Grad TTS Chinese
release grad-tts-cfm
Das TTS -Algorithmusprojekt für das Lernen hat eine langsame Argumentationsgeschwindigkeit, aber die Diffusion ist ein großer Trend
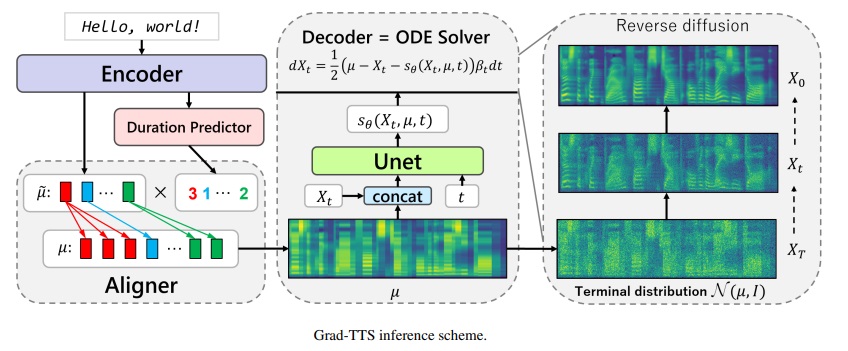
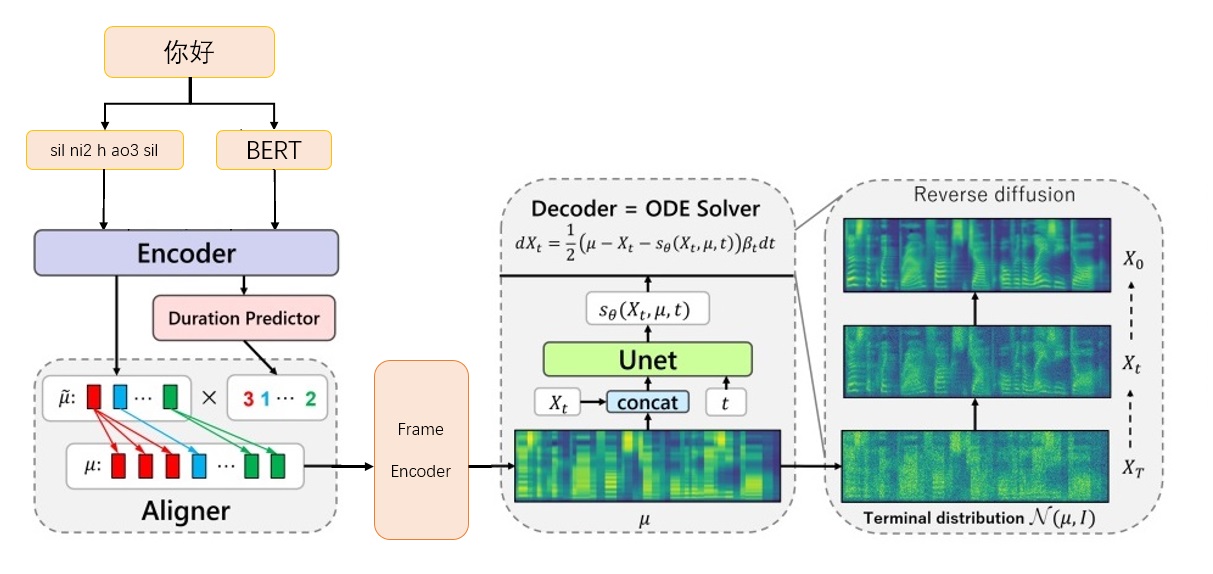 Grad-TTS-CFM-Framework
Grad-TTS-CFM-Framework
Laden Sie das Vocoder -Modell Bigvgan_Base_24KHz_100Band von nvidia/bigvgan herunter
Geben Sie G_05000000 in ./Bigvgan_Pretrain/g_0500000 ein
Download Bert Prosody_Model von execututeTone/chinesisch-fastspeech22
Benennen
Laden Sie das TTS -Modell von der Release -Seite grad_ts.pt von der Release -Seite herunter
Stellen Sie Grad_ts.pt in das aktuelle Verzeichnis oder überall ein
Installationsumgebung Abhängigkeit
PIP Installation -r Anforderungen.txt
CD ./grad/monotonic_align
python setup.py Build_ext - -anplace
CD -
Inferenztest
Python Inference.py - -File test.txt -Checkpoint Grad_ts.pt - -Timesteps 10 -Temperature 1.015
Generieren Sie Audio im ./inference_out
Je größer timesteps , desto besser ist der Effekt, desto länger die Argumentationszeit; Wenn auf 0 eingestellt wird, wird die Diffusion übersprungen und das von FrameCodier erzeugte MEL -Spektrum wird ausgegeben.
temperature bestimmt die Menge an Rauschmenge, die durch Diffusionsbekämpfung hinzugefügt wird, und muss den besten Wert debuggen.
Laden Sie den offiziellen Link von Biaobei-Daten herunter: https://www.data-baker.com/data/index/tntts/
Waves in ./data/waves einlegen
000001-010000.txt in ./data/000001-010000.txt
Resampling auf 24 kHz, da das Bigvgan 24K -Modell verwendet wird
Python Tools/Precess_a.py -W ./data/wave/ -o ./data/wavs -s
24000
Extrahieren Sie das MEL -Spektrum und ersetzen Sie den Vocoder. Sie müssen auf die im Code geschriebenen Mel -Parameter achten.
Python Tools/Precess_M.Py --WAV -Daten/WAVs/ -Out -Daten/MELS/
Extrahieren Sie den Bert -Aussprachungsvektor und generieren Sie gleichzeitig den Training Index Dateien train.txt und valid.txt
Python Tools/Precess_B.Py
Die Ausgabe enthält data/berts/ und data/files
Hinweis: Druckinformationen sollen儿化音entfernen (das Projekt ist eine Algorithmusdemonstration und führt keine Produktion)
Zusätzliche Anweisungen
Originaletikett
000001 卡尔普#2陪外孙#1玩滑梯#4。
ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
000002 假语村言#2别再#1拥抱我#4。
jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3 Es muss markiert werden, da Bert die chinesischen Charaktere卡尔普陪外孙玩滑梯。 (einschließlich Interpunktion) benötigt TTS den endgültigen sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
000001 卡尔普陪外孙玩滑梯。
ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
000002 假语村言别再拥抱我。
jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3
sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp silTrainingsetikett
./data/wavs/000001.wav|./data/mels/000001.pt|./data/berts/000001.npy|sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
./data/wavs/000002.wav|./data/mels/000002.pt|./data/berts/000002.npy|sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp sil
Dieser Satz macht einen Fehler
002365 这图#2难不成#2是#1P过的#4?
zhe4 tu2 nan2 bu4 cheng2 shi4 P IY1 guo4 de5
Datensatz debuggen
Python Tools/Precess_D.Py
Beginnen Sie mit dem Training
Python Train.py
Wiederherstellungstraining
Python Train.py -p logs/new_exp/grad_tts _ ***. pt
python inference.py - -file test.txt -Checkpoint ./logs/new_exp/grad_tts_***.pt ---timesteps 20 --temperature 1.15
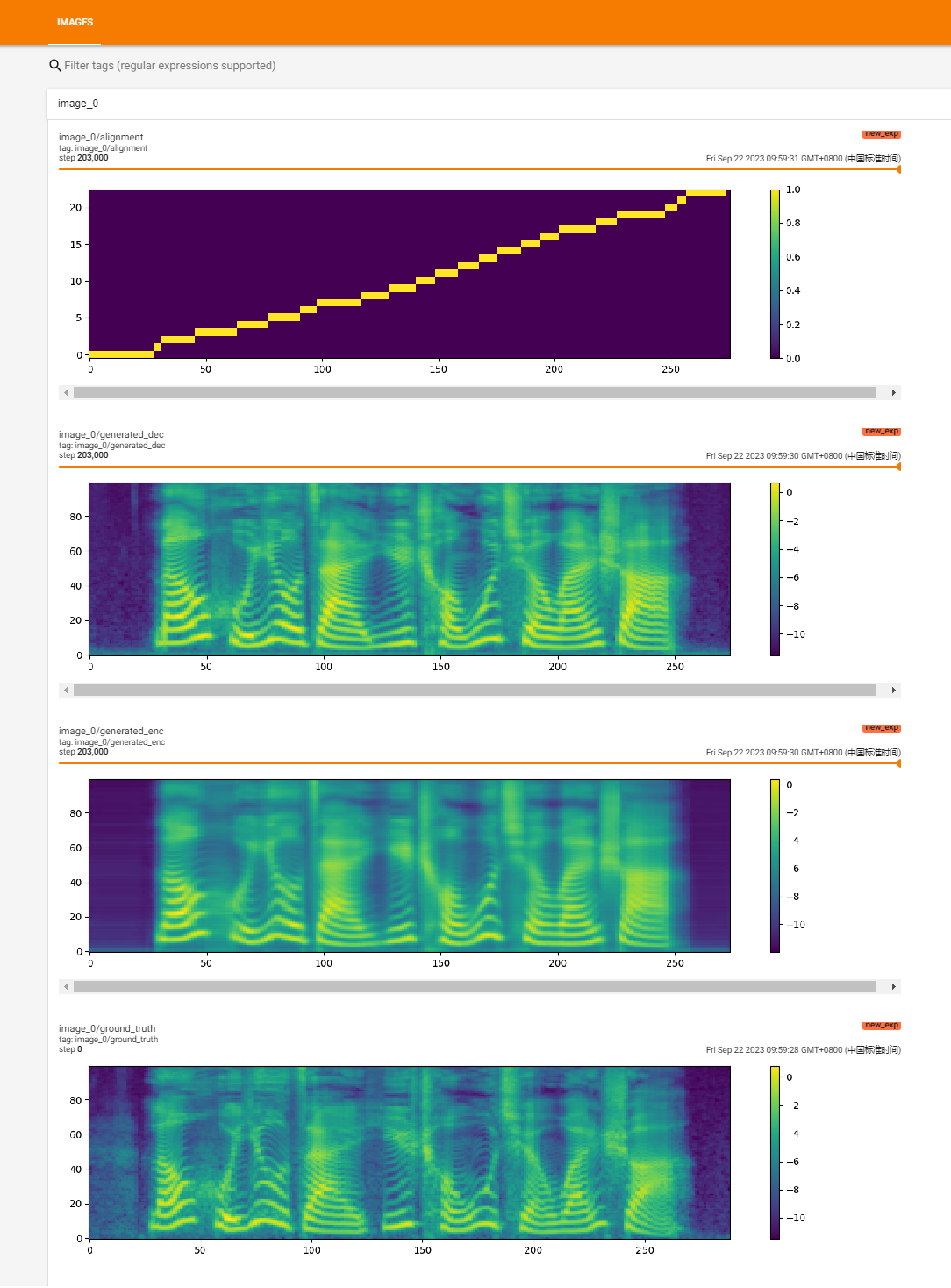
https://github.com/huawei-noah/speech-backbones/blob/main/grad-tts
https://github.com/shivammehta25/matcha-tts
https://github.com/thuhcsi/lightgradgrad
https://github.com/executedone/chinese-fastspeech2
https://github.com/playvoice/vits_chinese
https://github.com/nvidia/bigvgan
Offizielle Implementierung des Grad-TTS-Modells basierend auf der diffusions-probabilistischen Modellierung. Für alle Details finden Sie unsere auf ICML 2021 akzeptierte Arbeit über diesen Link.
Autoren : Vadim Popov*, Ivan Vovk*, Vladimir Gogoryan, Tasnima Sadekova, Mikhail Kudinov.
*Gleicher Beitrag.
Demo -Seite mit stimmhaftem Zusammenfassung: Link.
In jüngster Zeit haben die Denoising -Diffusion -probabilistische Modelle und eine verallgemeinerte Score -Matching ein hohes Potenzial bei der Modellierung komplexer Datenverteilungen gezeigt, während die stochastische Berechnung einen einheitlichen Standpunkt dieser Techniken geliefert hat, die flexible Inferenzschemata ermöglichen. In diesem Artikel stellen wir Grad-TTs vor, ein neuartiges Text-zu-Sprach-Modell mit Score-basierter Decoder, das Melspektrogramme erzeugt, indem er durch die monotonische Ausrichtungssuche allmählich das von Encoder vorhergesagte und mit dem Texteingang ausgerichtete Rauschen transformiert wird. Der Rahmen stochastischer Differentialgleichungen hilft uns, herkömmliche Differenzwahrscheinlichkeitsmodelle auf den Fall von Rekonstruktion von Daten aus Rauschen mit unterschiedlichen Parametern zu verallgemeinern, und ermöglicht diese Rekonstruktion flexibel, indem der Kompromiss zwischen Klangqualität und Inferenzgeschwindigkeit explizit gesteuert wird. Die subjektive menschliche Bewertung zeigt, dass Grad-TTS mit modernsten Text-zu-Sprache-Ansätzen im Hinblick auf die mittlere Meinungsbewertung konkurrenzfähig ist.
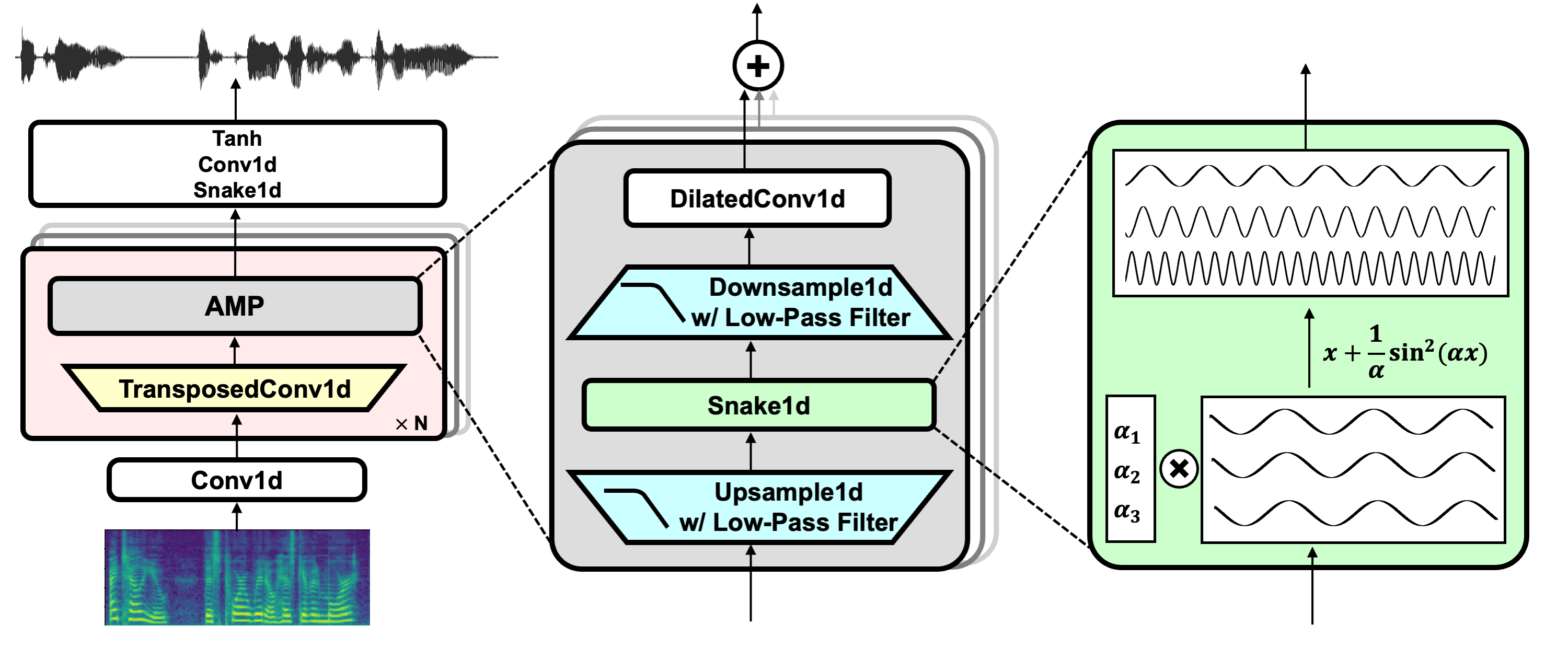
Projektlink: https://github.com/nvidia/bigvgan
Download Pretrain Model Bigvgan_Base_24KHz_100Band
python bigvgan/inference.py
--input_wavs_dir bigvgan_debug
--output_dir bigvgan_outPython Bigvgan/Train.py --Config Bigvgan_PRetrain/config.json
Hifi -gan (für Generator und Diskriminator mit mehreren Perioden)
Schlange (zur periodischen Aktivierung)
Alias-freie Torch (für Anti-Aliasing)
Julius (für Tiefpassfilter)
UNIVNET (für Diskriminator mit mehreren Auflösung)


