Grad TTS Chinese
release grad-tts-cfm
O projeto do algoritmo TTS para a aprendizagem tem uma velocidade de raciocínio, mas a difusão é uma grande tendência
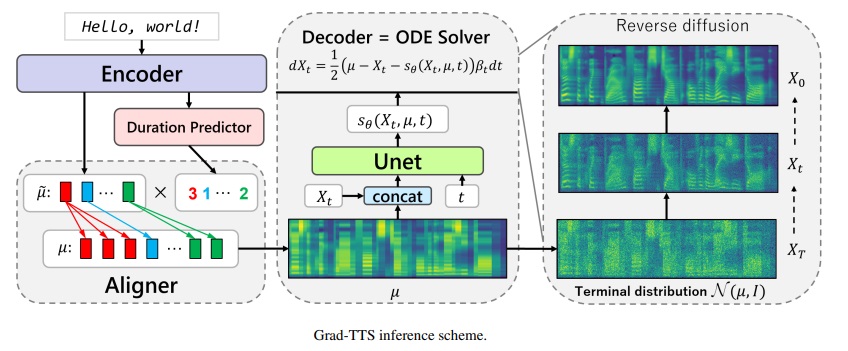
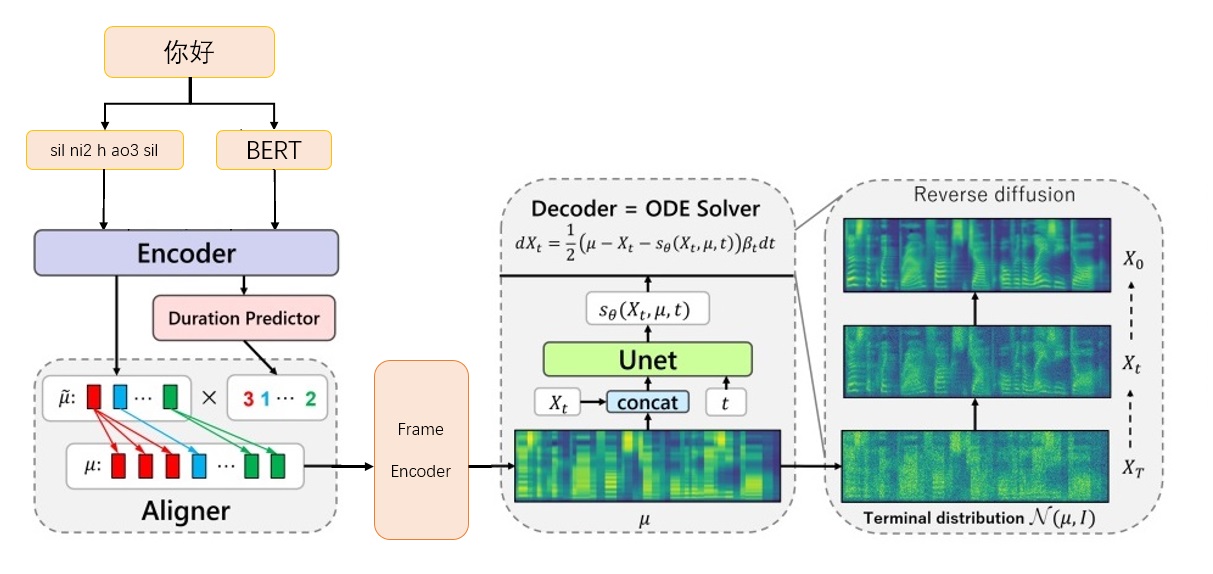 Framework grad-tts-CFM
Framework grad-tts-CFM
Baixe o modelo de vocoder bigvgan_base_24khz_100band de nvidia/bigvgan
Coloque G_05000000 em ./bigvgan_pretrain/g_0500000
Baixe Bert Prosody_model de ExecuteDone/Chinês-FastSpeech2
Renomeie Best_model.pt para prosody_model.pt e coloque -o em ./bert/prosody_model.pt
Baixe o modelo TTS na página de lançamento grad_tts.pt na página de lançamento
Coloque grad_tts.pt no diretório atual, ou em qualquer lugar
Dependência do ambiente de instalação
pip install -r requisitos.txt
cd ./grad/monotonic_align
python setup.py build_ext -no local
cd -
Teste de inferência
python inference.py --File test.txt --checkpoint grad_tts.pt - -timeSteps 10 -Temperatura 1.015
Gerar áudio na ./inference_out
Quanto maior timesteps , melhor o efeito, maior o tempo de raciocínio; Quando definido como 0, a difusão será ignorada e o espectro MEL gerado pelo Framencoder será emitido.
temperature determina a quantidade de ruído adicionada pelo raciocínio de difusão e precisa depurar o melhor valor.
Baixe o link oficial dos dados biaobei: https://www.data-baker.com/data/index/tntts/
Coloque Waves em ./data/waves
Coloque 000001-010000.txt em ./data/000001-010000.txt
Reamostragem para 24kHz, como o modelo bigvgan 24k é usado
Python Tools/preprocess_a.py -w ./data/wave/-o ./data/wavs -s
24000
Extraia o espectro MEL e substitua o vocoder, você precisa prestar atenção aos parâmetros MEL escritos no código.
Python Tools/preprocess_m.py -Dados -wav/wavs/ -out data/mels/
Extraia o vetor de pronúncia Bert e gere os arquivos do índice de treinamento train.txt e valid.txt ao mesmo tempo
Ferramentas Python/preprocess_b.py
A saída inclui data/berts/ e data/files
Nota: a impressão de informações é remover儿化音(o projeto é uma demonstração de algoritmo e não faz produção)
Instruções adicionais
Etiqueta original
000001 卡尔普#2陪外孙#1玩滑梯#4。
ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
000002 假语村言#2别再#1拥抱我#4。
jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3 Ele precisa ser marcado, pois Bert exige que os personagens chineses卡尔普陪外孙玩滑梯。 (incluindo pontuação), o TTS requer a vogal final sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
000001 卡尔普陪外孙玩滑梯。
ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
000002 假语村言别再拥抱我。
jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3
sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp silEtiqueta de treinamento
./data/wavs/000001.wav|./data/mels/000001.pt|./data/berts/000001.npy|sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
./data/wavs/000002.wav|./data/mels/000002.pt|./data/berts/000002.npy|sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp sil
Esta frase vai dar errado
002365 这图#2难不成#2是#1P过的#4?
zhe4 tu2 nan2 bu4 cheng2 shi4 P IY1 guo4 de5
Conjunto de dados de depuração
Ferramentas Python/preprocess_d.py
Comece a treinar
Python Train.py
Treinamento de recuperação
Python Train.py -p logs/new_exp/grad_tts _ ***.
python inference.py --file test.txt --checkpoint ./logs/new_exp/grad_tts_***.pt - -timeSteps 20 -Temperature 1.15
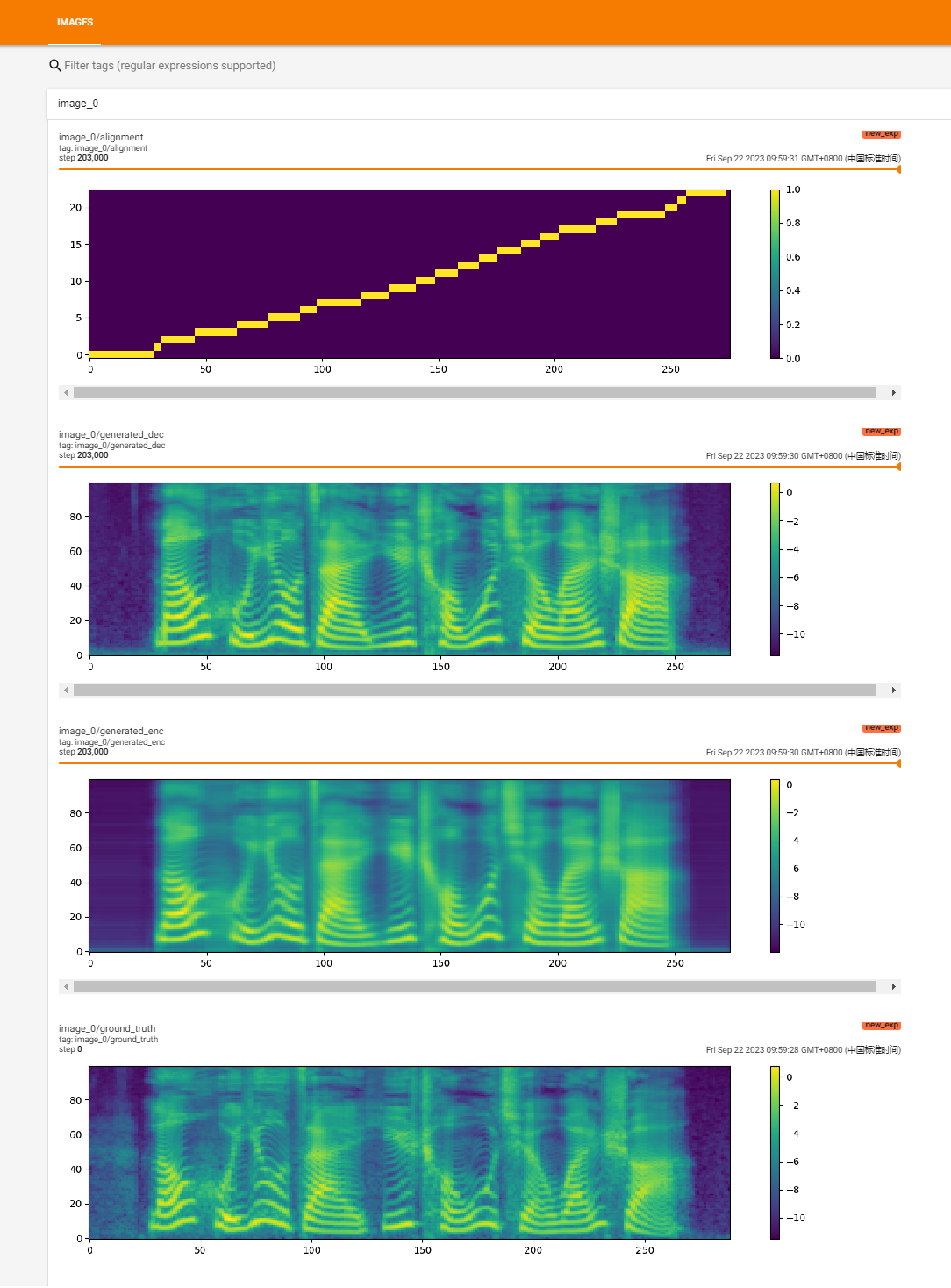
https://github.com/huawei-noah/speech-backbones/blob/main/grad-tts
https://github.com/shivammehta25/matcha-tts
https://github.com/thuhcsi/lightgrad
https://github.com/exectedone/chinese-fastspeech2
https://github.com/playvoice/vits_chinese
https://github.com/nvidia/bigvgan
Implementação oficial do modelo GRAD-TTS baseado na modelagem probabilística da difusão. Para todos os detalhes, consulte nosso artigo aceito no ICML 2021 através deste link.
Autores : Vadim Popov*, Ivan Vovk*, Vladimir Gogoryan, Tasnima Sadekova, Mikhail Kudinov.
*Igual contribuição.
Página de demonstração com abstrato de voz: link.
Recentemente, modelos probabilísticos de difusão de denoising e correspondência generalizada de pontuação mostraram alto potencial na modelagem de distribuições complexas de dados, enquanto o cálculo estocástico forneceu um ponto de vista unificado sobre essas técnicas, permitindo esquemas de inferência flexíveis. Neste artigo, introduzimos graduados, um novo modelo de texto em fala com decodificador baseado em pontuação produzindo espectrogramas de MEL, transformando gradualmente o ruído previsto pelo codificador e alinhado com a entrada de texto por meio de pesquisa de alinhamento monotônico. A estrutura de equações diferenciais estocásticas nos ajuda a generalizar modelos de probabilidade de diferença convencionais para o caso de reconstruir dados do ruído com diferentes parâmetros e permite tornar essa reconstrução flexível, controlando explicitamente o trade-off entre a qualidade do som e a velocidade de inferência. A avaliação humana subjetiva mostra que os graduados são competitivos com as abordagens de texto em fala em termos de pontuação média de opinião.
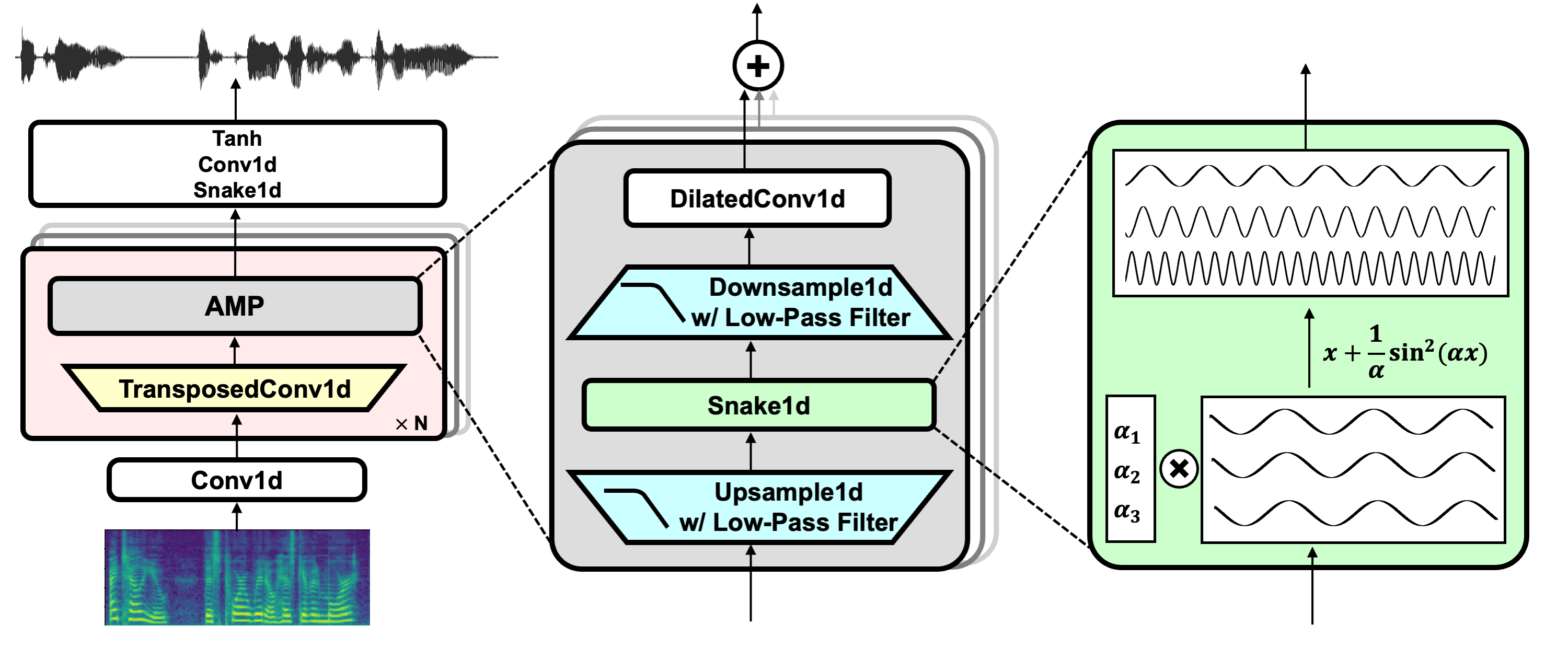
Link do projeto: https://github.com/nvidia/bigvgan
Baixe o modelo pretrain bigvgan_base_24khz_100band
python bigvgan/inference.py
--input_wavs_dir bigvgan_debug
--output_dir bigvgan_outpython bigvgan/trens.py -Config bigvgan_pretrain/config.json
HIFI-GAN (para gerador e discriminador multi-perioso)
Cobra (para ativação periódica)
Alias-Free-Torch (para anti-aliasing)
Julius (para filtro passa-baixo)
Univnet (para discriminador de várias resolução)


