ChatLLM Web
v1.0.0

ภาษาอังกฤษ / 简体中文 / 日本語
แชทกับ LLM เช่น Vicuna ทั้งหมดในเบราว์เซอร์ของคุณด้วย WebGPU อย่างปลอดภัยเป็นการส่วนตัวและไม่มีเซิร์ฟเวอร์ ขับเคลื่อนโดย Web-llm
ลองเลย
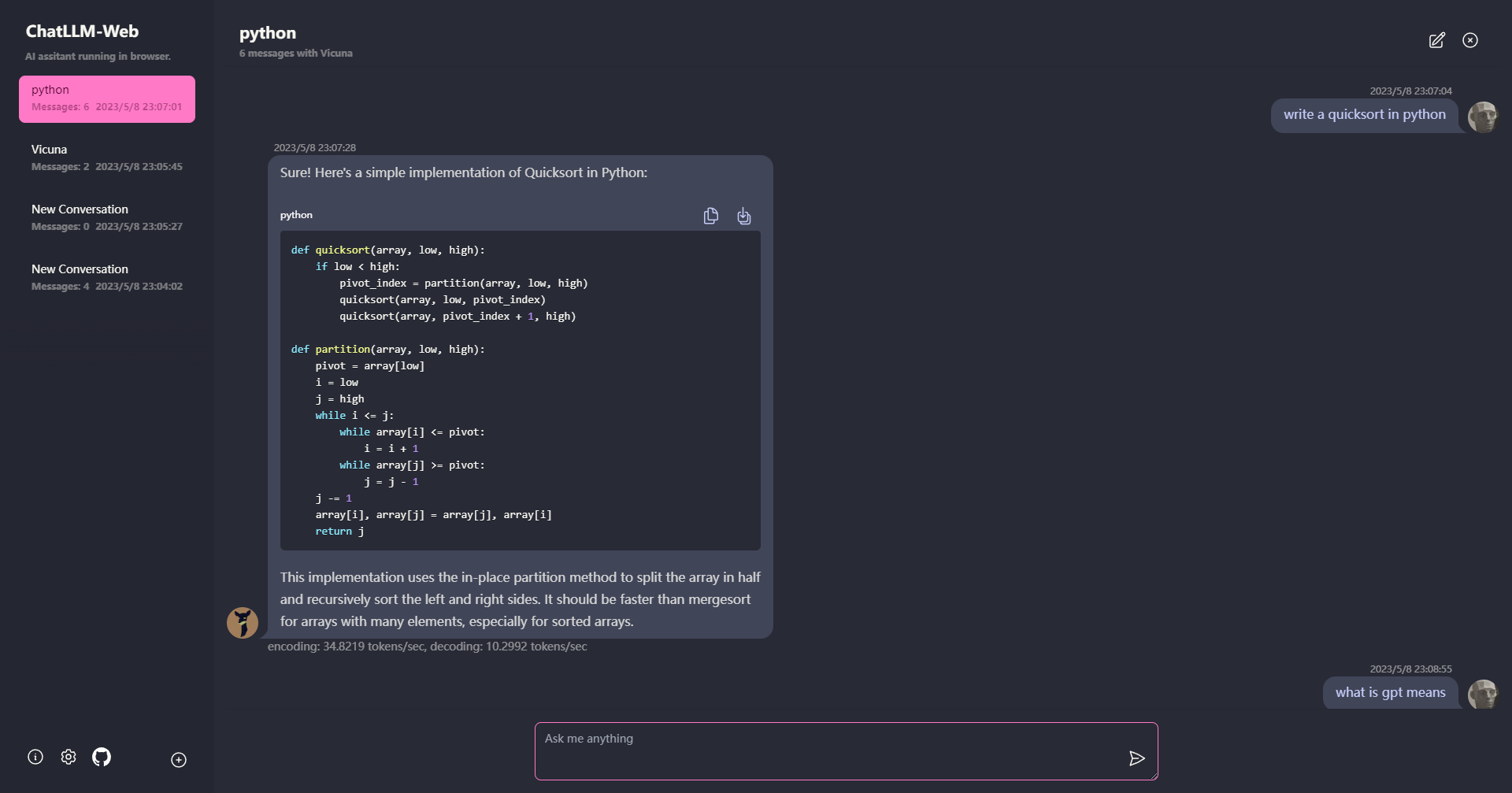
- ทุกอย่างทำงานภายในเบราว์เซอร์โดย ไม่มีการรองรับเซิร์ฟเวอร์ และ เร่งด้วย WebGPU
โมเดลทำงานในผู้ทำงานบนเว็บเพื่อให้มั่นใจว่าไม่ได้ปิดกั้นส่วนต่อประสานผู้ใช้และมอบประสบการณ์ที่ราบรื่น
ง่ายต่อการปรับใช้ฟรีด้วยคลิกเดียวบน vercel ภายในไม่ถึง 1 นาทีจากนั้นคุณจะได้รับเว็บ Chatllm ของคุณเอง
- รองรับการแคชแบบจำลองดังนั้นคุณจะต้องดาวน์โหลดรุ่นหนึ่งครั้งเท่านั้น
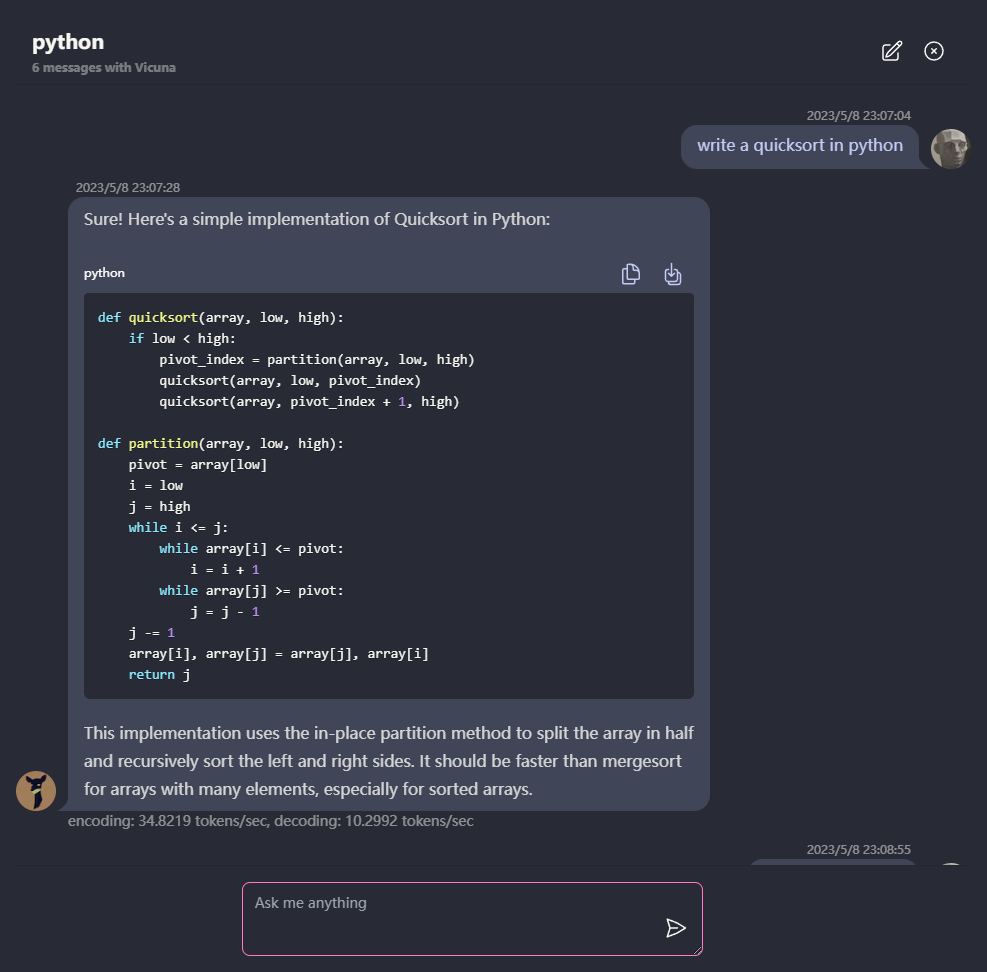
การแชทหลายครั้งพร้อมข้อมูลทั้งหมดที่เก็บไว้ในเบราว์เซอร์เพื่อความเป็นส่วนตัว
การสนับสนุนการตอบสนองของ Markdown และ Streaming: คณิตศาสตร์การเน้นรหัส ฯลฯ
- UI ตอบสนองและออกแบบมาอย่างดีรวมถึงโหมดมืด
สนับสนุน PWA ดาวน์โหลดและเรียกใช้ออฟไลน์โดยสิ้นเชิง
ในการใช้แอพนี้คุณต้องใช้เบราว์เซอร์ที่รองรับ WebGPU เช่น Chrome 113 หรือ Chrome Canary ไม่รองรับเวอร์ชัน Chrome ≤ 112
คุณจะต้องใช้ GPU ที่มีหน่วยความจำประมาณ 6.4GB หาก GPU ของคุณมีหน่วยความจำน้อยกว่าแอพจะยังคงทำงานอยู่ แต่เวลาตอบสนองจะช้าลง
- ครั้งแรกที่คุณใช้แอพคุณจะต้องดาวน์โหลดรุ่น สำหรับรุ่น Vicuna-7b ที่เราใช้อยู่ในปัจจุบันขนาดการดาวน์โหลดประมาณ 4GB หลังจากดาวน์โหลดครั้งแรกรุ่นจะถูกโหลดจากแคชเบราว์เซอร์เพื่อการใช้งานที่เร็วขึ้น
สำหรับรายละเอียดเพิ่มเติมกรุณาเยี่ยมชม mlc.ai/web-llm
[✅] LLM: การใช้ Web Worker เพื่อสร้างอินสแตนซ์ LLM และสร้างคำตอบ
[✅] การสนทนา: มีการสนับสนุนหลายครั้ง
[✅] PWA
[] การตั้งค่า:
git clone https://github.com/Ryan-yang125/ChatLLM-Web.git
cd ChatLLM-Web
npm i
npm run dev
มิกซ์


