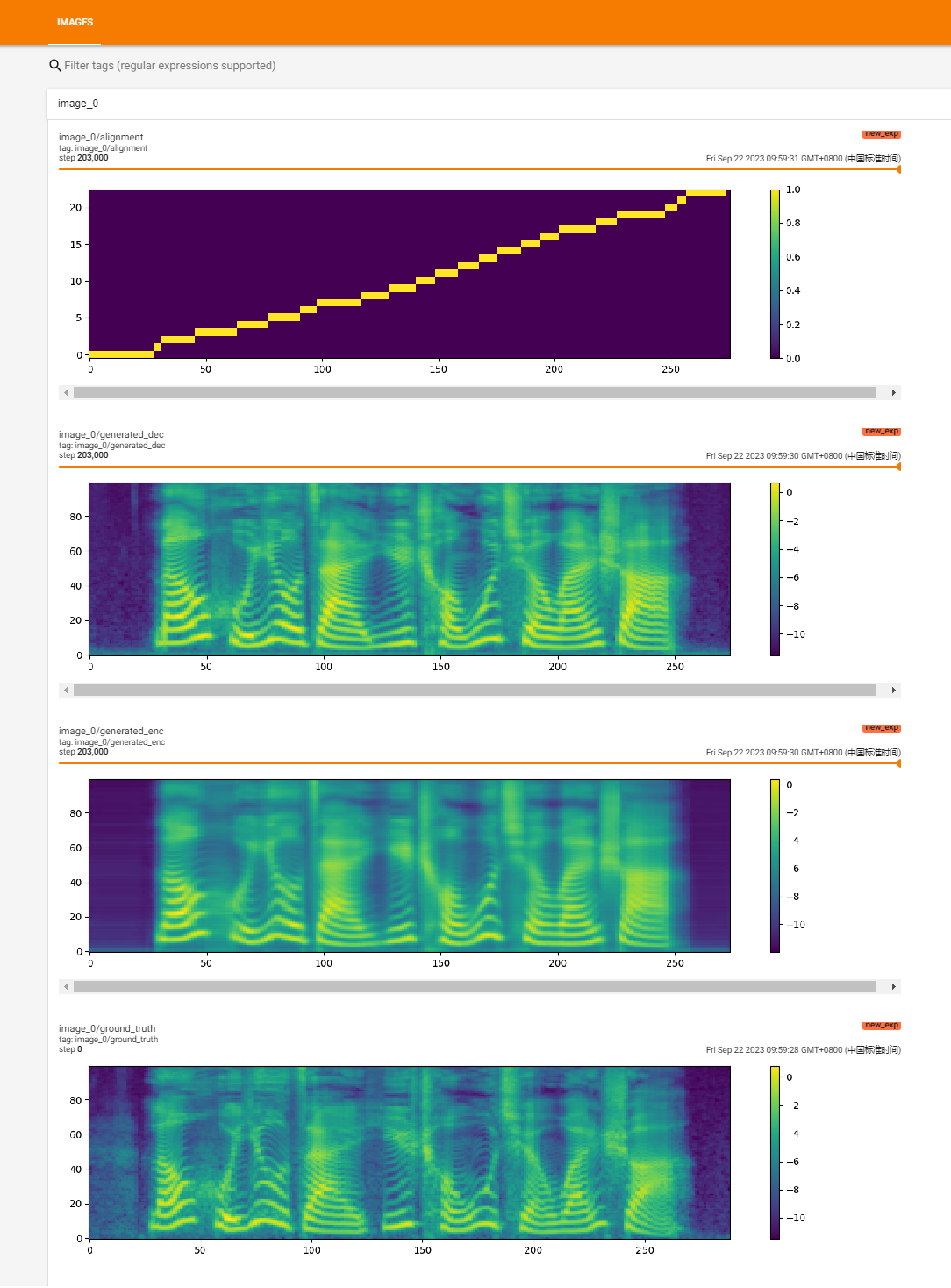
https://github.com/huawei-noah/speech-backbones/blob/main/grad-tts
https://github.com/shivammehta25/matcha-tts
https://github.com/thuhcsi/Lightgrad
https://github.com/executeone/chinese-fastspeade2
https://github.com/playvoice/vits_chinese
https://github.com/nvidia/bigvgan
التنفيذ الرسمي لنموذج Grad-TTS استنادًا إلى النمذجة الاحتمالية للانتشار. للحصول على جميع التفاصيل ، تحقق من مقبول ورقةنا في ICML 2021 عبر هذا الرابط.
المؤلفون : Vadim Popov*، Ivan Vovk*، Vladimir Gogoryan ، Tasnima Sadekova ، Mikhail Kudinov.
*مساهمة متساوية.
الصفحة التجريبية مع الخلاصة الصوتية: الرابط.
في الآونة الأخيرة ، أظهرت النماذج الاحتمالية لنشر الانتشار ومطابقة الدرجات المعممة إمكانات عالية في نمذجة توزيعات البيانات المعقدة في حين أن حساب العشوائي قد وفرت وجهة نظر موحدة حول هذه التقنيات مما يتيح مخططات الاستدلال المرنة. في هذه الورقة ، نقدم Grad-TTS ، وهو نموذج جديد من النص إلى كلام مع وحدة فك ترميز قائمة على النتيجة تنتج طيف MEL عن طريق تحويل الضوضاء تدريجياً التي تنبأ بها التشفير وتوافق مع مدخلات النص عن طريق البحث عن محاذاة رتابة. يساعدنا إطار المعادلات التفاضلية العشوائية على تعميم نماذج احتمال الاختلاف التقليدية لحالة إعادة بناء البيانات من الضوضاء مع معلمات مختلفة وتسمح لجعل عملية إعادة الإعمار هذه مرنة عن طريق التحكم الصريح بين جودة الصوت وسرعة الاستدلال. يوضح التقييم البشري الذاتي أن Grad-TTS تنافسية مع أساليب النص إلى الحديث الحديث من حيث متوسط درجة الرأي.
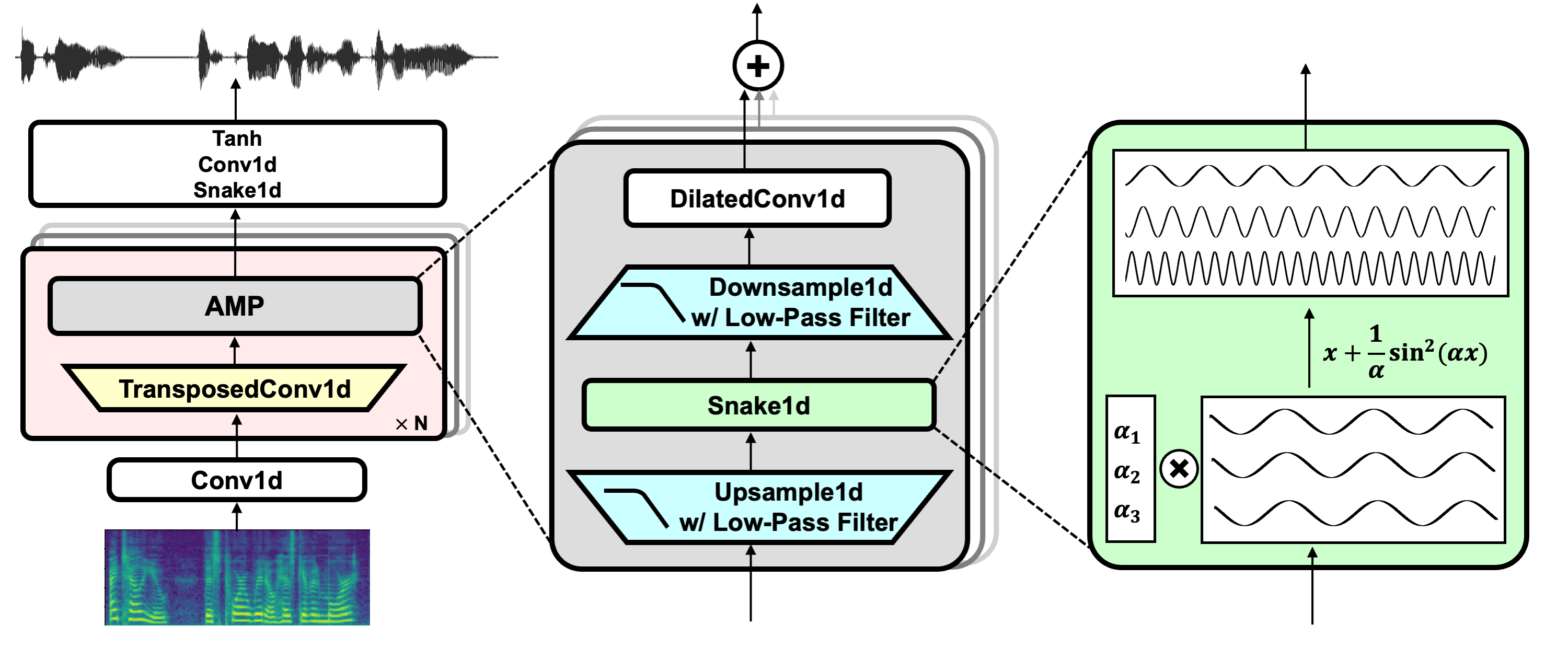
رابط المشروع: https://github.com/nvidia/bigvgan
تنزيل نموذج presrain bigvgan_base_24khz_100band
python bigvgan/inference.py
--input_wavs_dir bigvgan_debug
--output_dir bigvgan_outPython bigvgan/train.py -config bigvgan_pretrain/config.json
HIFI-GAN (للمولد والتمييز متعدد الفترات)
الأفعى (للتنشيط الدوري)
تلقائي معروف (لمكافحة التعيين)
يوليوس (لفلتر تمرير منخفض)
Univnet (للتمييز متعدد الدقة)


