ChatLLM Web
v1.0.0

英語 /简体中文 /日本語
WebGPUでブラウザで完全にVicunaのようなLLMとチャットして、安全に、個人的に、そしてサーバーなしでチャットします。 Web-llmを搭載しています。
今すぐ試してみてください
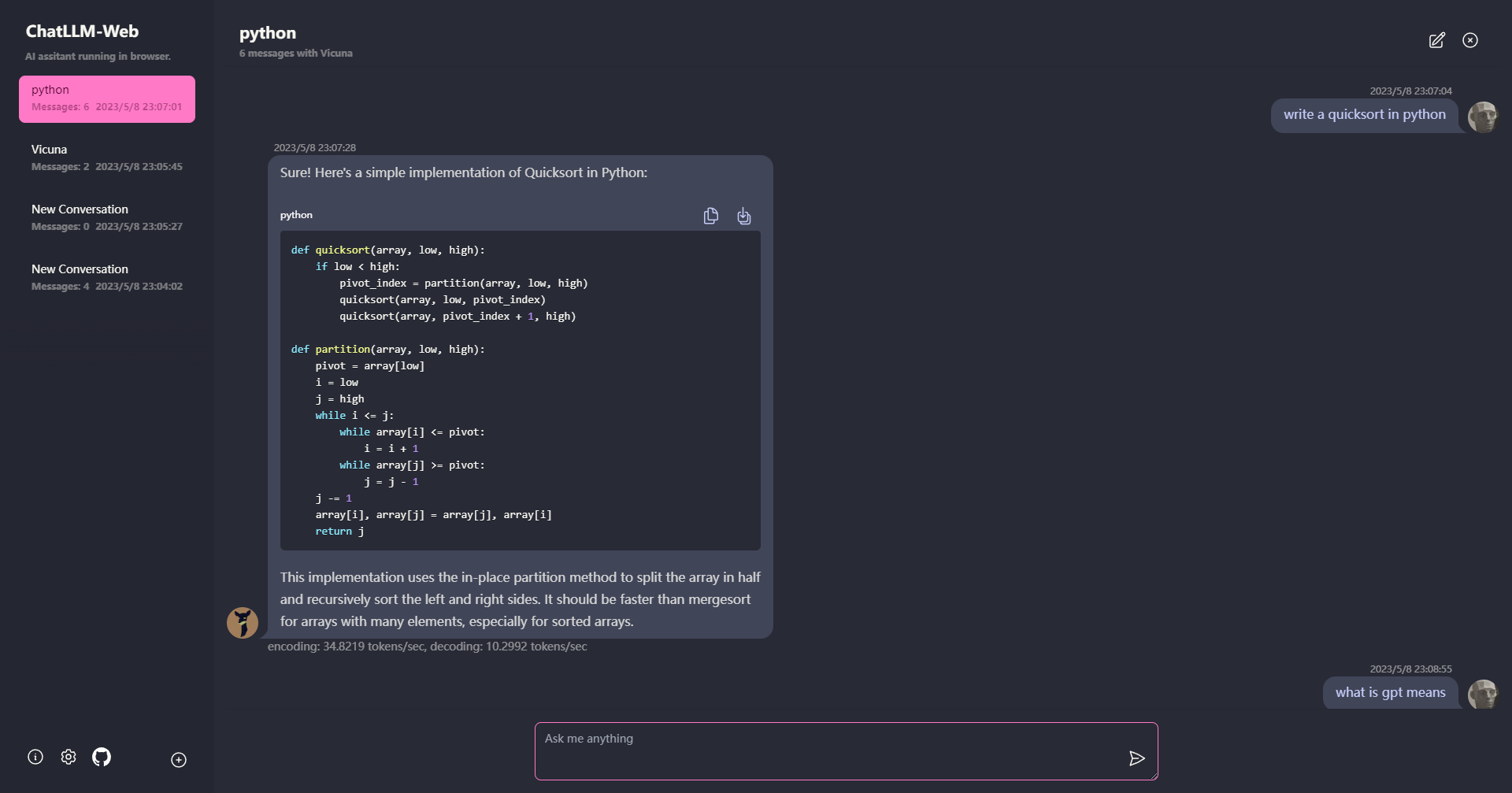
?すべてがサーバーサポートなしでブラウザ内で実行され、 WebGPUで加速されます。
モデルはWebワーカーで実行され、ユーザーインターフェイスをブロックしないようにし、シームレスなエクスペリエンスを提供します。
1分以内にvercelをワンクリックして無料で簡単に展開できます。その後、独自のChatllm Webを取得できます。
?モデルキャッシュがサポートされているため、モデルを1回ダウンロードするだけです。
プライバシーのためにブラウザにローカルに保存されているすべてのデータとともに、マルチコンバージョンチャット。
マークダウンとストリーミング応答のサポート:数学、コードハイライトなど。
?ダークモードを含む、応答性の高い設計されたUI。
PWAはサポートし、ダウンロードし、完全にオフラインで実行しました。
このアプリを使用するには、Chrome 113やChrome CanaryなどのWebGPUをサポートするブラウザが必要です。 Chromeバージョン≤112はサポートされていません。
約6.4GBのメモリを備えたGPUが必要です。 GPUのメモリが少ない場合でも、アプリは実行されますが、応答時間は遅くなります。
?アプリを初めて使用するときは、モデルをダウンロードする必要があります。現在使用しているVicuna-7Bモデルの場合、ダウンロードサイズは約4GBです。最初のダウンロード後、モデルはブラウザキャッシュからロードされ、より速く使用されます。
詳細については、mlc.ai/web-llmをご覧ください
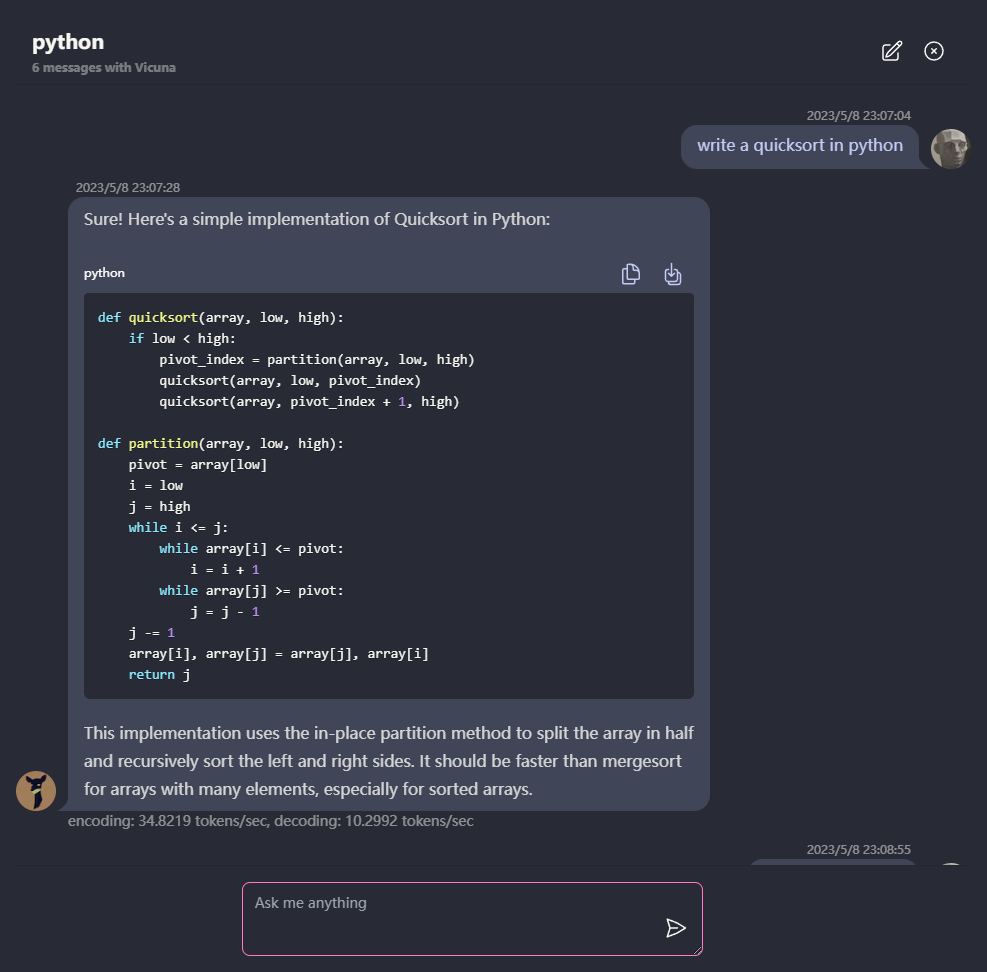
[✅] LLM:Webワーカーを使用してLLMインスタンスを作成し、回答を生成します。
[✅]会話:マルチコンバージョンサポートが利用可能です。
[✅] PWA
[] 設定:
git clone https://github.com/Ryan-yang125/ChatLLM-Web.git
cd ChatLLM-Web
npm i
npm run dev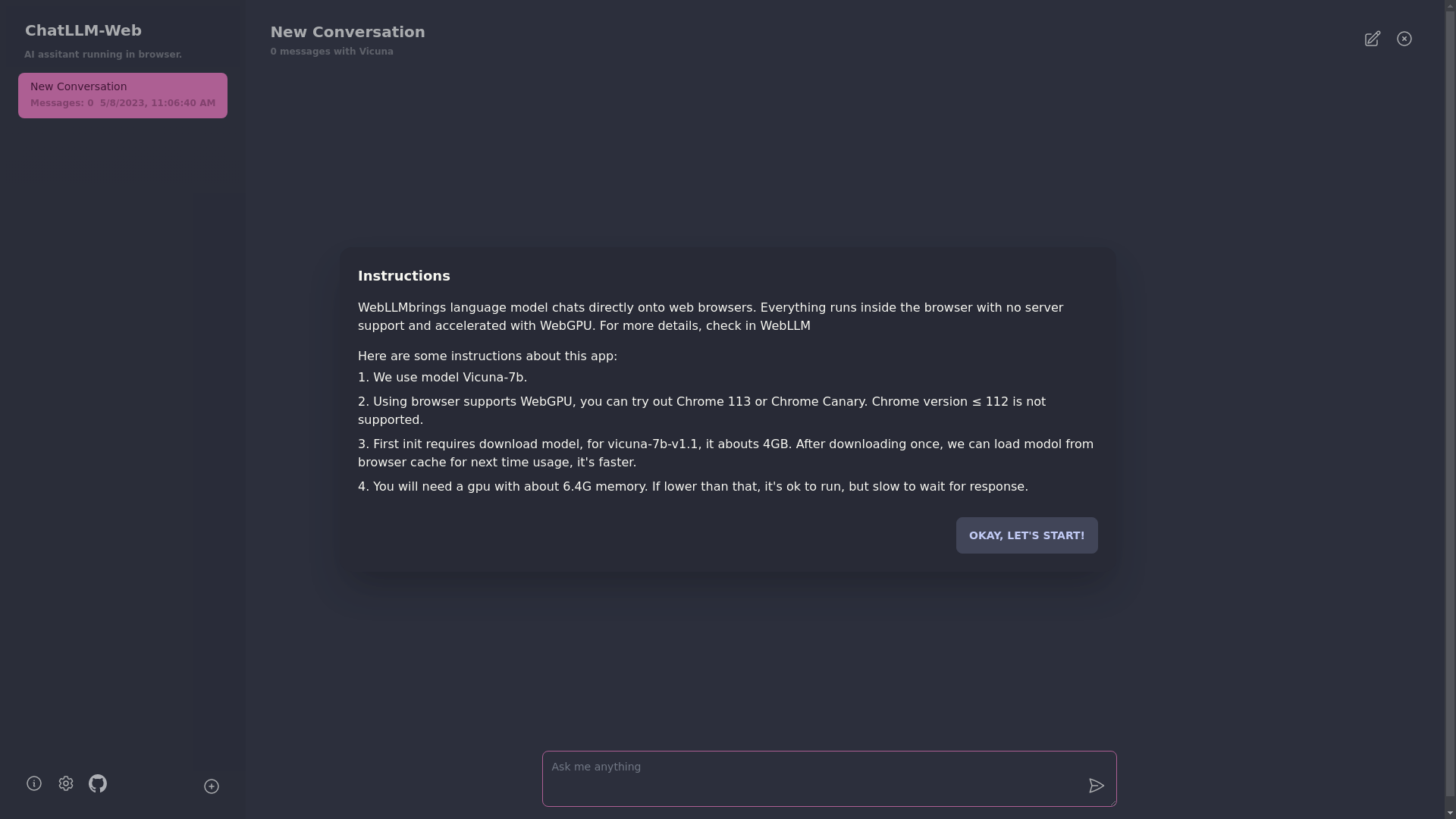
mit


