Grad TTS Chinese
release grad-tts-cfm
Le projet d'algorithme TTS pour l'apprentissage a lent à la vitesse du raisonnement, mais la diffusion est une grande tendance
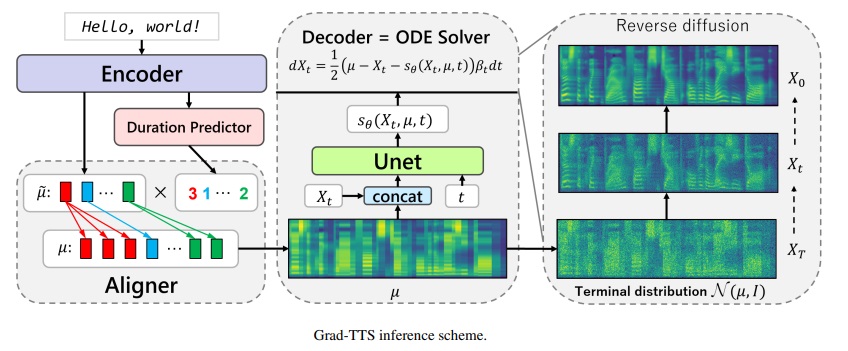
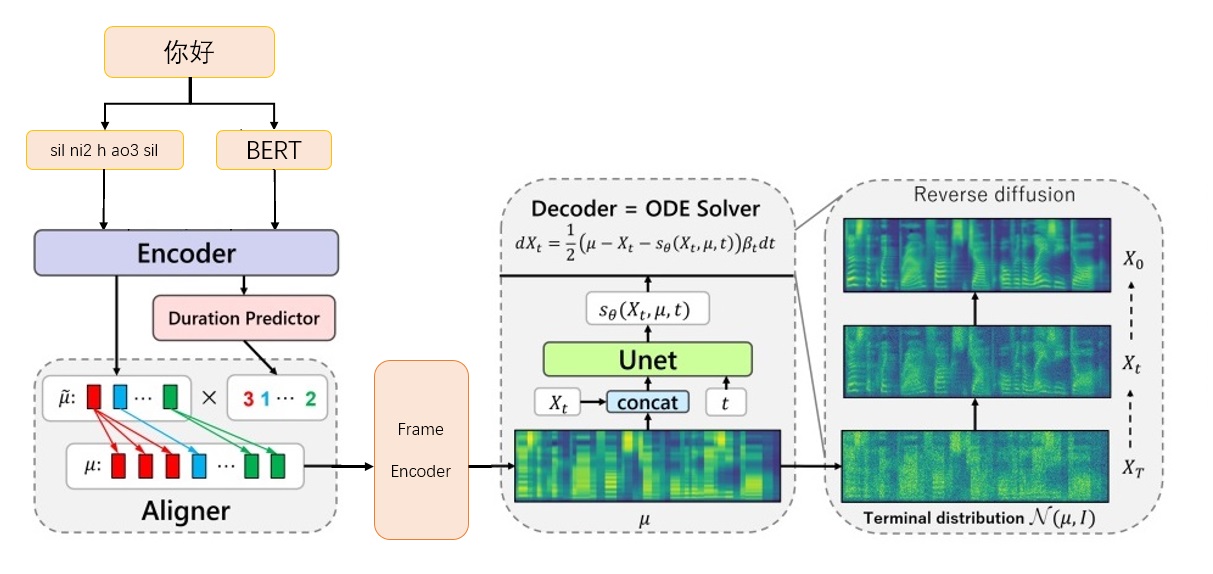 Framework Grad-TTS-CFM
Framework Grad-TTS-CFM
Téléchargez le modèle Vocoder bigvgan_base_24khz_100band de nvidia / bigvgan
Mettre G_05000000 dans ./Bigvgan_pretrain/g_0500000
Téléchargez Bert Prosody_Model à partir de ExecutedOne / Chinese-FastSpeech2
Renommer best_model.pt à prosody_model.pt et mettez-le dans ./bert/prosody_model.pt
Téléchargez le modèle TTS depuis la page de version grad_tts.pt à partir de la page de version
Mettez grad_tts.pt dans le répertoire actuel, ou n'importe où
Dépendance de l'environnement d'installation
pip install -r exigences.txt
CD ./grad/monotonic_align
python setup.py build_ext --inplace
CD -
Test d'inférence
python inference.py - file test.txt --checkpoint grad_tts.pt --timesthets 10 - température 1.015
Générer de l'audio dans ./inference_out
Plus timesteps grand, plus l'effet est grand, plus le temps de raisonnement est long; Lorsqu'il est réglé sur 0, la diffusion sera ignorée et le spectre MEL généré par Frameencoder sera sorti.
temperature détermine la quantité de bruit ajoutée par le raisonnement de diffusion et doit déboguer la meilleure valeur.
Téléchargez le lien officiel des données Biaobei: https://www.data-baker.com/data/index/tntts/
Mettez Waves dans ./data/waves
Put 000001-010000.txt dans ./data/000001-010000.txt
Rééchantillonnage à 24 kHz, comme le modèle Bigvgan 24K est utilisé
Python Tools / Preprocess_a.py -w ./data/wave/ -o ./data/wavs -s
24000
Extraire le spectre MEL et remplacer le vocodeur, vous devez faire attention aux paramètres MEL écrits dans le code.
Python Tools / Preprocess_M.Py - Data WAV / wavs / --out Data / Mels /
Extraire le vecteur de prononciation Bert et générer les fichiers d'index de formation train.txt et valid.txt en même temps
outils python / prerocess_b.py
La sortie comprend data/berts/ et data/files
Remarque: Les informations d'impression consistent à supprimer儿化音(le projet est une démonstration d'algorithme et ne fait pas de production)
Instructions supplémentaires
Étiquette d'origine
000001 卡尔普#2陪外孙#1玩滑梯#4。
ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
000002 假语村言#2别再#1拥抱我#4。
jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3 Il doit être marqué car Bert nécessite que les caractères chinois卡尔普陪外孙玩滑梯。 (y compris la ponctuation), TTS nécessite la voyelle finale sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
000001 卡尔普陪外孙玩滑梯。
ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
000002 假语村言别再拥抱我。
jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3
sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp silÉtiquette de formation
./data/wavs/000001.wav|./data/mels/000001.pt|./data/berts/000001.npy|sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil
./data/wavs/000002.wav|./data/mels/000002.pt|./data/berts/000002.npy|sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp sil
Cette phrase fera une erreur
002365 这图#2难不成#2是#1P过的#4?
zhe4 tu2 nan2 bu4 cheng2 shi4 P IY1 guo4 de5
Ensemble de données de débogage
Python Tools / Preprocess_d.py
Commencer à s'entraîner
Python Train.py
Formation à la récupération
Python Train.py -p Logs / new_exp / grad_tts _ ***. PT
python inference.py ---file test.txt --checkpoint ./logs/new_exp/grad_tts_***.pt - TimeStests 20 - Température 1.15
https://github.com/huawei-noah/speech-backbones/blob/main/grad-tts
https://github.com/shivammehta25/matcha-tts
https://github.com/thuhcsi/lightgrad
https://github.com/executedone/chinese-fastsspeech2
https://github.com/playvoice/vits_chinese
https://github.com/nvidia/bigvgan
Mise en œuvre officielle du modèle GRAT-TTS basé sur la modélisation probabiliste de diffusion. Pour tous les détails, consultez notre article accepté sur ICML 2021 via ce lien.
Auteurs : Vadim Popov *, Ivan Vovk *, Vladimir Gogoryan, Tasnima Sadekova, Mikhail Kudinov.
* Contribution égale.
Page de démonstration avec Résumé exprimé: lien.
Récemment, les modèles probabilistes de diffusion de débrassement et l'appariement des scores généralisés ont montré un potentiel élevé dans la modélisation des distributions de données complexes tandis que le calcul stochastique a fourni un point de vue unifié sur ces techniques permettant des schémas d'inférence flexibles. Dans cet article, nous introduisons Grad-TTS, un nouveau modèle de texte à dispection avec un décodeur basé sur des scores produisant des spectrogrammes de MEL en transformant progressivement le bruit prédit par l'encodeur et aligné avec l'entrée de texte au moyen de la recherche d'alignement monotonique. Le cadre des équations différentielles stochastiques nous aide à généraliser les modèles de probabilité de différence conventionnels au cas de reconstruction des données à partir du bruit avec différents paramètres et permet de rendre cette reconstruction flexible en contrôlant explicitement le compromis entre la qualité sonore et la vitesse d'inférence. L'évaluation humaine subjective montre que GRAD-TTS est compétitif avec les approches de texte à dispection de pointe en termes de score d'opinion moyen.
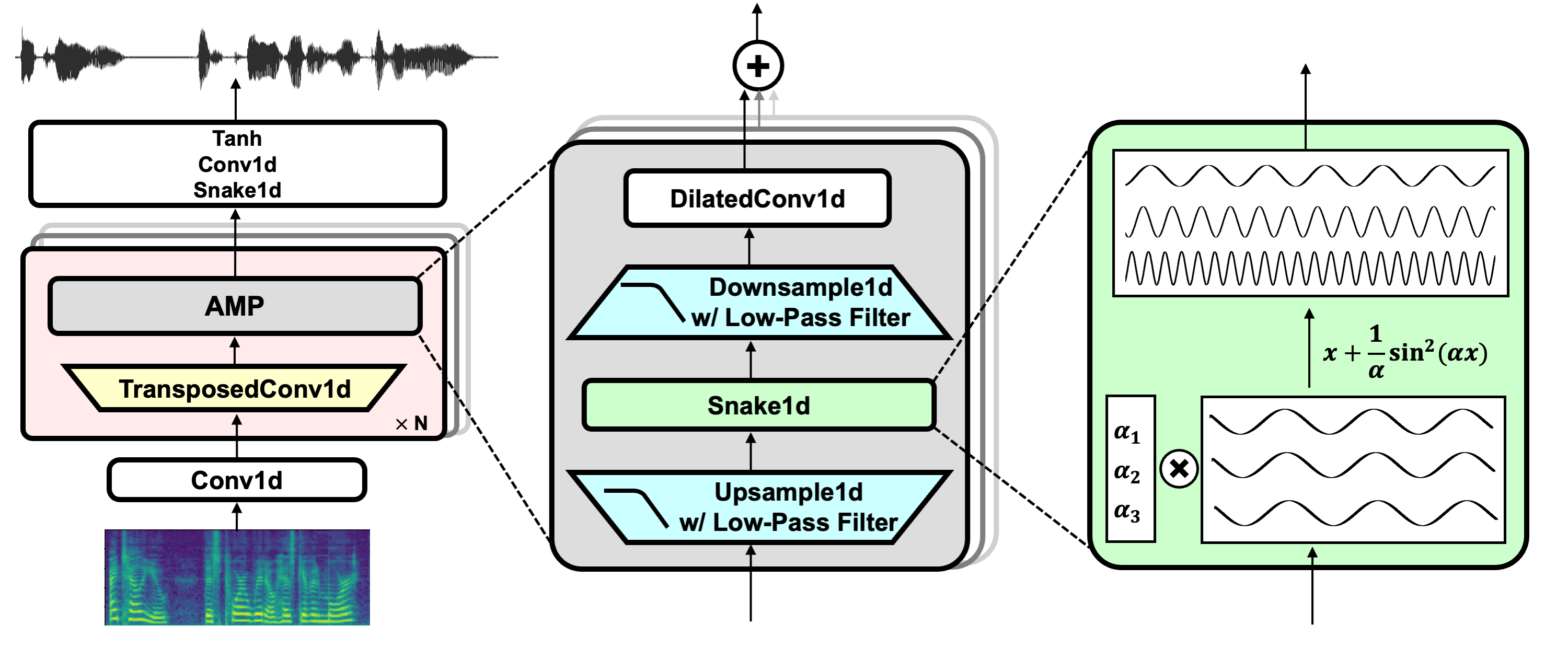
Lien du projet: https://github.com/nvidia/bigvgan
Télécharger le modèle Pretrain Bigvgan_Base_24KHz_100band
python bigvgan/inference.py
--input_wavs_dir bigvgan_debug
--output_dir bigvgan_outPython bigvgan / trains.py --Config bigvgan_pretrain / config.json
HIFI-GAN (pour le discriminateur générateur et multi-périodes)
Serpent (pour l'activation périodique)
Alias sans tournure (pour l'anti-aliasing)
Julius (pour un filtre passe-bas)
Univnet (pour le discriminateur multi-résolution)


