Grad TTS Chinese
release grad-tts-cfm
El proyecto de algoritmo TTS para el aprendizaje tiene una velocidad de razonamiento lenta, pero la difusión es una gran tendencia
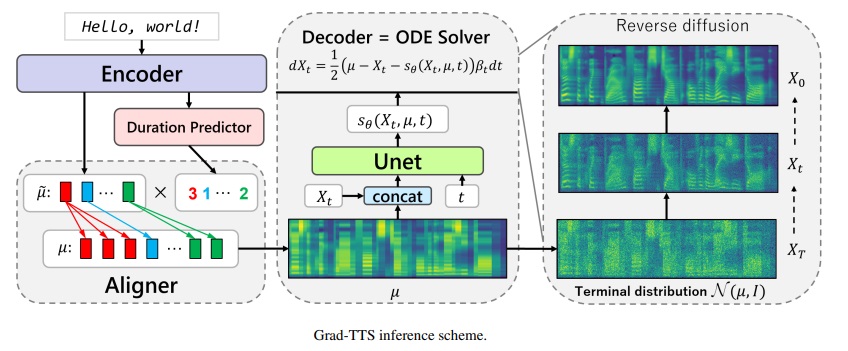
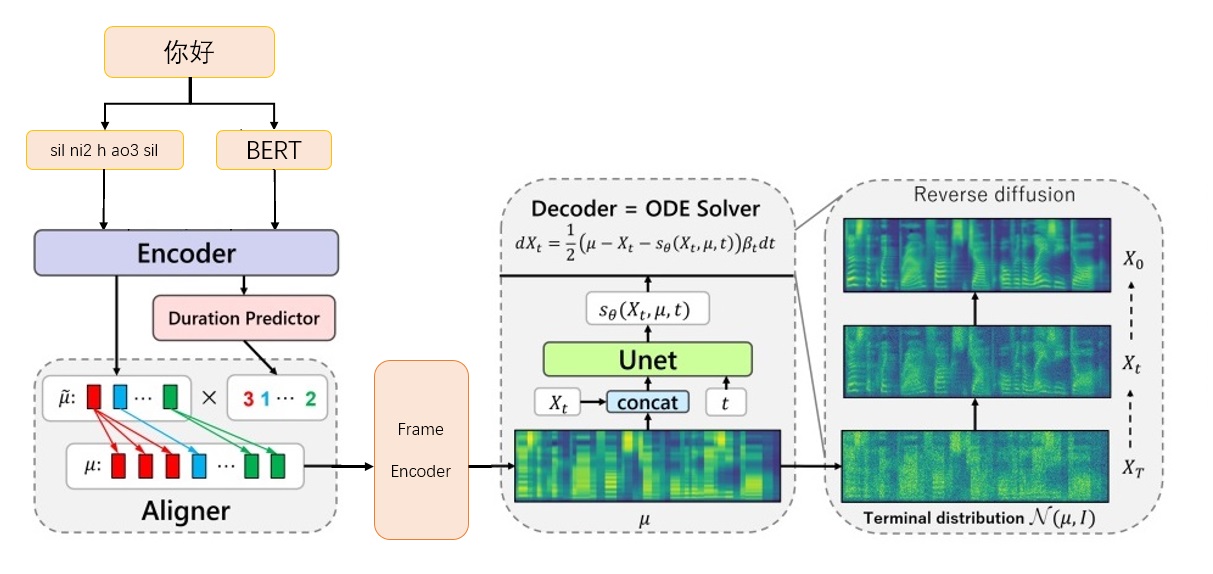 Marco Grad-TTS-CFM
Marco Grad-TTS-CFM
Descargue el modelo VOCODER bigvgan_base_24khz_100band desde nvidia/bigvgan
Pon G_05000000 en ./Bigvgan_Prain/G_0500000
Descargue Bert Prosody_Model de EjecutedOne/Chinese-FastSpeech2
Renombrar mejor_model.pt a prosody_model.pt y póngalo en ./bert/prosody_model.pt
Descargue el modelo TTS desde la página de lanzamiento grad_tts.pt desde la página de versión
Poner grad_tts.pt en el directorio actual, o en cualquier lugar
Dependencia del entorno de instalación
PIP install -r requisitos.txt
CD ./GRAD/Monotonic_align
Python setup.py build_ext -inplace
cd -
Prueba de inferencia
Python Inference.py - -File Test.txt --Checkpoint Grad_tts.pt - -Timesteps 10 - -Temperatura 1.015
Generar audio en ./inference_out
Cuanto más grande sea timesteps , mejor es el efecto, más largo es el tiempo de razonamiento; Cuando se establece en 0, se omitirá la difusión y se emitirá el espectro MEL generado por FrameEncoder.
temperature determina la cantidad de ruido agregado por el razonamiento de difusión y necesita depurar el mejor valor.
Descargue el enlace oficial de los datos de Biaobei: https://www.data-baker.com/data/index/tntts/
Poner Waves en ./data/waves
Poner 000001-010000.txt en ./data/000001-010000.txt
Volver a muestrear a 24 kHz, ya que se usa el modelo BigVgan 24K
Python Tools/Preprocess_a.py -w ./data/wave/ -o ./data/wavs -s
24000
Extraiga el espectro MEL y reemplace el Vocoder, debe prestar atención a los parámetros MEL escritos en el código.
Python Tools/Preprocess_m.py -Wavs Data/Wavs/--out data/mels/
Extraiga el vector de pronunciación de Bert y genere los archivos de índice de entrenamiento train.txt y valid.txt al mismo tiempo
Python Tools/Preprocess_B.Py
La salida incluye data/berts/ y data/files
Nota: La información de impresión es eliminar儿化音(el proyecto es una demostración de algoritmo y no realiza producción)
Instrucciones adicionales
Etiqueta original
000001 卡尔普#2陪外孙#1玩滑梯#4。
ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
000002 假语村言#2别再#1拥抱我#4。
jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3 Debe estar marcado ya que Bert requiere que los caracteres chinos卡尔普陪外孙玩滑梯。 (incluida la puntuación), TTS requiere la vocal final sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
000001 卡尔普陪外孙玩滑梯。
ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
000002 假语村言别再拥抱我。
jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3
sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp silEtiqueta de entrenamiento
./data/wavs/000001.wav|./data/mels/000001.pt|./data/berts/000001.npy|sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
./data/wavs/000002.wav|./data/mels/000002.pt|./data/berts/000002.npy|sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp sil
Esta oración cometerá un error
002365 这图#2难不成#2是#1P过的#4?
zhe4 tu2 nan2 bu4 cheng2 shi4 P IY1 guo4 de5
Conjunto de datos de depuración
Python Tools/Preprocess_D.Py
Comience el entrenamiento
Python Train.py
Capacitación de recuperación
Python Train.py -p logs/new_exp/grad_tts _ ***. PT
Python Inference.py --file test.txt --checkpoint ./logs/new_exp/grad_tts_***.pt ---Timesteps 20 - -Temperatura 1.15
https://github.com/huawei-noah/speech-backbones/blob/main/grad-tts
https://github.com/shivammehta25/matcha-tts
https://github.com/thuhcsi/lightgrad
https://github.com/executedone/chinese-stspeech2
https://github.com/playvoice/vits_chinesese
https://github.com/nvidia/bigvgan
Implementación oficial del modelo Grad-TTS basado en el modelado probabilístico de difusión. Para todos los detalles, consulte nuestro documento aceptado en ICML 2021 a través de este enlace.
Autores : Vadim Popov*, Ivan Vovk*, Vladimir GoGoryan, Tasnima Sadekova, Mikhail Kudinov.
*Contribución igual.
Página de demostración con resumen expresado: enlace.
Recientemente, los modelos probabilísticos de difusión de difusión y la coincidencia de puntaje generalizada han mostrado un alto potencial en el modelado de distribuciones de datos complejos, mientras que el cálculo estocástico ha proporcionado un punto de vista unificado sobre estas técnicas que permiten esquemas de inferencia flexibles. En este artículo presentamos Grad-TTS, un nuevo modelo de texto a voz con un decodificador basado en puntaje que produce espectrogramas MEL al transformar gradualmente el ruido predicho por el codificador y alineado con la entrada de texto por medio de la búsqueda de alineación monotónica. El marco de las ecuaciones diferenciales estocásticas nos ayuda a generalizar modelos de probabilidad de diferencia convencional al caso de reconstruir datos del ruido con diferentes parámetros y permite hacer que esta reconstrucción sea flexible controlando explícitamente la compensación entre la calidad del sonido y la velocidad de inferencia. La evaluación humana subjetiva muestra que Grad-TTS es competitivo con los enfoques de texto a voz de vanguardia en términos de puntaje de opinión media.
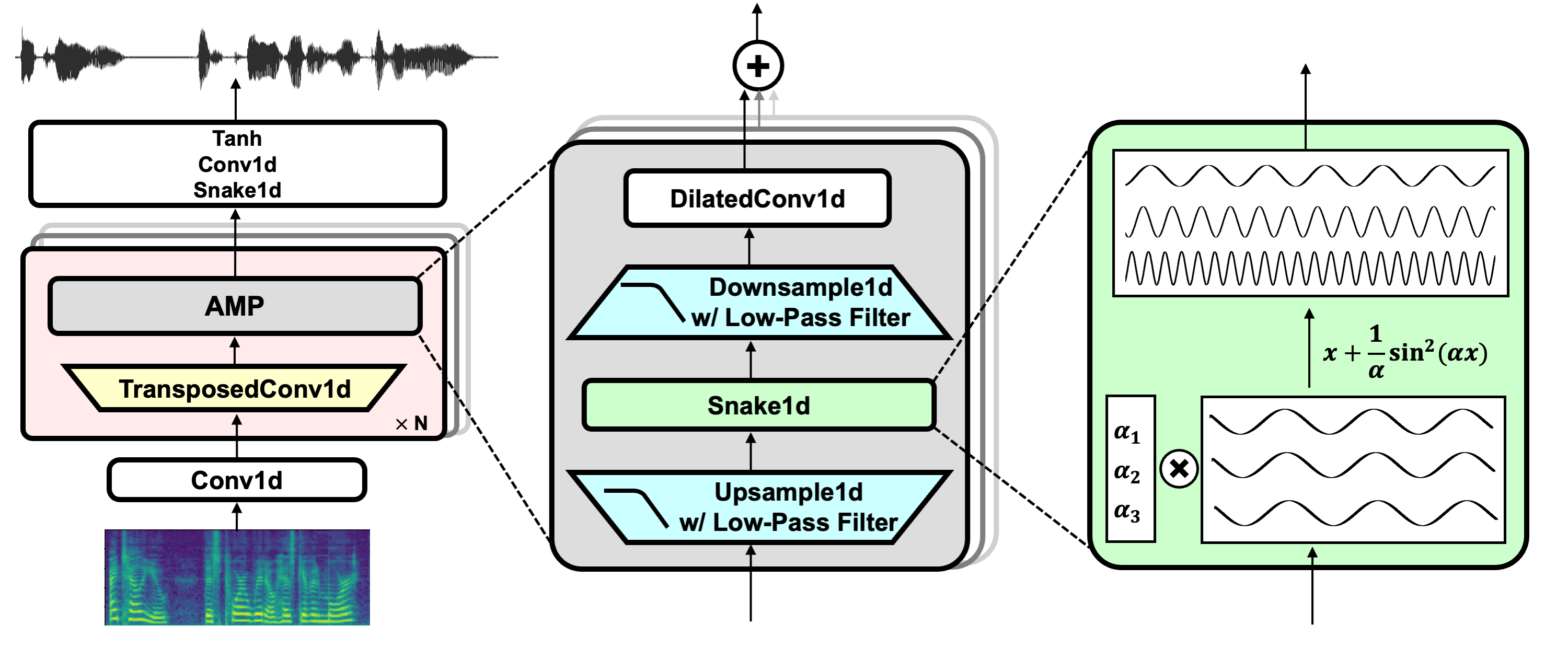
Enlace del proyecto: https://github.com/nvidia/bigvgan
Descargar el modelo Pretrin BigVgan_base_24khz_100band
python bigvgan/inference.py
--input_wavs_dir bigvgan_debug
--output_dir bigvgan_outPython Bigvgan/Train.py - -Config BigVgan_pretrain/config.json
Hifi-Gan (para generador y discriminador de múltiples períodos)
Serpiente (para activación periódica)
Torch sin alias (para anti-aliasing)
Julius (para filtro de paso bajo)
Univnet (para discriminador de resolución múltiple)


