ChatLLM Web
v1.0.0

Anglais / 简体中文 / 日本語
Discutez avec LLM comme vicuna totalement dans votre navigateur avec webgpu, en toute sécurité, en privé et sans serveur. Propulsé par Web-llm.
Essayez-le maintenant
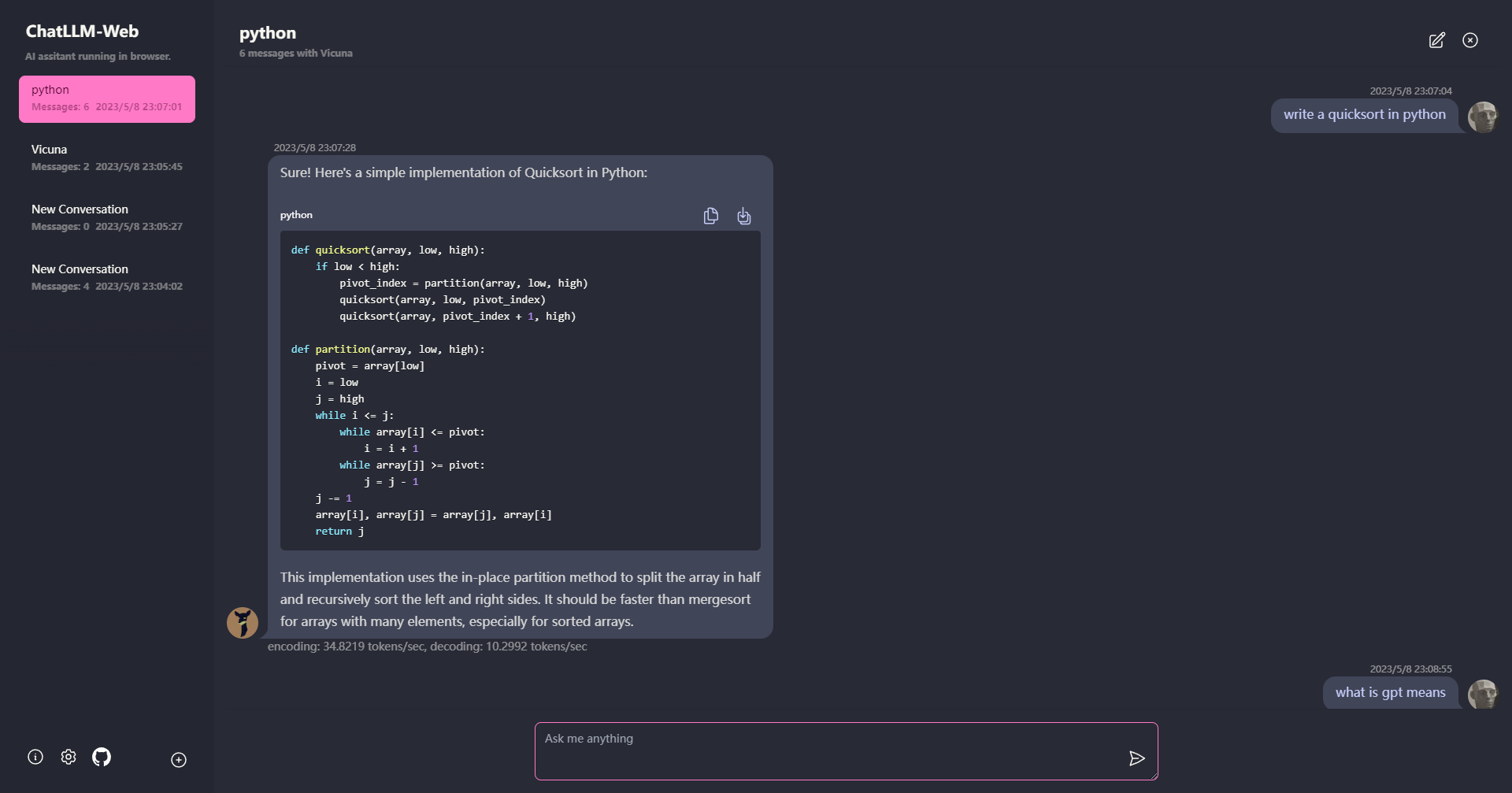
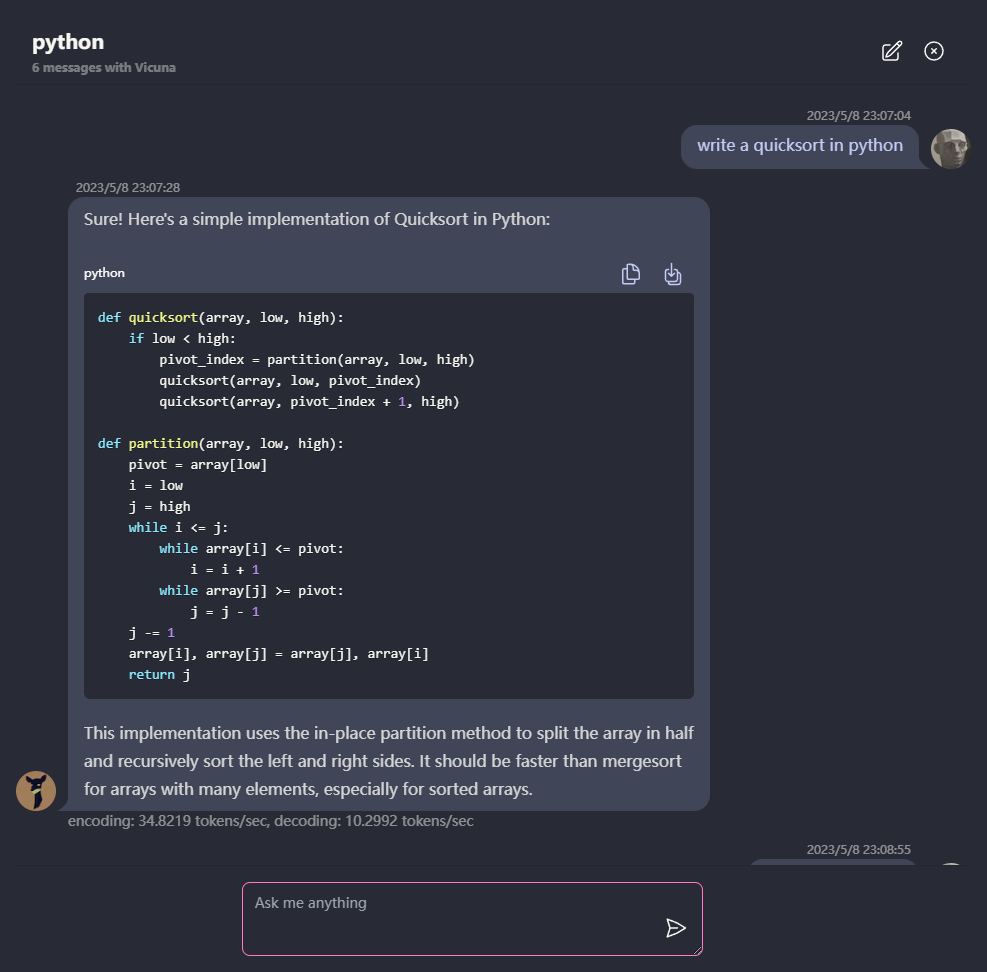
? Tout s'exécute à l'intérieur du navigateur sans support de serveur et est accéléré avec WebGPU .
Le modèle s'exécute dans un travailleur Web, garantissant qu'il ne bloque pas l'interface utilisateur et ne fournit pas une expérience transparente.
Facile à déployer gratuitement avec un clic sur Vercel en moins de 1 minute, vous obtenez votre propre Web Chatllm.
? La mise en cache du modèle est prise en charge, vous n'avez donc besoin de télécharger le modèle qu'une seule fois.
CHAT multi-conversation, avec toutes les données stockées localement dans le navigateur pour la confidentialité.
Prise en charge de la réponse de marque et de streaming: mathématiques, mise en évidence du code, etc.
? UI réactive et bien conçue, y compris le mode sombre.
PWA a pris en charge, le télécharge et fonctionne totalement hors ligne.
Pour utiliser cette application, vous avez besoin d'un navigateur qui prend en charge WebGPU, comme Chrome 113 ou Chrome Canary. Les versions chromées ≤ 112 ne sont pas prises en charge.
Vous aurez besoin d'un GPU avec environ 6,4 Go de mémoire. Si votre GPU a moins de mémoire, l'application s'exécutera toujours, mais le temps de réponse sera plus lent.
? La première fois que vous utilisez l'application, vous devrez télécharger le modèle. Pour le modèle vicuna-7b que nous utilisons actuellement, la taille de téléchargement est d'environ 4 Go. Après le téléchargement initial, le modèle sera chargé à partir du cache du navigateur pour une utilisation plus rapide.
Pour plus de détails, veuillez visiter mlc.ai/web-llm
[✅] LLM: Utilisation du Web Worker pour créer une instance LLM et générer des réponses.
[✅] Conversations: le support multi-conversation est disponible.
[✅] PWA
[] Paramètres:
git clone https://github.com/Ryan-yang125/ChatLLM-Web.git
cd ChatLLM-Web
npm i
npm run dev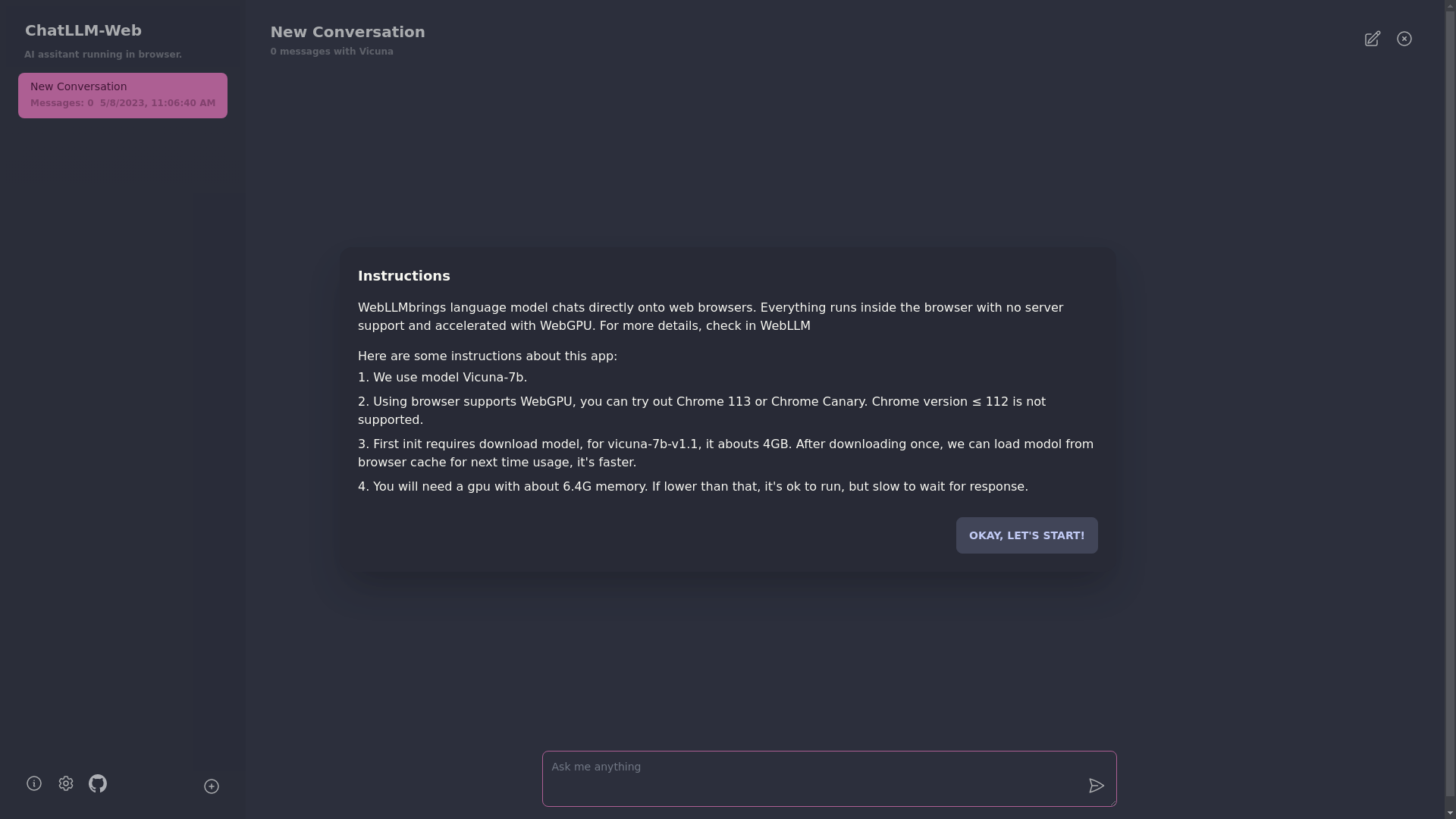
Mit


