Grad TTS Chinese
release grad-tts-cfm
Проект алгоритма TTS для обучения медленной скоростью рассуждения, но диффузия является большой тенденцией
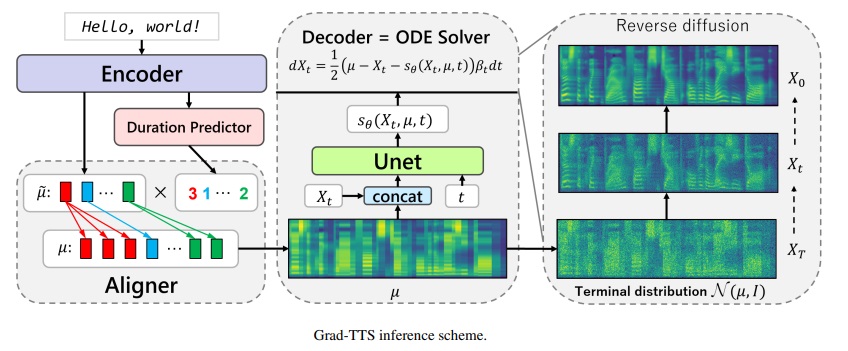
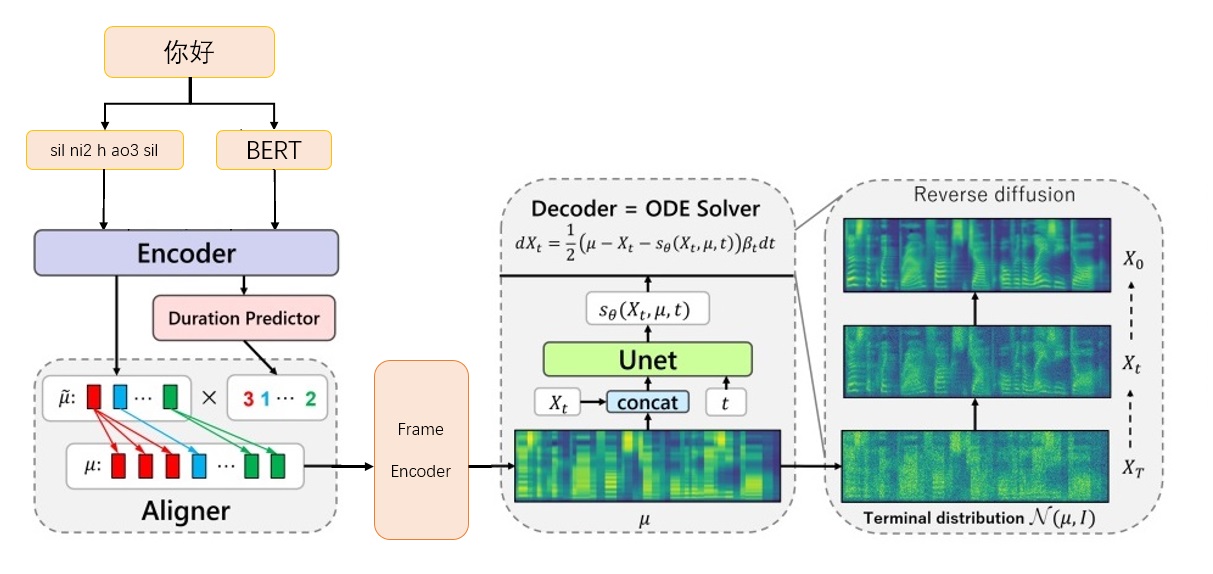 Grad-TTS-CFM Framework
Grad-TTS-CFM Framework
Загрузите модель Vocoder BIGVGAN_BASE_24KHZ_100BAND от NVIDIA/BIGVGAN
Поместите g_05000000 в ./bigvgan_pretrain/g_0500000
Скачать bert prosody_model из cerfedOne/cilina-fastspeech2
Rename best_model.pt в prosody_model.pt и поместите его в ./bert/prosody_model.pt
Скачать модель TTS с страницы релиза grad_tts.pt со страницы релиза
Поместите grad_tts.pt в текущий каталог или в любом месте
Зависимость среды установки
PIP установка -R TEDS.TXT
CD ./grad/monotonic_align
python setup.py build_ext -inplace
CD -
Тест вывода
Python uperence.py -file test.txt -checkpoint grad_tts.pt -timesteps 10 -Температура 1.015
Генерировать аудио в ./inference_out
Чем больше timesteps , тем лучше эффект, тем дольше время рассуждения; Когда установлено на 0, диффузия будет пропущена, а спектр MEL, сгенерированный RameenceDer, будет выходить.
temperature определяет количество шума, добавляемого рассуждением диффузии, и необходимо отлаживать наилучшее значение.
Загрузите официальную ссылку Biobei Data: https://www.data-baker.com/data/index/tntts/
Положить Waves в ./data/waves
Поместите 000001-010000.txt in ./data/000001-010000.txt
Повторная выборка до 24 кГц, как используется модель Bigvgan 24K
Python Tools/preprocess_a.py -w ./data/wave/ -o ./data/wavs -s
24000
Извлеките спектр MEL и замените Vocoder, вам необходимо обратить внимание на параметры MEL, написанные в коде.
Python Tools/Preprocess_m.py -Wav Data/WAVS/ - - -из -за данных/MELS/
Извлеките вектор произношения BERT и генерируйте файлы индекса обучения train.txt и valid.txt одновременно
Python Tools/preprocess_b.py
Вывод включает data/berts/ и data/files
Примечание儿化音
Дополнительные инструкции
Оригинальный лейбл
000001 卡尔普#2陪外孙#1玩滑梯#4。
ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
000002 假语村言#2别再#1拥抱我#4。
jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3 Это должно быть отмечено, когда Берт требует, чтобы китайские иероглифы卡尔普陪外孙玩滑梯。 (включая пунктуацию), TTS требует окончательного гласного sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
000001 卡尔普陪外孙玩滑梯。
ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
000002 假语村言别再拥抱我。
jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3
sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp silУчебный лейбл
./data/wavs/000001.wav|./data/mels/000001.pt|./data/berts/000001.npy|sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
./data/wavs/000002.wav|./data/mels/000002.pt|./data/berts/000002.npy|sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp sil
Это предложение допустит ошибку
002365 这图#2难不成#2是#1P过的#4?
zhe4 tu2 nan2 bu4 cheng2 shi4 P IY1 guo4 de5
Набор данных отладки
Python Tools/Preprocess_d.py
Начать обучение
Python Train.py
Восстановление обучение
python train.py -p logs/new_exp/grad_tts _ ***. Pt
python uperence.py -file test.txt -checkpoint ./logs/new_exp/grad_tts_***.pt -timesteps 20 -temperature 1.15
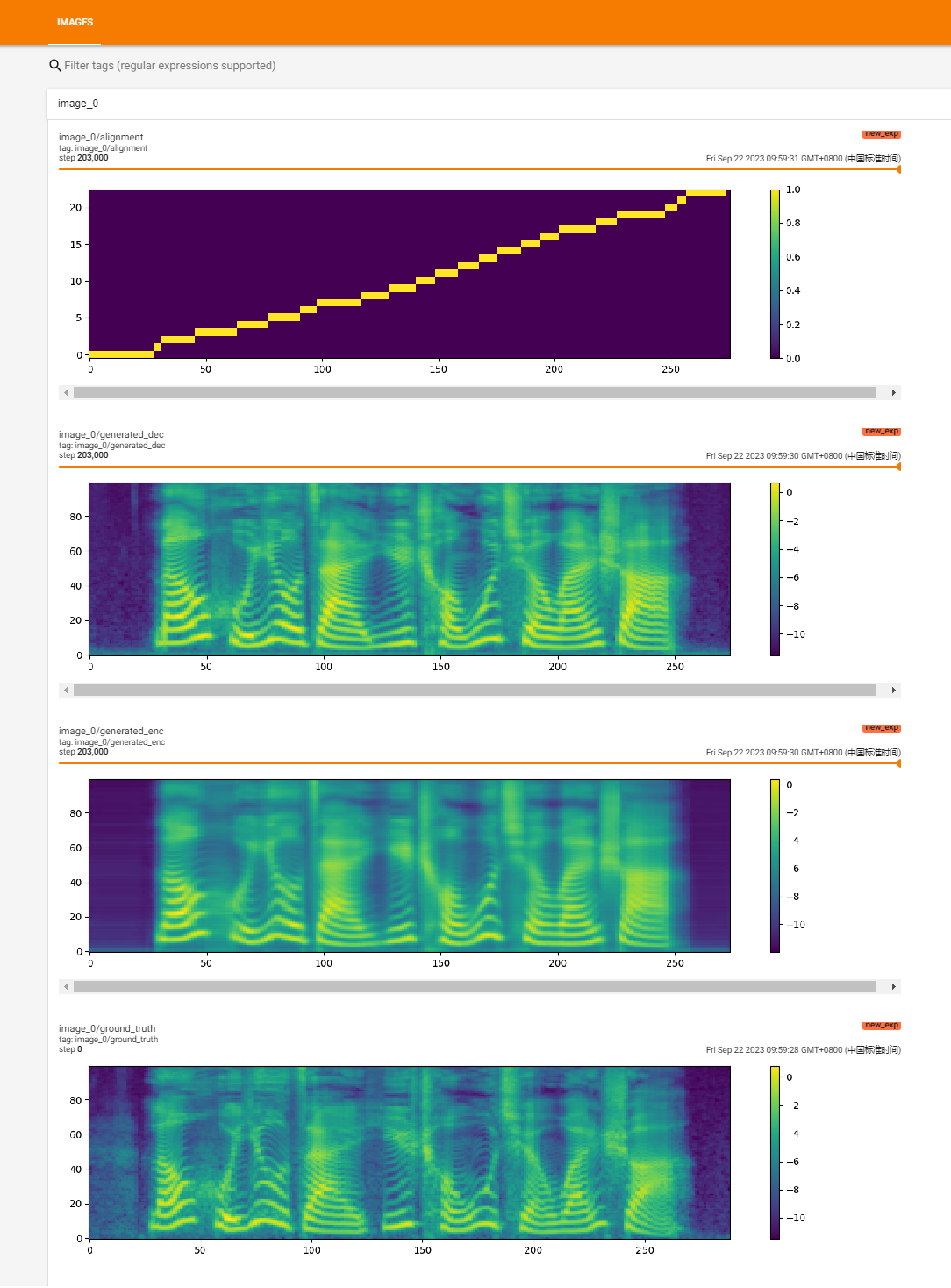
https://github.com/huawei-noah/speech-backbones/blob/main/grady-tts
https://github.com/shivammehta25/matcha-tts
https://github.com/thuhcsi/lightgradgr
https://github.com/execatedone/chinese-fastspeech2
https://github.com/playvoice/vits_chinese
https://github.com/nvidia/bigvgan
Официальная реализация модели Grad-TTS на основе диффузионного вероятностного моделирования. Для всех деталей ознакомьтесь с нашей статьей, принятой в ICML 2021 по этой ссылке.
Авторы : Вадим Попов*, Иван Вовк*, Владимир Гогориан, Таснима Садекова, Михаил Кудинов.
*Равный вклад.
Демо -страница с озвученной рефератом: ссылка.
В последнее время, вероятно, доносительные диффузионные вероятностные модели и обобщенное сопоставление баллов показали высокий потенциал в моделировании сложных распределений данных, в то время как стохастическое расчет обеспечил единую точку зрения на эти методы, позволяющие для гибких схем вывода. В этой статье мы вводим Grad-TTS, новую модель текста в речь с декодером на основе баллов, производящей мель-спектрограммы путем постепенного преобразования шума, прогнозируемого Encoder и выровненным с вводом текста с помощью монотонного поиска выравнивания. Структура стохастических дифференциальных уравнений помогает нам обобщать обычные модели вероятности различий в случае реконструкции данных из шума с различными параметрами и позволяет сделать эту реконструкцию гибкой, явно контролируя компромисс между качеством звука и скоростью вывода. Субъективная человеческая оценка показывает, что Grad-TTS конкурентоспособен с современными подходами текста в речь с точки зрения среднего балла мнений.
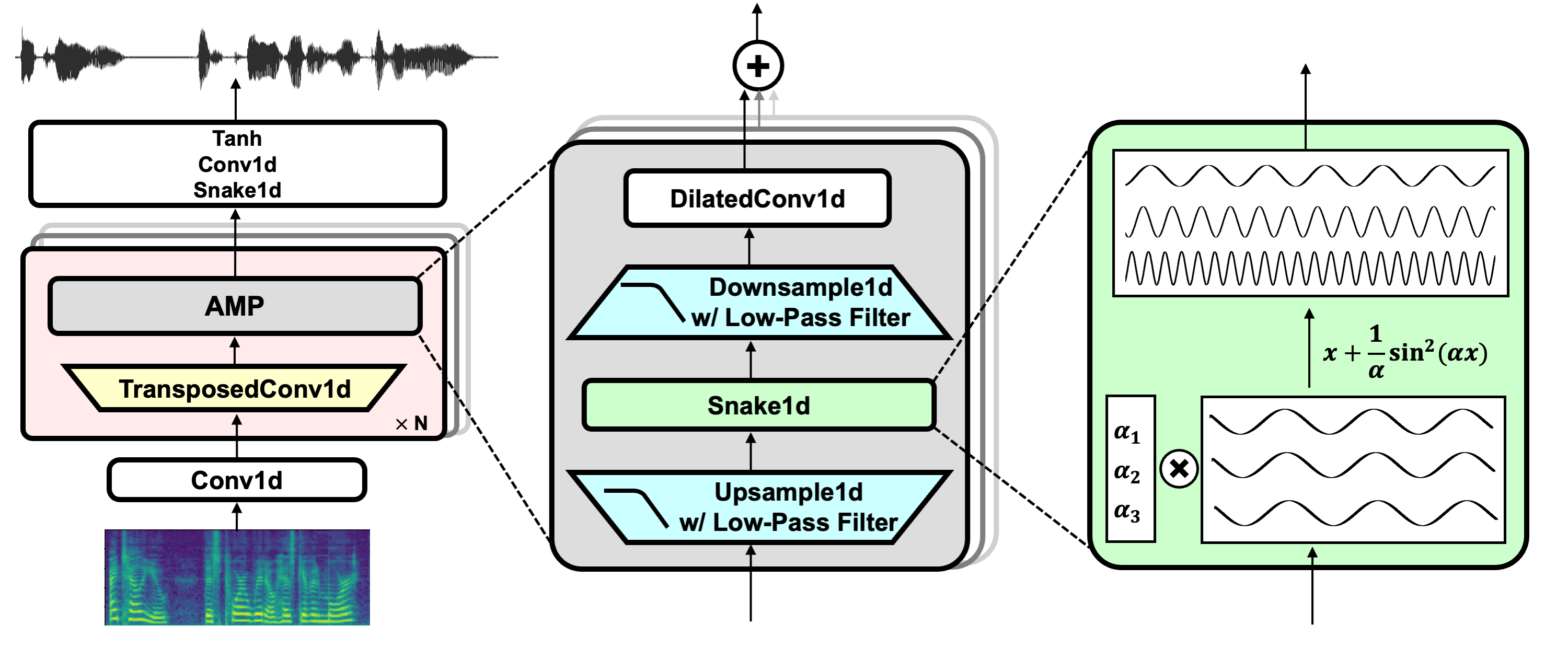
Ссылка на проект: https://github.com/nvidia/bigvgan
Скачать модель предварительного дорода BIGVGAN_BASE_24KHZ_100BANDBAND
python bigvgan/inference.py
--input_wavs_dir bigvgan_debug
--output_dir bigvgan_outPython bigvgan/train.py -config bigvgan_pretrain/config.json
Hifi-Gan (для генератора и многопериодного дискриминатора)
Змея (для периодической активации)
Псевдоним, не содержащий псевдонимов (для анти-алиатов)
Юлиус (для фильтра низкого уровня)
Univnet (для дискриминатора с несколькими разрешениями)


