Grad TTS Chinese
release grad-tts-cfm
TTS algorithm project for learning has slow in reasoning speed, but diffusion is a big trend
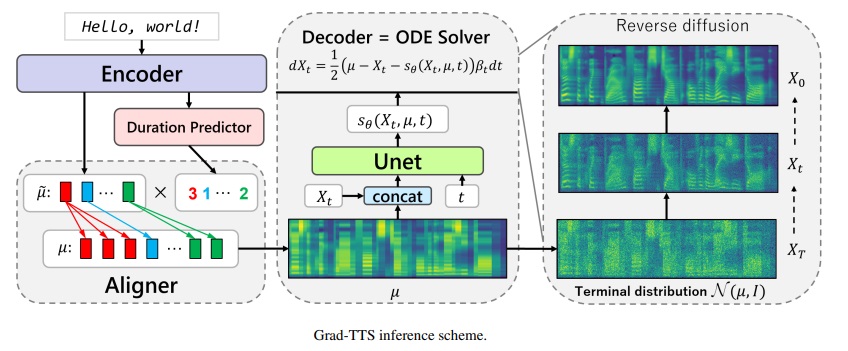
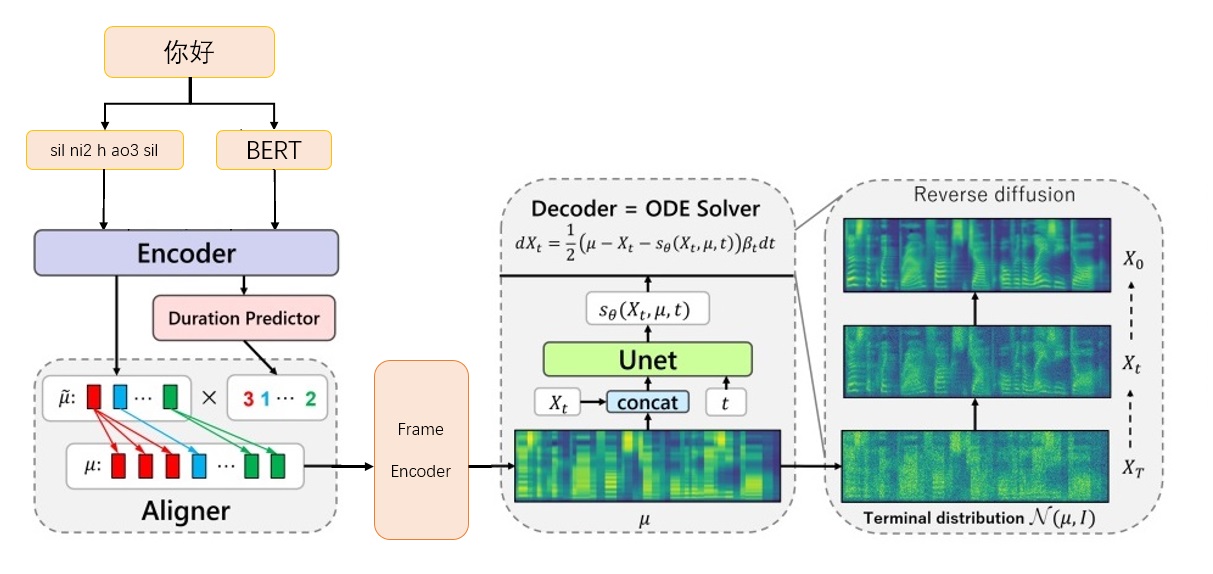 Grad-TTS-CFM Framework
Grad-TTS-CFM Framework
Download the vocoder model bigvgan_base_24khz_100band from NVIDIA/BigVGAN
Put g_05000000 in ./bigvgan_pretrain/g_0500000
Download BERT prosody_model from Executedone/Chinese-FastSpeech2
Rename best_model.pt to prosody_model.pt and put it in ./bert/prosody_model.pt
Download TTS model from Release page grad_tts.pt from release page
Put grad_tts.pt in the current directory, or anywhere
Installation environment dependency
pip install -r requirements.txt
cd ./grad/monotonic_align
python setup.py build_ext --inplace
cd -
Inference test
python inference.py --file test.txt --checkpoint grad_tts.pt --timesteps 10 --temperature 1.015
Generate audio in ./inference_out
The larger timesteps , the better the effect, the longer the reasoning time; when set to 0, the diffusion will be skipped and the mel spectrum generated by FrameEncoder will be output.
temperature determines the amount of noise added by diffusion reasoning, and needs to debug the best value.
Download the official link of Biaobei Data: https://www.data-baker.com/data/index/TNtts/
Put Waves in ./data/Waves
Put 000001-010000.txt in ./data/000001-010000.txt
Resampling to 24KHz, as BigVGAN 24K model is used
python tools/preprocess_a.py -w ./data/Wave/ -o ./data/wavs -s
24000
Extract the mel spectrum and replace the vocoder, you need to pay attention to the mel parameters written in the code.
python tools/preprocess_m.py --wav data/wavs/ --out data/mels/
Extract the BERT pronunciation vector and generate the training index files train.txt and valid.txt at the same time
python tools/preprocess_b.py
Output includes data/berts/ and data/files
Note: Printing information is to remove儿化音(the project is an algorithm demonstration and does not do production)
Additional Instructions
Original label
000001 卡尔普#2陪外孙#1玩滑梯#4。
ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
000002 假语村言#2别再#1拥抱我#4。
jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3 It needs to be marked as BERT requires Chinese characters卡尔普陪外孙玩滑梯。 (including punctuation), TTS requires the final vowel sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
000001 卡尔普陪外孙玩滑梯。
ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
000002 假语村言别再拥抱我。
jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3
sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp silTraining label
./data/wavs/000001.wav|./data/mels/000001.pt|./data/berts/000001.npy|sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
./data/wavs/000002.wav|./data/mels/000002.pt|./data/berts/000002.npy|sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp sil
This sentence will go wrong
002365 这图#2难不成#2是#1P过的#4?
zhe4 tu2 nan2 bu4 cheng2 shi4 P IY1 guo4 de5
Debug dataset
python tools/preprocess_d.py
Start training
python train.py
Recovery training
python train.py -p logs/new_exp/grad_tts_***.pt
python inference.py --file test.txt --checkpoint ./logs/new_exp/grad_tts_***.pt --timesteps 20 --temperature 1.15
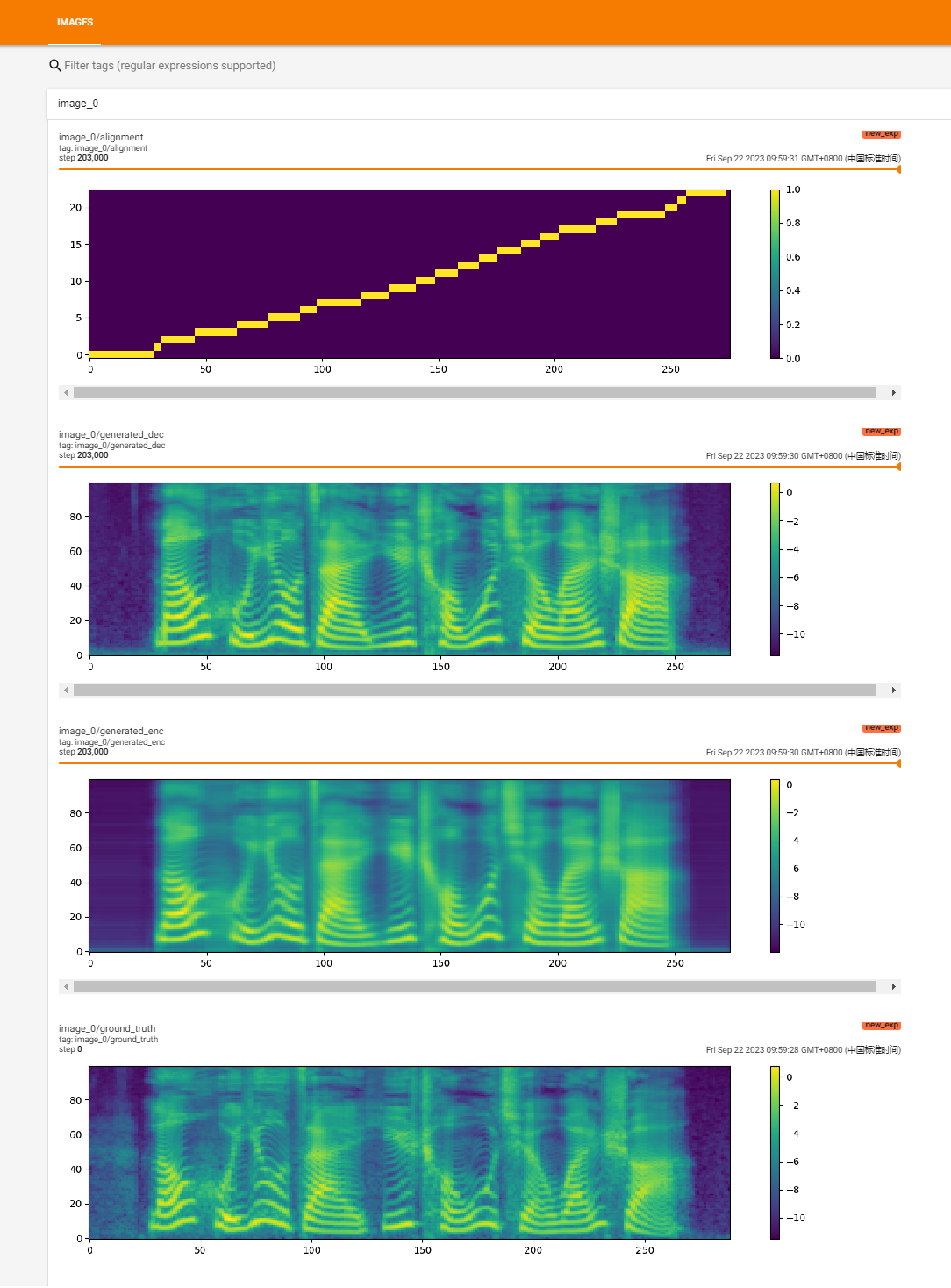
https://github.com/huawei-noah/Speech-Backbones/blob/main/Grad-TTS
https://github.com/shivammehta25/Matcha-TTS
https://github.com/thuhcsi/LightGrad
https://github.com/Executedone/Chinese-FastSpeech2
https://github.com/PlayVoice/vits_chinese
https://github.com/NVIDIA/BigVGAN
Official implementation of the Grad-TTS model based on Diffusion Probabilistic Modelling. For all details check out our paper accepted to ICML 2021 via this link.
Authors : Vadim Popov*, Ivan Vovk*, Vladimir Gogoryan, Tasnima Sadekova, Mikhail Kudinov.
*Equal contribution.
Demo page with voiced abstract: link.
Recently, denoising diffusion probabilistic models and generalized score matching have shown high potential in modelling complex data distributions while stochastic calculation has provided a unified point of view on these techniques allowing for flexible inference schemes. In this paper we introduce Grad-TTS, a novel text-to-speech model with score-based decoder producing mel-spectrograms by gradually transforming noise predicted by encoder and aligned with text input by means of Monotonic Alignment Search. The framework of stochastic differential equations helps us to generalize conventional difference probability models to the case of reconstructing data from noise with different parameters and allows to make this reconstruction flexible by explicitly controlling trade-off between sound quality and inference speed. Subjective human evaluation shows that Grad-TTS is competitive with state-of-the-art text-to-speech approaches in terms of Mean Opinion Score.
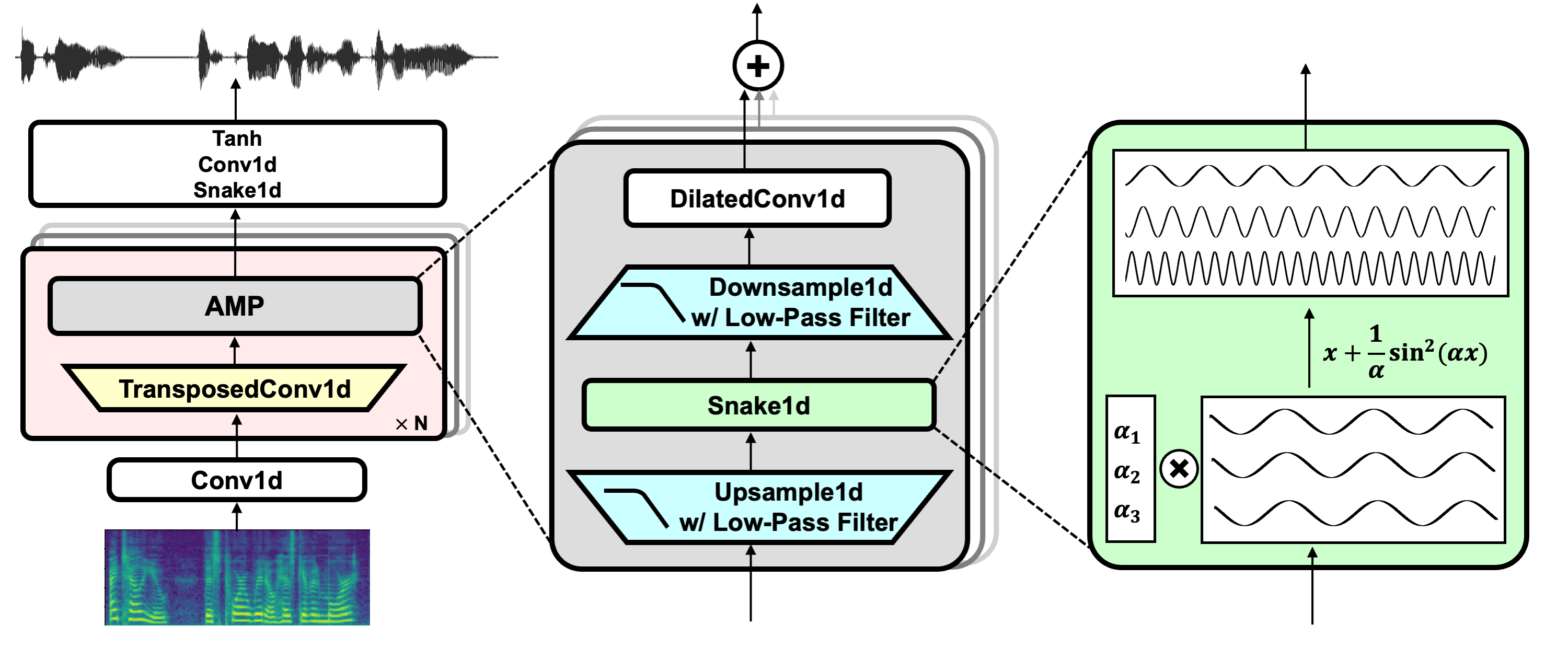
project link: https://github.com/NVIDIA/BigVGAN
download pretrain model bigvgan_base_24khz_100band
python bigvgan/inference.py
--input_wavs_dir bigvgan_debug
--output_dir bigvgan_outpython bigvgan/train.py --config bigvgan_pretrain/config.json
HiFi-GAN (for generator and multi-period discriminator)
Snake (for periodic activation)
Alias-free-torch (for anti-aliasing)
Julius (for low-pass filter)
UnivNet (for multi-resolution discriminator)


