Grad TTS Chinese
release grad-tts-cfm
학습을위한 TTS 알고리즘 프로젝트는 추론 속도가 느리지 만 확산은 큰 트렌드입니다.
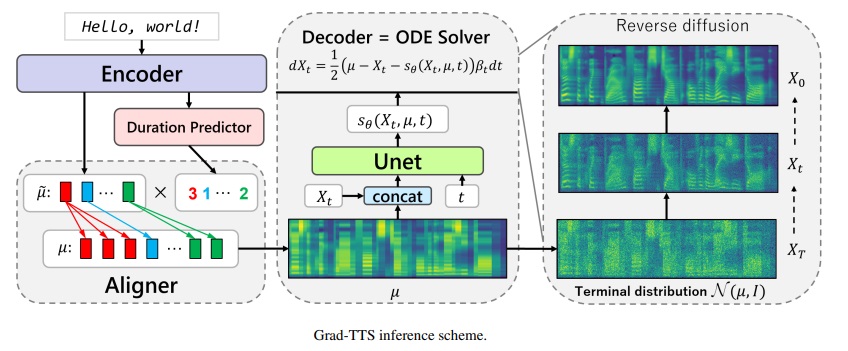
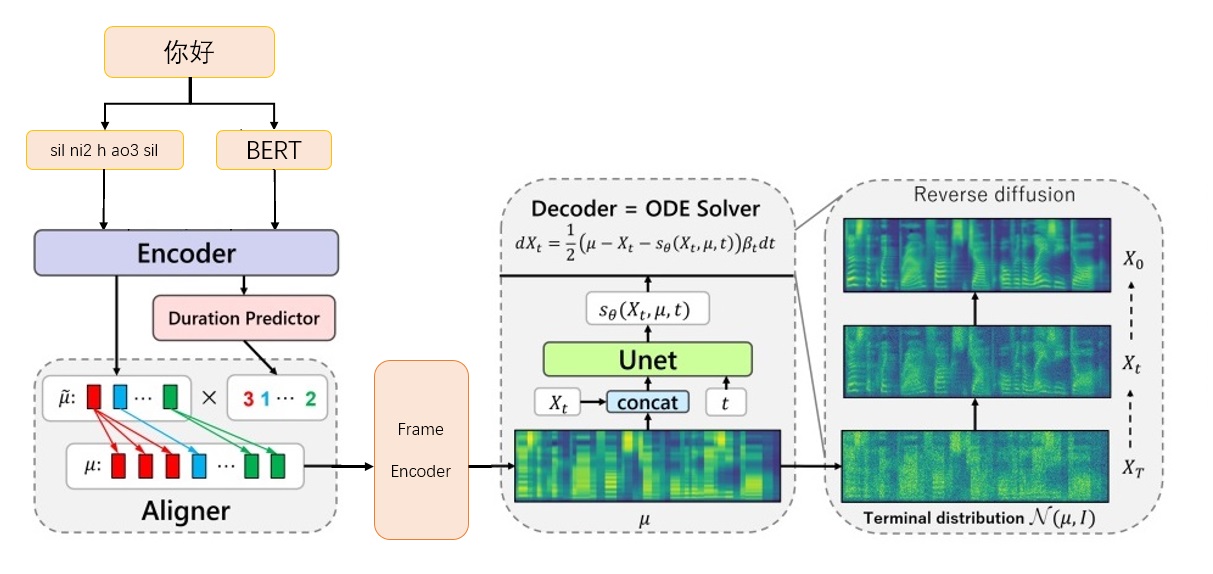 Grad-TTS-CFM 프레임 워크
Grad-TTS-CFM 프레임 워크
NVIDIA/BIGVGAN에서 VOCODER 모델 BIGVGAN_BASE_24KHZ_100BAND를 다운로드하십시오
G_05000000을 ./bigvgan_pretrain/g_0500000에 넣습니다
ExecuteDone/Chinese-FastSpeech2에서 Bert Prosody_Model을 다운로드하십시오
Best_model.pt를 grosody_model.pt로 바꾸고 ./bert/prosody_model.pt에 넣습니다
릴리스 페이지에서 TTS 모델 다운로드 grad_tts.pt 릴리스 페이지에서
grad_tts.pt를 현재 디렉토리 또는 어디서나 넣습니다
설치 환경 종속성
PIP 설치 -R 요구 사항 .txt
cd ./grad/monotonic_align
Python setup.py build_ext- 인시
CD -
추론 테스트
Python interference.py -파일 test.txt -checkpoint grad_tts.pt -timesteps 10 -온화 1.015
./inference_out 에서 오디오를 생성합니다 ./inference_out
timesteps 클수록 효과가 더 좋을수록 추론 시간이 길어집니다. 0으로 설정하면 확산이 건너 뜁니다. 프레임 엔코더에 의해 생성 된 MEL 스펙트럼이 출력됩니다.
temperature 확산 추론에 의해 추가 된 소음의 양을 결정하고 최상의 값을 디버깅해야합니다.
Biaobei 데이터의 공식 링크를 다운로드하십시오 : https://www.data-baker.com/data/index/tntts/
./data/waves에 Waves 를 넣으십시오
./data/000001-010000.txt에 000001-010000.txt 넣으십시오
BigVGAN 24K 모델이 사용됨에 따라 24kHz로 리샘플링하십시오
Python 도구/preprocess_a.py -w ./data/wave/-o ./data/wavs -s
24000
MEL 스펙트럼을 추출하고 보코더를 교체하십시오. 코드에 작성된 MEL 매개 변수에주의를 기울여야합니다.
Python 도구/preprocess_m.py -wav data/wavs/-out data/mels/
Bert Pronunciation 벡터를 추출하고 훈련 색인 파일 train.txt 및 valid.txt 동시에 생성하십시오.
Python 도구/preprocess_b.py
출력에는 data/berts/ 및 data/files 포함됩니다
참고 : 인쇄 정보는儿化音제거하는 것입니다 (프로젝트는 알고리즘 데모이며 생산을 수행하지 않습니다).
추가 지침
오리지널 레이블
000001 卡尔普#2陪外孙#1玩滑梯#4。
ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
000002 假语村言#2别再#1拥抱我#4。
jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3 Bert가 한자卡尔普陪外孙玩滑梯。 (구두점 포함), tts는 최종 모음 sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil 필요로합니다.
000001 卡尔普陪外孙玩滑梯。
ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
000002 假语村言别再拥抱我。
jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3
sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp sil훈련 레이블
./data/wavs/000001.wav|./data/mels/000001.pt|./data/berts/000001.npy|sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
./data/wavs/000002.wav|./data/mels/000002.pt|./data/berts/000002.npy|sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp sil
이 문장은 잘못 될 것입니다
002365 这图#2难不成#2是#1P过的#4?
zhe4 tu2 nan2 bu4 cheng2 shi4 P IY1 guo4 de5
디버그 데이터 세트
Python 도구/preprocess_d.py
훈련을 시작하십시오
Python Train.py
회복 훈련
Python Train.py -p logs/new_exp/grad_tts _ ***. Pt
Python interference.py -file test.txt-checkpoint ./logs/new_exp/grad_tts____ept -timesteps 20 --temperature 1.15
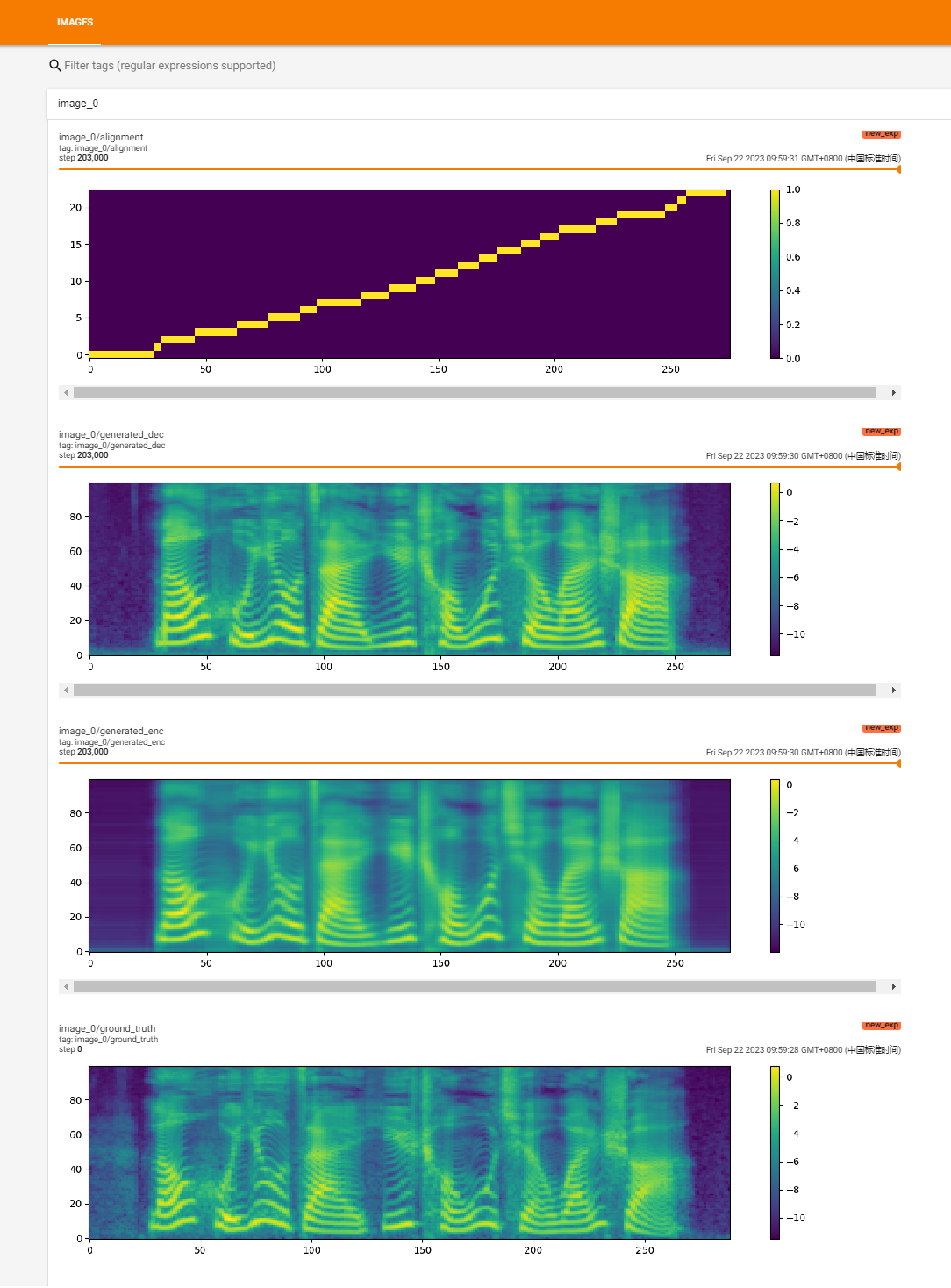
https://github.com/huawei-noah/speech-backbones/blob/main/grad-tts
https://github.com/shivammehta25/matcha-tts
https://github.com/thuhcsi/lightgrad
https://github.com/executedone/chinese-fastspeech2
https://github.com/playvoice/vits_chinese
https://github.com/nvidia/bigvgan
확산 확률 모델링을 기반으로 한 GRAD-TTS 모델의 공식 구현. 모든 세부 사항은이 링크를 통해 ICML 2021에 수락 된 논문을 확인하십시오.
저자 : Vadim Popov*, Ivan Vovk*, Vladimir Gogoryan, Tasnima Sadekova, Mikhail Kudinov.
*동등한 기여.
Voiced Abstract가있는 데모 페이지 : 링크.
최근에, 비난 확산 확률 모델과 일반화 된 점수 매칭은 복잡한 데이터 분포 모델링에서 높은 잠재력을 보여 주었고, 확률 적 계산은 이러한 기술에 대한 통일 된 관점을 제공하여 유연한 추론 체계를 허용했다. 이 논문에서 우리는 인코더에 의해 예측 된 소음을 점차적으로 변환하고 단조로운 정렬 검색을 통해 텍스트 입력과 정렬함으로써 Mel-spectrogram을 생성하는 점수 기반 디코더가있는 새로운 텍스트 음성 변환 모델 인 Grad-tts를 소개합니다. 확률 적 미분 방정식의 프레임 워크는 다양한 매개 변수로 노이즈에서 데이터를 재구성하는 경우에 기존 차이 확률 모델을 일반화하고 음질과 추론 속도 사이의 트레이드 오프를 명시 적으로 제어 하여이 재구성을 유연하게 만들 수 있도록 도와줍니다. 주관적인 인간 평가에 따르면 GRAD-TTS는 평균 의견 점수 측면에서 최첨단 텍스트 음성 연사 접근 방식과 경쟁력이 있음을 보여줍니다.
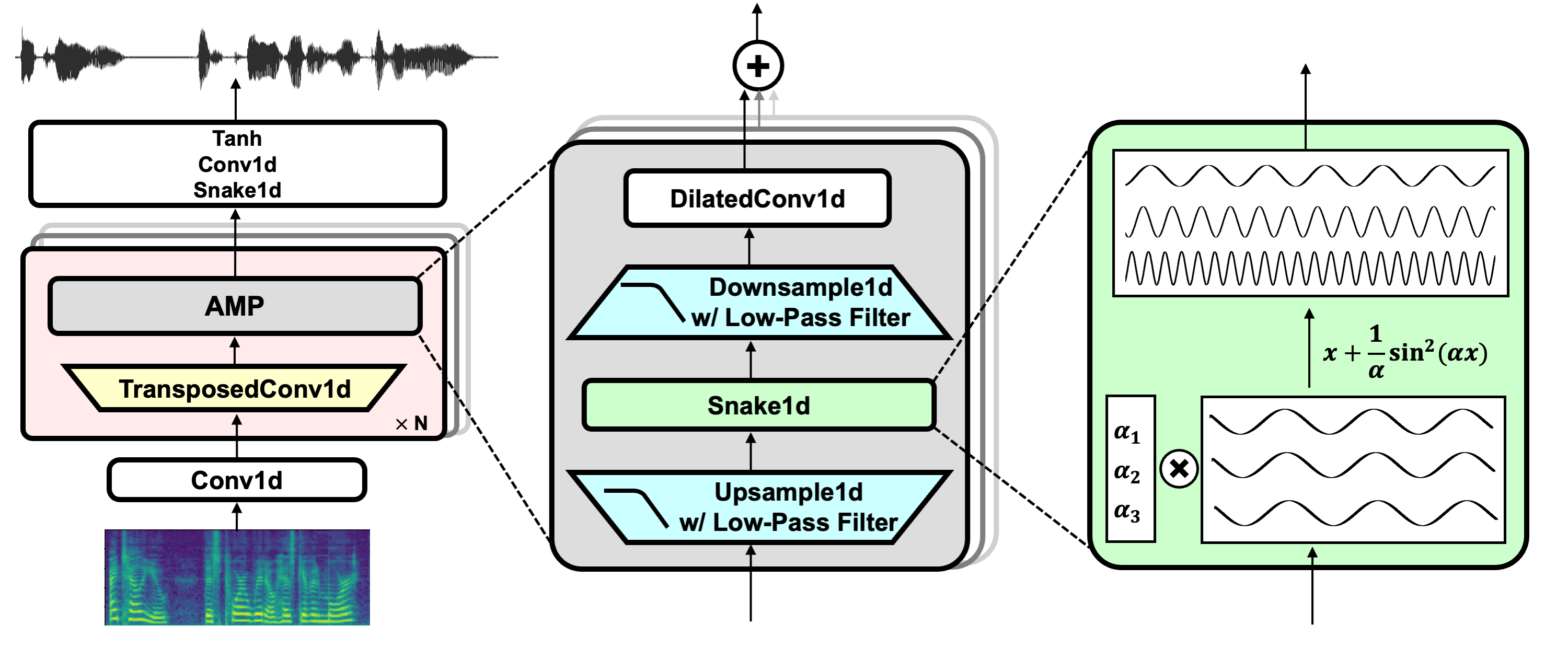
프로젝트 링크 : https://github.com/nvidia/bigvgan
프리 트레인 모델 bigvgan_base_24khz_100and를 다운로드하십시오
python bigvgan/inference.py
--input_wavs_dir bigvgan_debug
--output_dir bigvgan_outPython bigvgan/train.py ---config bigvgan_pretrain/config.json
Hifi-gan (발전기 및 다중 기간 판별 자)
뱀 (주기적 활성화)
별칭이없는 토치 (반 알리 아스)
줄리어스 (저역 통과 필터)
Univnet (다중 해상도 판별 자 용)


