ChatLLM Web
v1.0.0

영어 / 简体中文 / 简体中文
WebGPU를 사용하여 브라우저에서 Vicuna와 같은 LLM과 함께 안전하고 개인적으로 서버가없는 채팅하십시오. Web-Llm으로 구동됩니다.
지금 시도하십시오
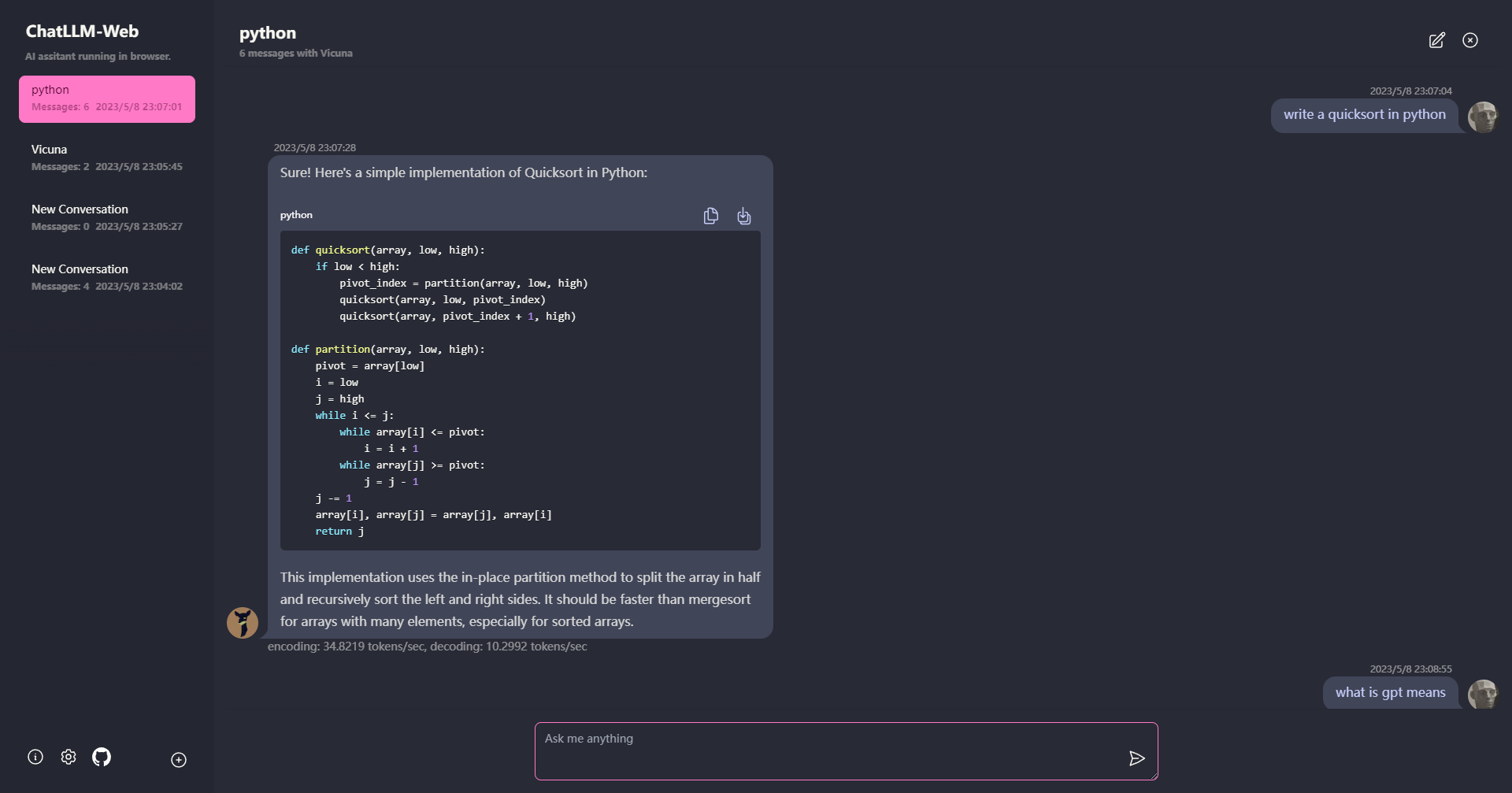
? 모든 것이 서버 지원이없는 브라우저 내부에서 실행되며 WebGPU로 가속 됩니다.
모델은 웹 워커에서 실행되어 사용자 인터페이스를 차단하지 않고 완벽한 경험을 제공합니다.
1 분 이내에 Vercel에서 한 번 클릭하여 무료로 배포 할 수 있습니다. 그런 다음 자신의 Chatllm 웹을 얻을 수 있습니다.
? 모델 캐싱이 지원되므로 모델을 한 번만 다운로드하면됩니다.
모든 데이터가 브라우저에 개인 정보를 위해 로컬로 저장된 다중 수집 채팅.
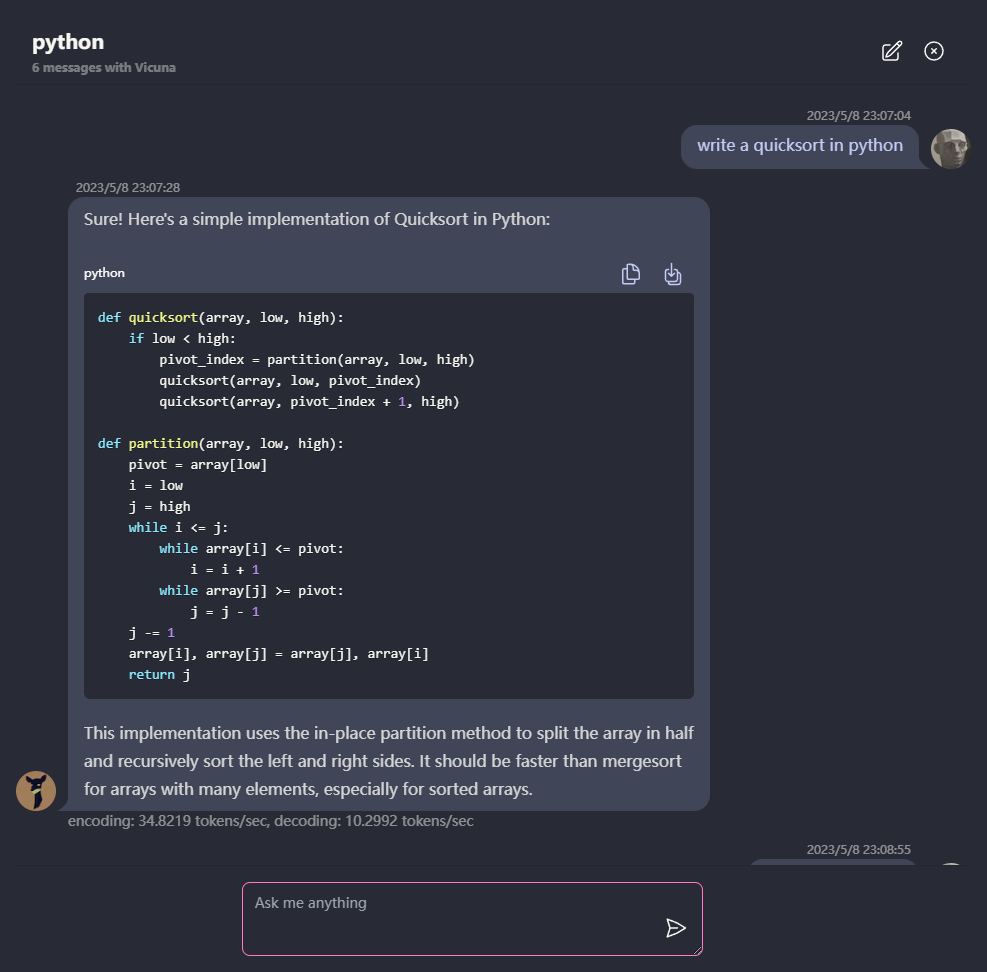
마크 다운 및 스트리밍 응답 지원 : 수학, 코드 하이라이트 등
? 다크 모드를 포함하여 반응 형 및 잘 설계된 UI.
PWA는 지원하고 다운로드하고 완전히 오프라인으로 실행됩니다.
이 앱을 사용하려면 Chrome 113 또는 Chrome Canary와 같은 WebGPU를 지원하는 브라우저가 필요합니다. 크롬 버전 ≤ 112는 지원되지 않습니다.
약 6.4GB의 메모리가있는 GPU가 필요합니다. GPU에 메모리가 적을 경우 앱은 여전히 실행되지만 응답 시간은 느려집니다.
? 앱을 처음 사용하면 모델을 다운로드해야합니다. 현재 사용중인 Vicuna-7B 모델의 경우 다운로드 크기는 약 4GB입니다. 초기 다운로드 후에는 브라우저 캐시에서 모델이로드되어 더 빠른 사용을 위해.
자세한 내용은 mlc.ai/web-llm을 방문하십시오
[:] LLM : 웹 워커를 사용하여 LLM 인스턴스를 생성하고 답변을 생성합니다.
[mult] 대화 : 다중 컨버전 지원이 가능합니다.
[.] PWA
[] 설정 :
git clone https://github.com/Ryan-yang125/ChatLLM-Web.git
cd ChatLLM-Web
npm i
npm run dev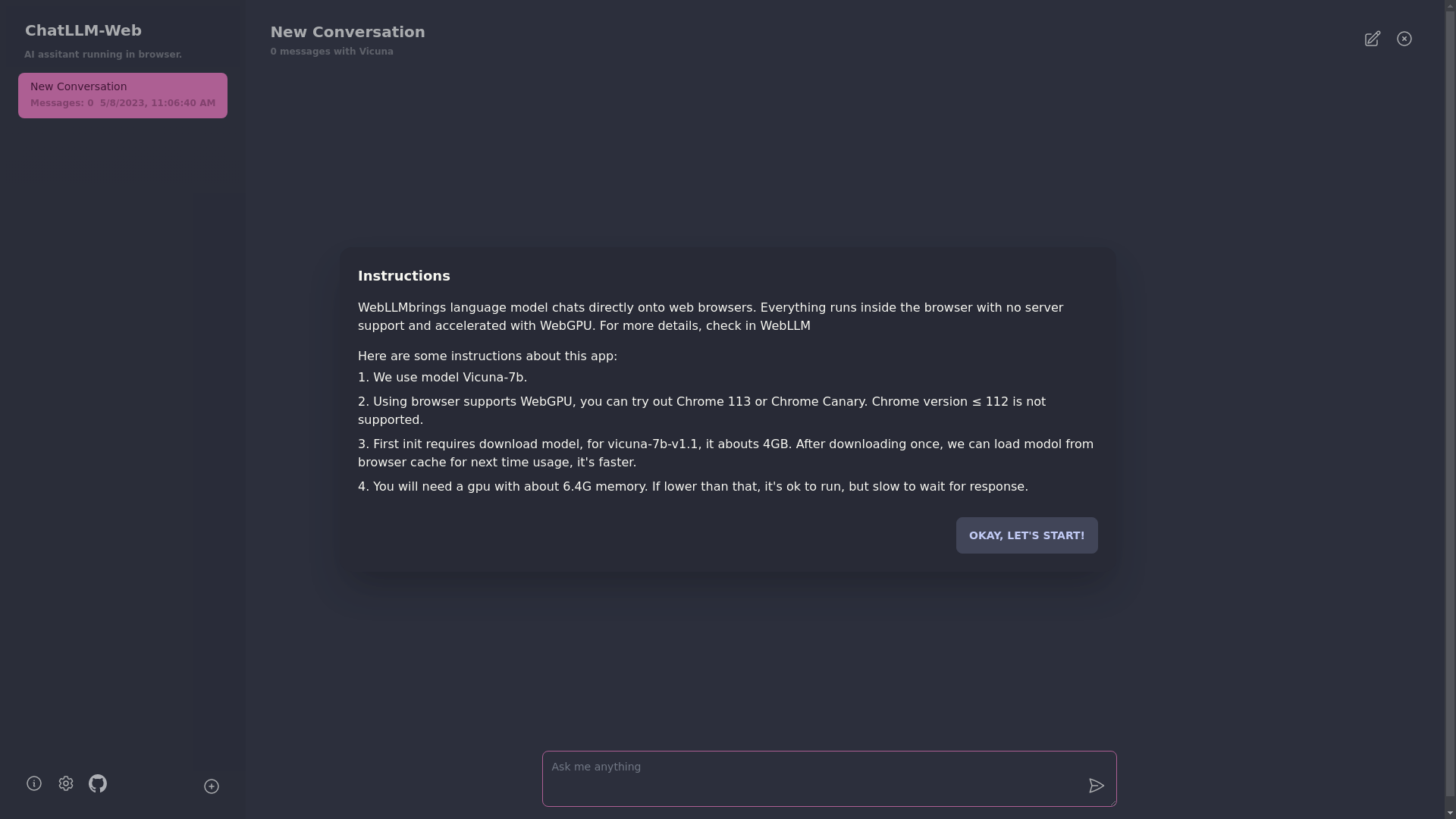
MIT


