Grad TTS Chinese
release grad-tts-cfm
学習用のTTSアルゴリズムプロジェクトの推論速度は遅いですが、拡散は大きな傾向です
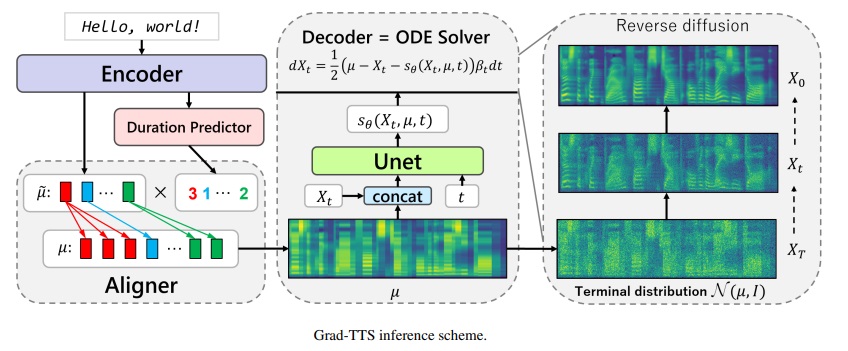
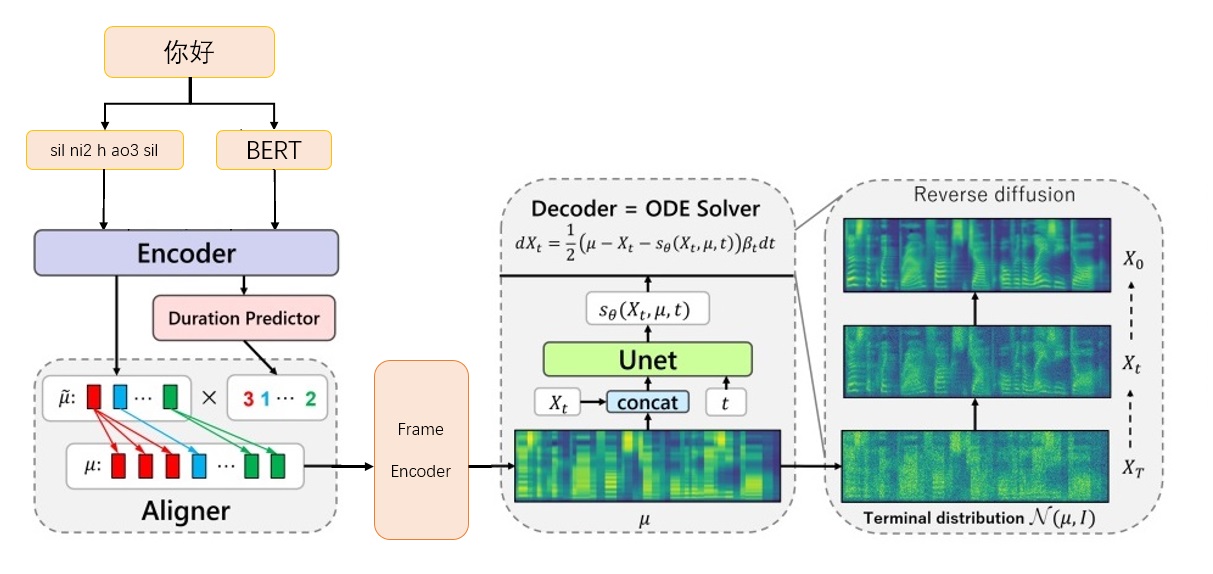 grad-tts-cfmフレームワーク
grad-tts-cfmフレームワーク
nvidia/bigvganからボコーダーモデルbigvgan_base_24khz_100bandをダウンロードします
g_05000000を./bigvgan_pretrain/g_0500000に入れます
executeDone/中国語fastspeech2からbert prosody_modelをダウンロードします
best_model.ptをprosody_model.ptに変更し、それを./bert/prosody_model.ptに入れます
リリースページgred_tts.ptからリリースページからTTSモデルをダウンロードする
現在のディレクトリまたはどこにでもgrad_tts.ptを入れます
インストール環境依存関係
PIPインストール-R要件。txt
cd ./grad/monotonic_align
python setup.py build_ext - インプレース
CD -
推論テスト
python inconference.py - file test.txt -checkpoint grad_tts.pt - timesteps 10 - temperature 1.015
./inference_outでオーディオを生成します。/inference_out
timestepsが大きいほど、効果が良くなるほど、推論時間が長くなります。 0に設定すると、拡散がスキップされ、フレームコダーによって生成されたMELスペクトルが出力されます。
temperature 、拡散推論によって追加されるノイズの量を決定し、最高の値をデバッグする必要があります。
biaobeiデータの公式リンクをダウンロード:https://www.data-baker.com/data/index/tntts/
Waves ./Data/Wavesに入れます
000001-010000.txtを./data/000001-010000.txtに入れます
BigVgan 24Kモデルが使用されるため、24kHzに再サンプリングします
python tools/preprocess_a.py -w ./data/wave/ -o ./data/wavs -s
24000
MELスペクトルを抽出し、ボコーダーを交換すると、コードに記載されているMELパラメーターに注意を払う必要があります。
python tools/preprocess_m.py-wav data/wavs/--out data/mels/
Bert発音ベクトルを抽出し、トレーニングインデックスファイルtrain.txtとvalid.txtを同時に生成します
Python Tools/Preprocess_b.py
出力には、 data/berts/およびdata/filesが含まれます
注:情報の印刷は儿化音削除することです(プロジェクトはアルゴリズムのデモンストレーションであり、制作を行いません)
追加の指示
オリジナルのラベル
000001 卡尔普#2陪外孙#1玩滑梯#4。
ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
000002 假语村言#2别再#1拥抱我#4。
jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3 Bertは漢字卡尔普陪外孙玩滑梯。 (句読点を含む)、TTSは最終的な母音sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil必要とします
000001 卡尔普陪外孙玩滑梯。
ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
000002 假语村言别再拥抱我。
jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3
sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp silトレーニングラベル
./data/wavs/000001.wav|./data/mels/000001.pt|./data/berts/000001.npy|sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
./data/wavs/000002.wav|./data/mels/000002.pt|./data/berts/000002.npy|sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp sil
この文は間違っています
002365 这图#2难不成#2是#1P过的#4?
zhe4 tu2 nan2 bu4 cheng2 shi4 P IY1 guo4 de5
デバッグデータセット
Python Tools/Preprocess_d.py
トレーニングを開始します
Python Train.py
回復トレーニング
python train.py -p logs/new_exp/grad_tts _ ***。pt
python inconference.py - file test.txt -checkpoint ./logs/new_exp/grad_tts_***.pt - Timesteps 20 - temperature 1.15
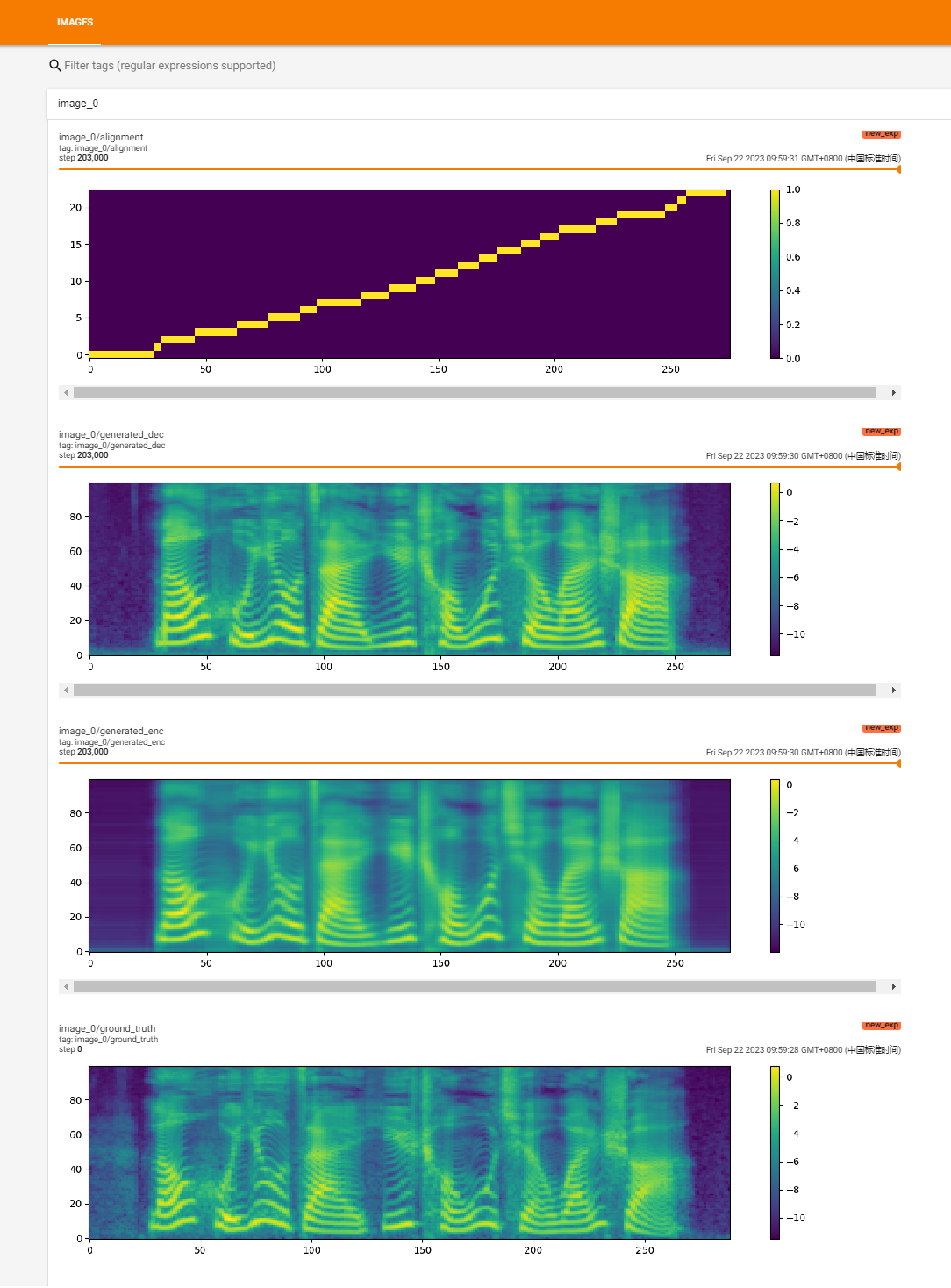
https://github.com/huawei-noah/speech-backbones/blob/main/grad-tts
https://github.com/shivammehta25/matcha-tts
https://github.com/thuhcsi/lightgrad
https://github.com/executedone/chinese-fastspeech2
https://github.com/playvoice/vits_chinese
https://github.com/nvidia/bigvgan
拡散確率モデリングに基づくGradTTSモデルの公式実装。すべての詳細については、このリンクを介してICML 2021に受け入れられた論文をご覧ください。
著者:Vadim Popov*、Ivan Vovk*、Vladimir Gogoryan、Tasnima Sadekova、Mikhail Kudinov。
*平等な貢献。
Abited Abstract:リンク付きデモページ。
最近、拡散確率モデルと一般化されたスコアマッチングの形成は、複雑なデータ分布のモデリングで高い可能性を示していますが、確率計算により、これらの手法に関する統一された視点が提供され、柔軟な推論スキームが可能になりました。このペーパーでは、エンコーダーによって予測され、単調なアライメント検索によってテキスト入力と整列するノイズを徐々に変換することにより、スコアベースのデコーダーを生成する新しいテキストからスピーチモデルを備えた新しいテキストからスピーチモデルであるGrad-TTSを紹介します。確率的微分方程式のフレームワークは、異なるパラメーターでノイズからデータを再構築する場合に従来の差確率モデルを一般化するのに役立ち、音質と推論速度の間のトレードオフを明示的に制御することにより、この再構成を柔軟にすることができます。主観的な人間の評価は、GradTTSが平均意見スコアの観点から最先端のテキストからスピーチへのアプローチと競争力があることを示しています。
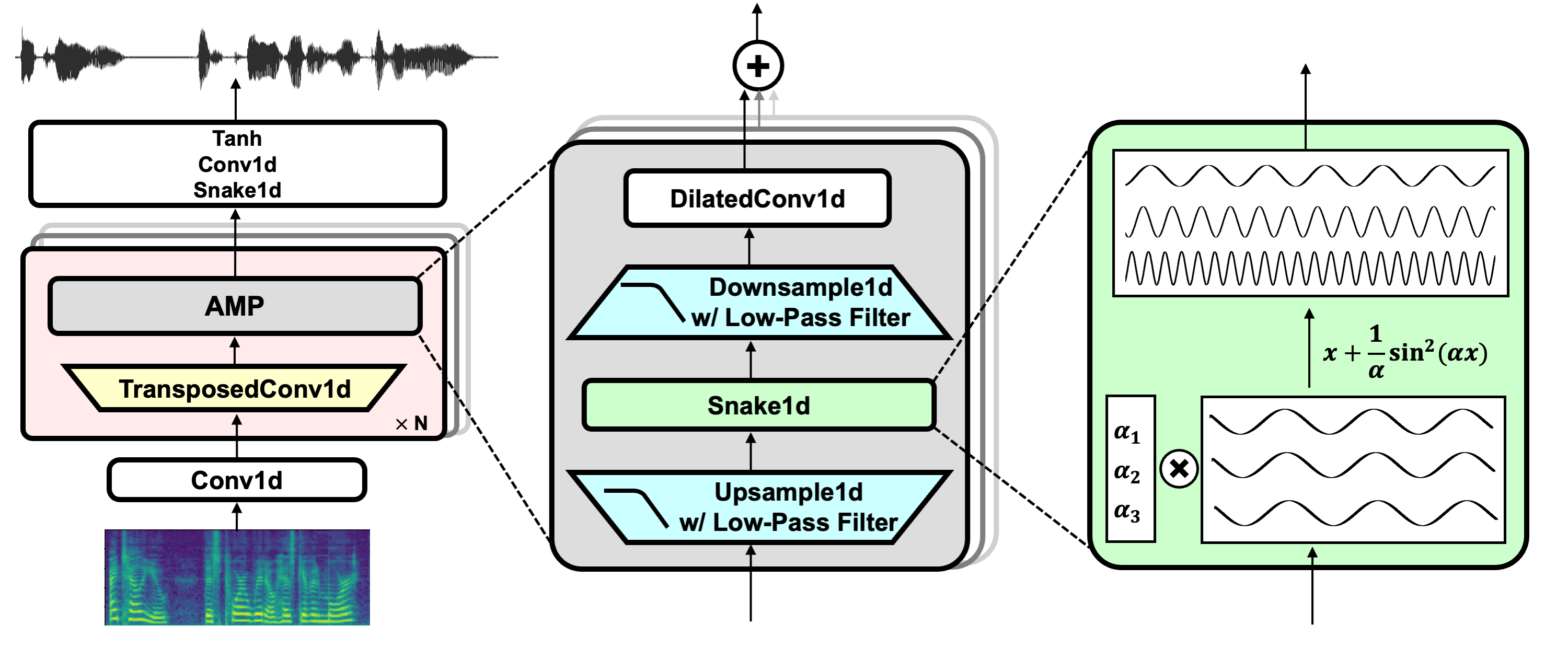
プロジェクトリンク:https://github.com/nvidia/bigvgan
プレトレインモデルbigvgan_base_24khz_100bandをダウンロードします
python bigvgan/inference.py
--input_wavs_dir bigvgan_debug
--output_dir bigvgan_outpython bigvgan/train.py -config bigvgan_pretrain/config.json
Hifi-gan(ジェネレーターと多周期識別器用)
ヘビ(定期的な活性化用)
エイリアスフリートーチ(アンチアリアシング用)
ジュリアス(ローパスフィルター用)
univnet(多解像度の識別器用)


