Grad TTS Chinese
release grad-tts-cfm
Proyek algoritma TTS untuk belajar memiliki kecepatan penalaran yang lambat, tetapi difusi adalah tren besar
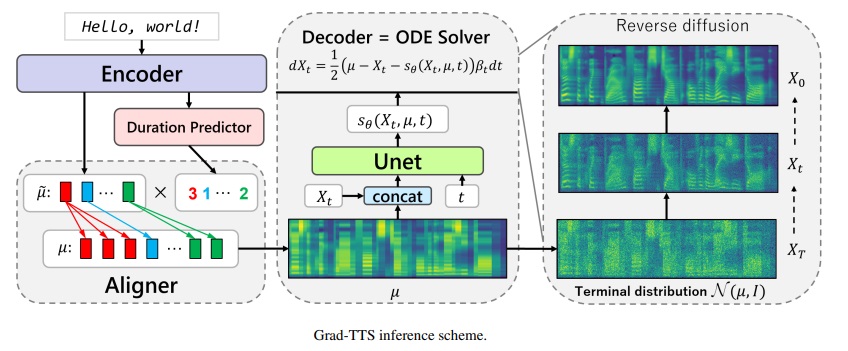
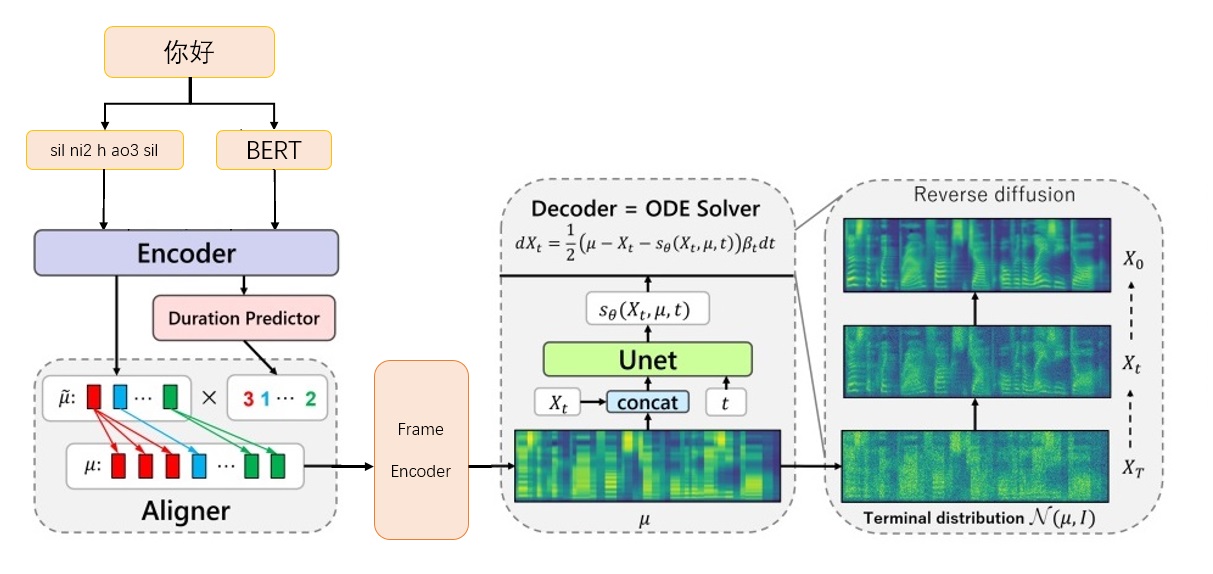 Kerangka Lulusan-TTS-CFM
Kerangka Lulusan-TTS-CFM
Unduh model vokoder bigvgan_base_24khz_100band dari nvidia/bigvgan
Masukkan g_05000000 di ./bigvgan_praTrain/g_0500000
Unduh Bert Prosody_Model dari ExecutedOne/China-FastSpeech2
Ganti nama terbaik_model.pt ke prosody_model.pt dan masukkan ke dalam ./bert/prosody_model.pt
Unduh model TTS dari halaman rilis grad_tts.pt dari halaman rilis
Letakkan grad_tts.pt di direktori saat ini, atau di mana saja
Ketergantungan Lingkungan Instalasi
Pip instal -r persyaratan.txt
cd ./grad/monotonic_align
python setup.py build_ext - -di tempat
CD -
Tes inferensi
python inference.py --file test.txt --checkpoint grad_tts.pts.pts.Timesteps 10 -Temperature 1.015
Hasilkan audio di ./inference_out
Semakin besar timesteps , semakin baik efeknya, semakin lama waktu penalaran; Saat diatur ke 0, difusi akan dilewati dan spektrum MEL yang dihasilkan oleh FrameCoder akan menjadi output.
temperature menentukan jumlah kebisingan yang ditambahkan oleh penalaran difusi, dan perlu men -debug nilai terbaik.
Unduh Tautan Resmi Data Biaobei: https://www.data-baker.com/data/index/tntts/
Masukkan Waves di ./data/waves
Letakkan 000001-010000.txt di ./data/000001-010000.txt
Resampling ke 24kHz, karena model Bigvgan 24K digunakan
Python Tools/Preprocess_a.py -w ./data/wave/ -o ./data/wavs -s
24000
Ekstrak spektrum MEL dan ganti vocoder, Anda perlu memperhatikan parameter Mel yang ditulis dalam kode.
Python Tools/Preprocess_m.py -Wav Data/WAVS/ - -Out Data/MELS/
Ekstrak vektor pengucapan Bert dan hasilkan file indeks pelatihan train.txt dan valid.txt pada saat yang sama
Python Tools/Preprocess_b.py
Output mencakup data/berts/ dan data/files
CATATAN: Informasi pencetakan adalah untuk menghapus儿化音(proyek ini merupakan demonstrasi algoritma dan tidak melakukan produksi)
Instruksi tambahan
Label asli
000001 卡尔普#2陪外孙#1玩滑梯#4。
ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
000002 假语村言#2别再#1拥抱我#4。
jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3 Perlu ditandai karena Bert membutuhkan karakter Cina卡尔普陪外孙玩滑梯。 (termasuk tanda baca), TTS membutuhkan vokal terakhir sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
000001 卡尔普陪外孙玩滑梯。
ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
000002 假语村言别再拥抱我。
jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3
sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp silLabel pelatihan
./data/wavs/000001.wav|./data/mels/000001.pt|./data/berts/000001.npy|sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
./data/wavs/000002.wav|./data/mels/000002.pt|./data/berts/000002.npy|sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp sil
Kalimat ini akan membuat kesalahan
002365 这图#2难不成#2是#1P过的#4?
zhe4 tu2 nan2 bu4 cheng2 shi4 P IY1 guo4 de5
DEBUG Dataset
Python Tools/Preprocess_d.py
Mulai pelatihan
python train.py
Pelatihan Pemulihan
python train.py -p log/new_exp/grad_tts _ ***. pt
python inference.py --file test.txt --checkpoint ./logs/new_exp/grad_tts_***.pt --Timesteps 20 - -Temperature 1.15
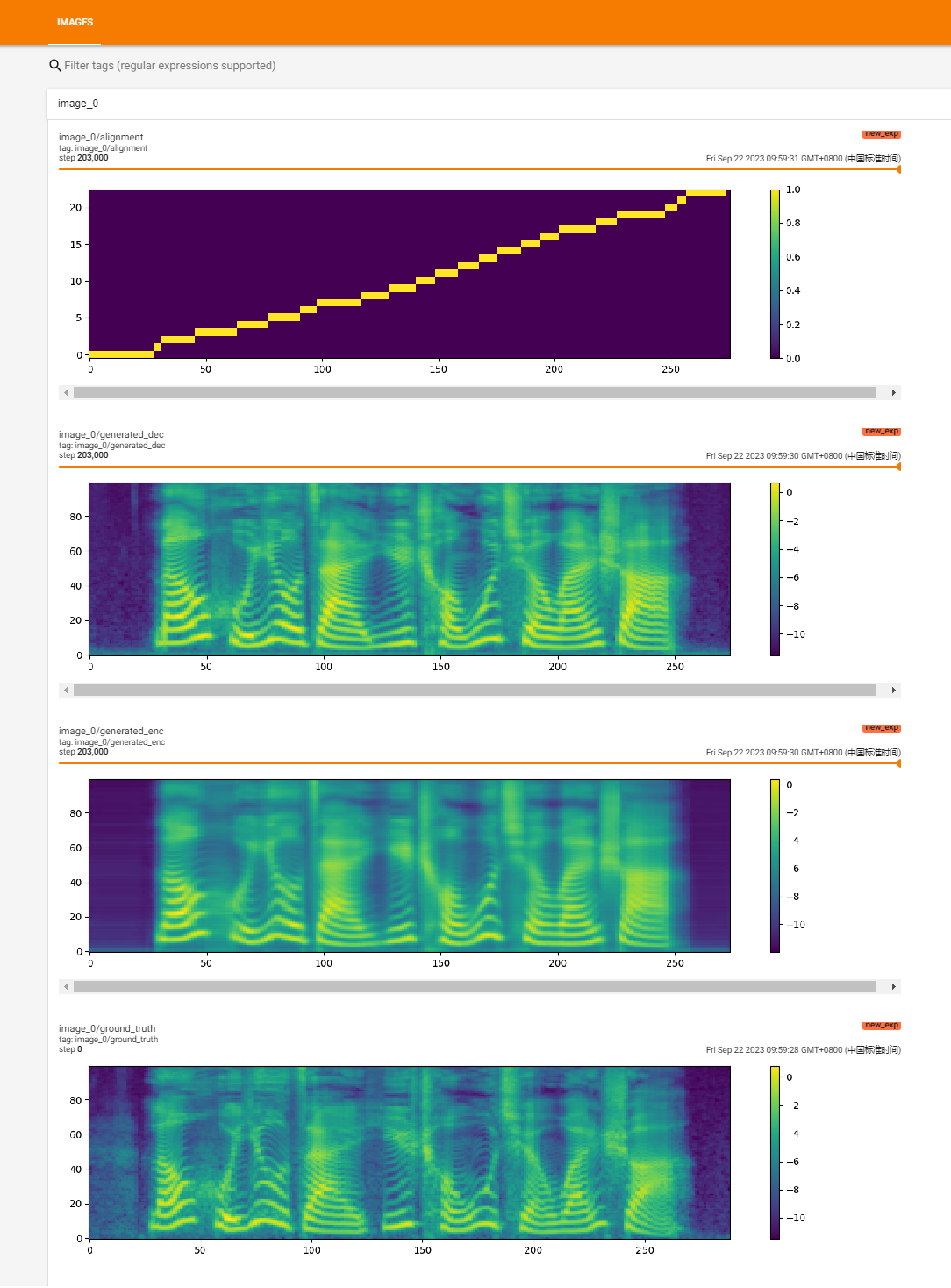
https://github.com/huawei-noah/speech-backbones/blob/main/grad-tts
https://github.com/shivammehta25/matcha-tts
https://github.com/thuhcsi/lightgrad
https://github.com/executedone/chinese-fastspeech2
https://github.com/playvoice/vits_chinese
https://github.com/nvidia/bigvgan
Implementasi resmi model Grad-TTS berdasarkan pemodelan probabilistik difusi. Untuk semua detail, lihat makalah kami yang diterima di ICML 2021 melalui tautan ini.
Penulis : Vadim Popov*, Ivan Vovk*, Vladimir Gogoryan, Tasnima Sadekova, Mikhail Kudinov.
*Kontribusi yang sama.
Halaman demo dengan abstrak bersuara: tautan.
Baru -baru ini, model probabilistik difusi denoising dan pencocokan skor umum telah menunjukkan potensi tinggi dalam pemodelan distribusi data kompleks sementara perhitungan stokastik telah memberikan sudut pandang terpadu pada teknik -teknik ini yang memungkinkan skema inferensi yang fleksibel. Dalam makalah ini kami memperkenalkan Grad-TTS, model teks-ke-speech baru dengan dekoder berbasis skor yang menghasilkan Mel-spectrograms dengan secara bertahap mengubah noise yang diprediksi oleh encoder dan disejajarkan dengan input teks dengan menggunakan pencarian penyelarasan monotonik. Kerangka kerja persamaan diferensial stokastik membantu kita untuk menggeneralisasi model probabilitas perbedaan konvensional untuk kasus merekonstruksi data dari noise dengan parameter yang berbeda dan memungkinkan untuk membuat rekonstruksi ini fleksibel dengan secara eksplisit mengendalikan pertukaran antara kualitas suara dan kecepatan inferensi. Evaluasi manusia subyektif menunjukkan bahwa Grad-TTS kompetitif dengan pendekatan teks-ke-ucapan canggih dalam hal skor opini rata-rata.
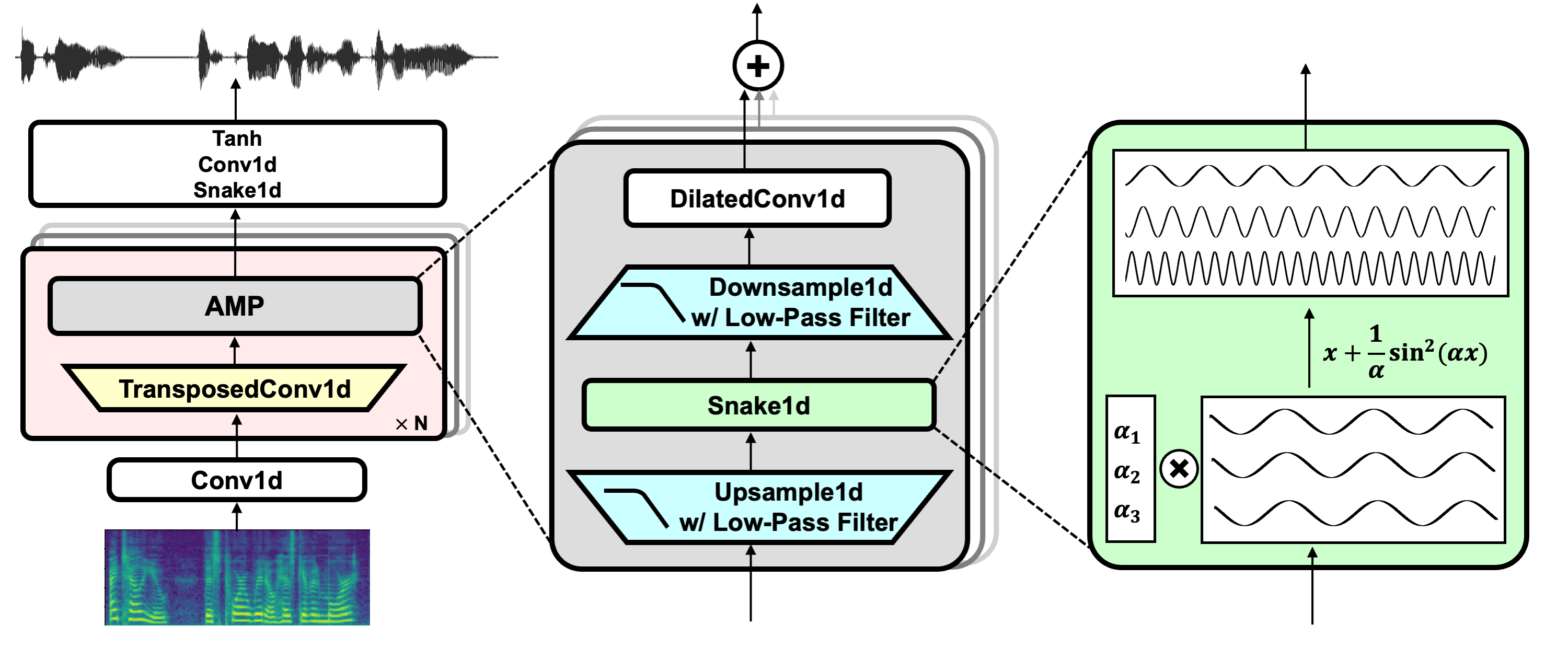
Tautan Proyek: https://github.com/nvidia/bigvgan
Unduh model pretrain bigvgan_base_24khz_100band
python bigvgan/inference.py
--input_wavs_dir bigvgan_debug
--output_dir bigvgan_outPython bigvgan/train.py --config Bigvgan_pretrain/config.json
HIFI-GAN (untuk Diskriminator Generator dan Multi-Periode)
Ular (untuk aktivasi berkala)
Alias-Free-Torch (untuk anti-aliasing)
Julius (untuk filter low-pass)
Univnet (untuk Diskriminator Multi-Resolusi)


