ChatLLM Web
v1.0.0

Английский / 简体中文 / 日本語
Общайтесь с LLM, как Vicuna, полностью в вашем браузере с WebGPU, безопасно, в частном порядке и без сервера. Оборудован от Web-LLM.
Попробуйте сейчас
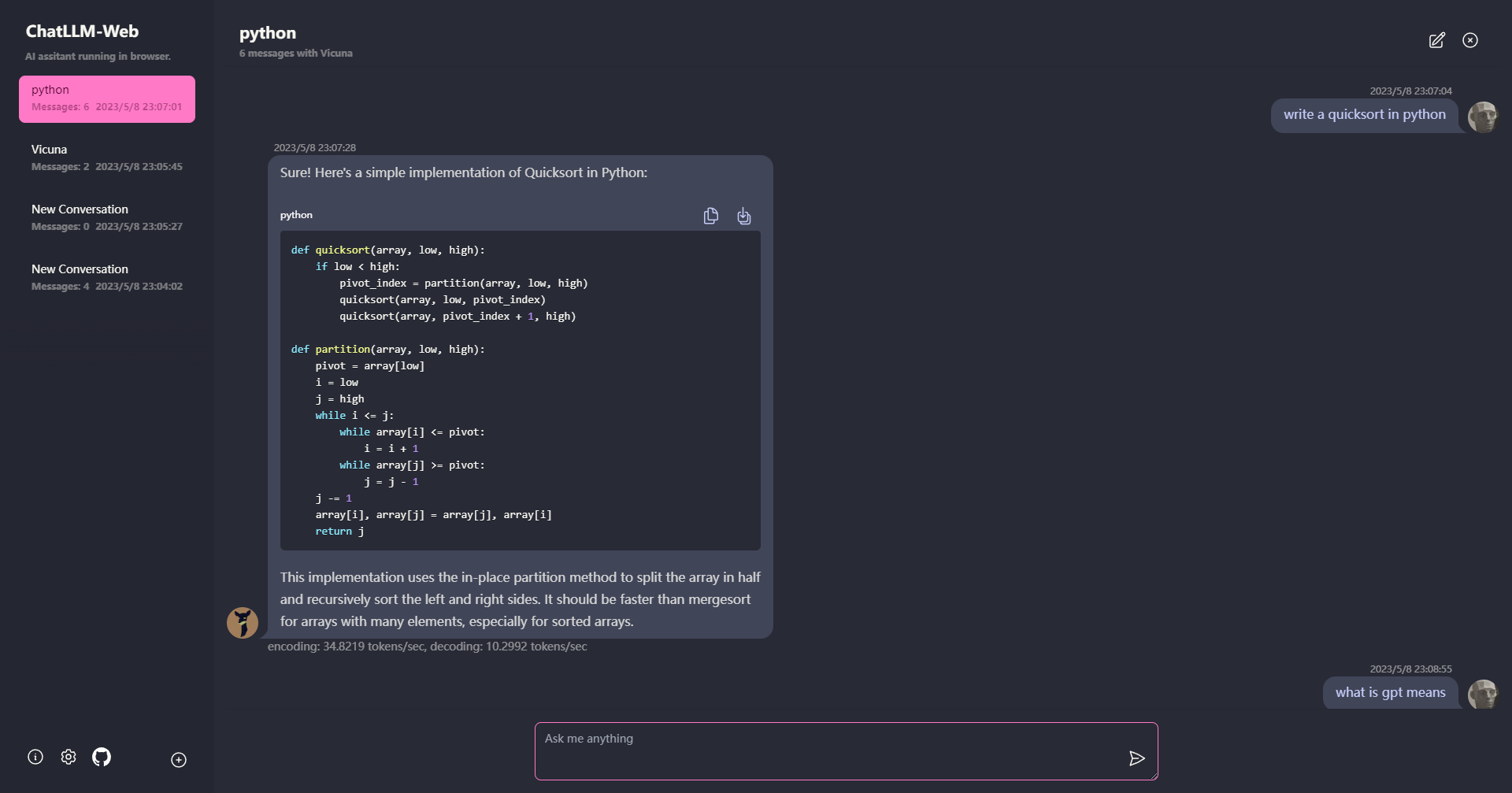
? Все работает внутри браузера без поддержки сервера и ускоряется с помощью WebGPU .
Модель работает в веб -работнике, гарантируя, что она не блокирует пользовательский интерфейс и обеспечивает беспрепятственный опыт.
Легко развернуть бесплатно с одним щелчком на Vercel менее чем за 1 минуту, затем вы получаете собственную сеть Chatllm.
? Модель кэширования поддерживается, поэтому вам нужно загрузить модель только один раз.
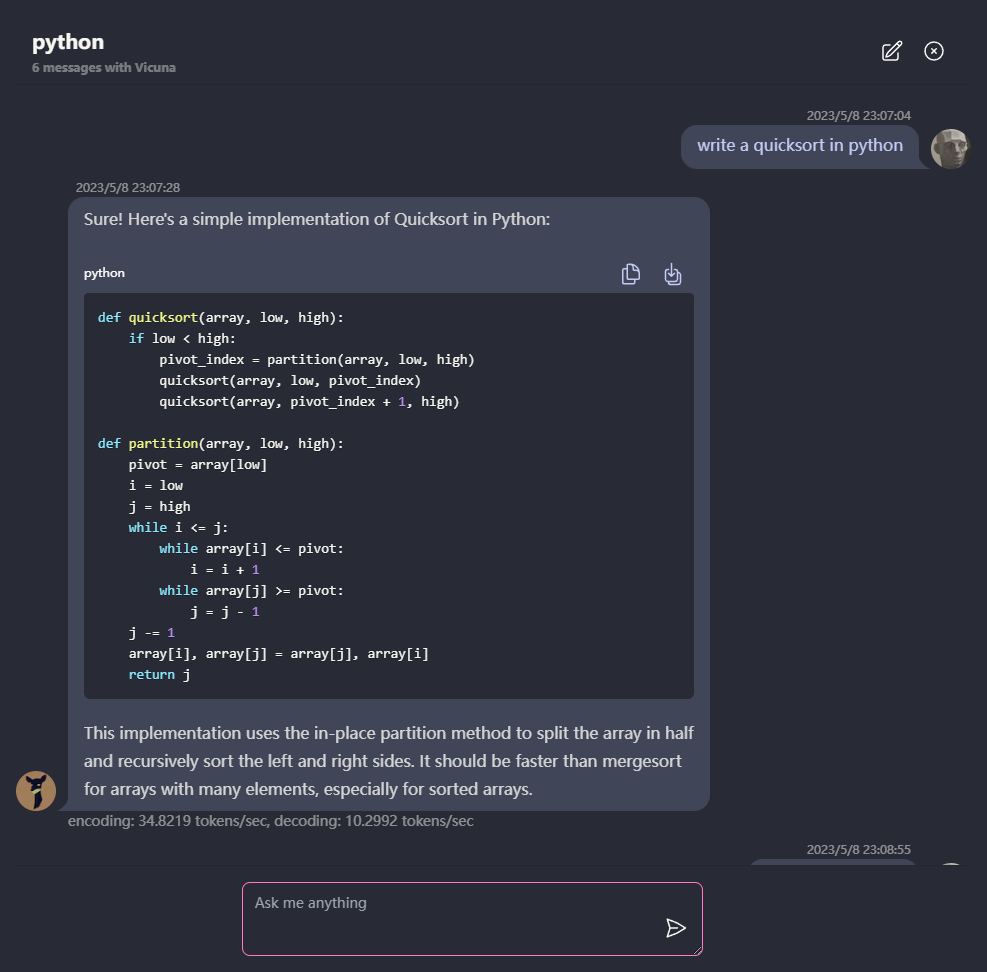
Многоконтраверсийный чат, со всеми данные, хранящиеся локально в браузере для конфиденциальности.
Поддержка отцены и потокового ответа: математика, выделение кода и т. Д.
? Отзывчивый и хорошо разработанный пользовательский интерфейс, включая темный режим.
PWA поддержал, загрузите его и запускается полностью в автономном режиме.
Чтобы использовать это приложение, вам нужен браузер, который поддерживает WebGPU, такой как Chrome 113 или Chrome Canary. Хромированные версии ≤ 112 не поддерживаются.
Вам понадобится графический процессор с около 6,4 ГБ памяти. Если ваш графический процессор имеет меньше памяти, приложение все равно будет работать, но время отклика будет медленнее.
? В первый раз, когда вы используете приложение, вам нужно будет загрузить модель. Для модели Vicuna-7B, которую мы в настоящее время используем, размер загрузки составляет около 4 ГБ. После первоначальной загрузки модель будет загружена из кеша браузера для более быстрого использования.
Для получения более подробной информации, пожалуйста, посетите mlc.ai/web-llm
[✅] LLM: Использование веб -работника для создания экземпляра LLM и создания ответов.
[✅] Разговоры: доступна поддержка с несколькими конверсиями.
[✅] PWA
[] Настройки:
git clone https://github.com/Ryan-yang125/ChatLLM-Web.git
cd ChatLLM-Web
npm i
npm run dev
Грань


