ChatLLM Web
v1.0.0

Bahasa Inggris / 简体中文 / 日本語
Obrolan dengan LLM seperti Vicuna sepenuhnya di browser Anda dengan WebGPU, dengan aman, pribadi, dan tanpa server. Didukung oleh web-llm.
Cobalah sekarang
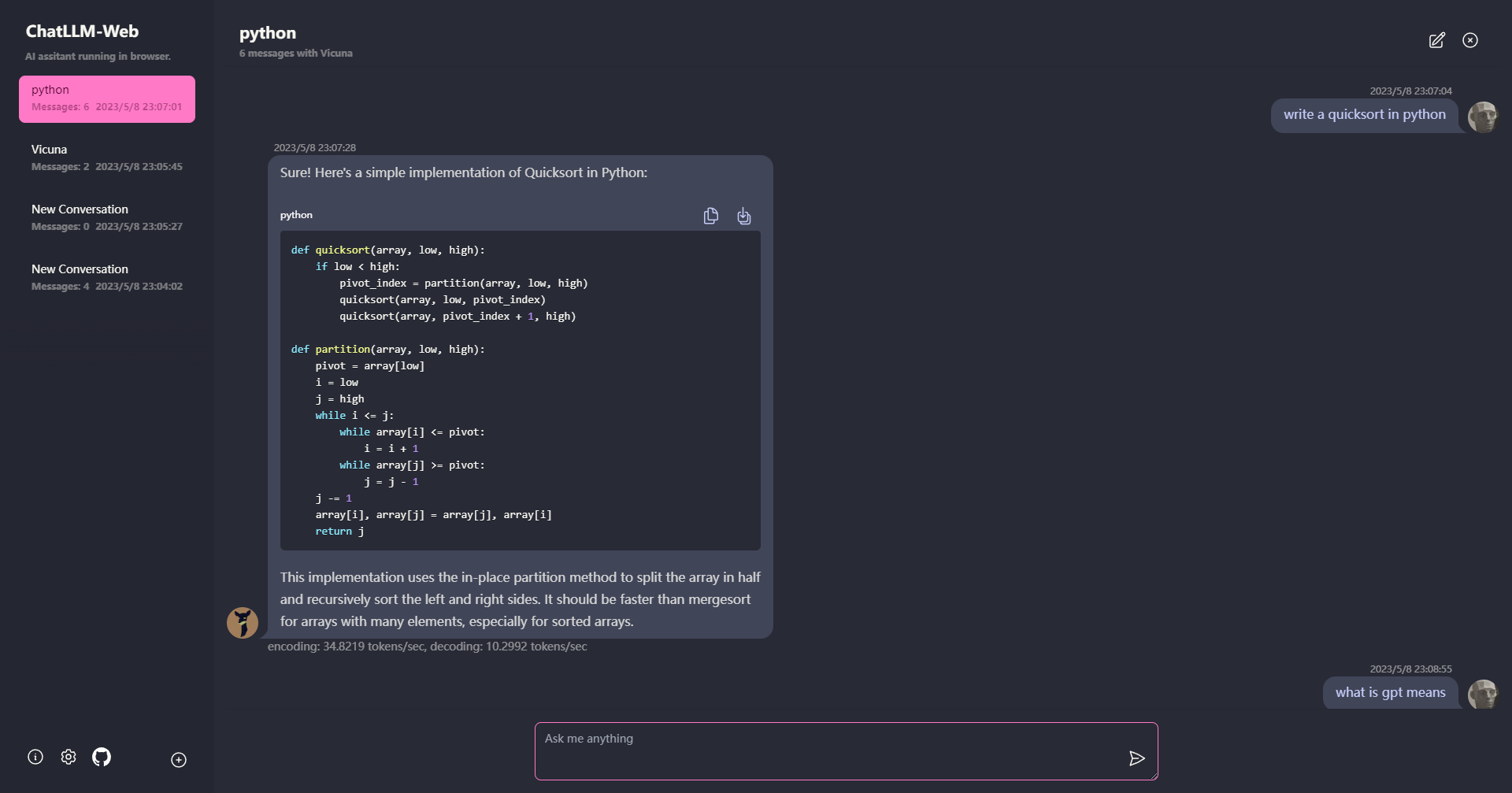
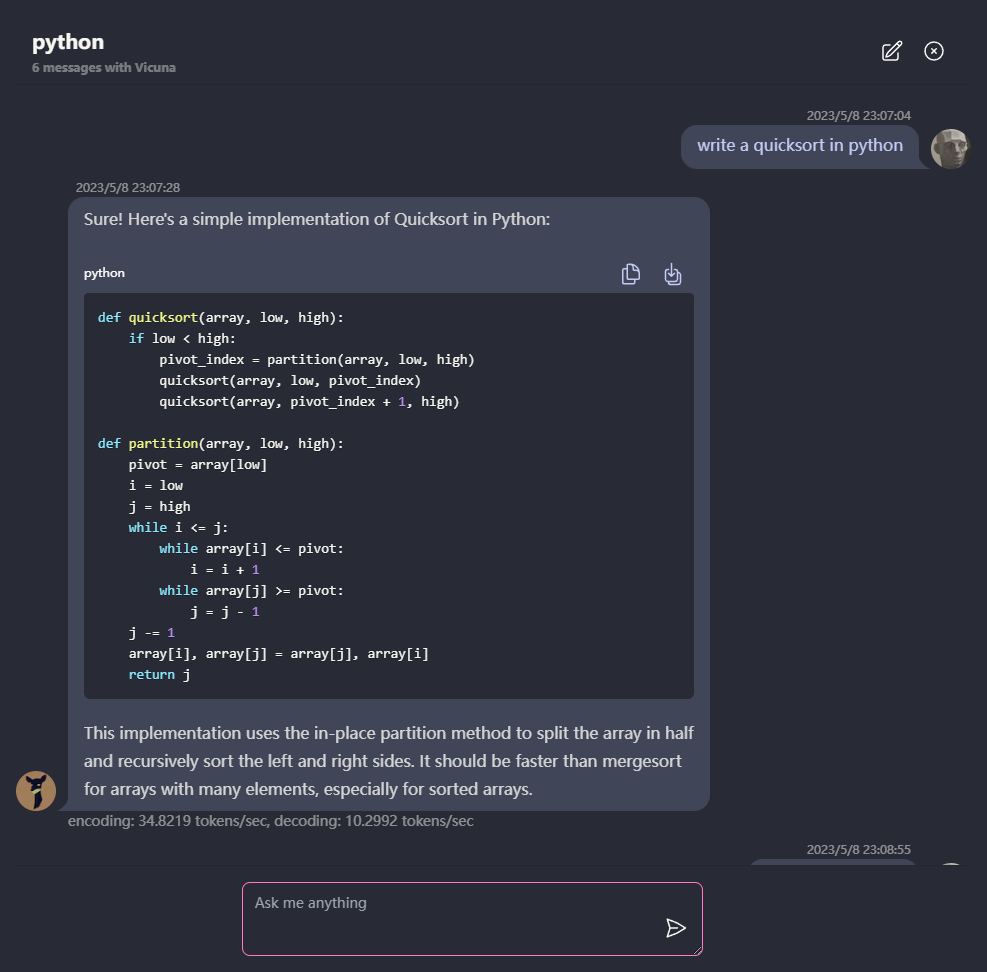
? Semuanya berjalan di dalam browser tanpa dukungan server dan dipercepat dengan WebGPU .
Model berjalan dalam pekerja web, memastikan bahwa itu tidak memblokir antarmuka pengguna dan memberikan pengalaman yang mulus.
Mudah digunakan secara gratis dengan satu klik di Vercel dalam waktu kurang dari 1 menit, maka Anda mendapatkan web chatllm Anda sendiri.
? Model caching didukung, jadi Anda hanya perlu mengunduh model sekali.
Obrolan multi-konversi, dengan semua data yang disimpan secara lokal di browser untuk privasi.
Markdown dan Dukungan Respons Streaming: Matematika, penyorotan kode, dll.
? UI yang responsif dan dirancang dengan baik, termasuk Mode Gelap.
PWA didukung, unduh dan jalankan benar -benar offline.
Untuk menggunakan aplikasi ini, Anda memerlukan browser yang mendukung WebGPU, seperti Chrome 113 atau Chrome Canary. Versi krom ≤ 112 tidak didukung.
Anda akan membutuhkan GPU dengan sekitar 6.4GB memori. Jika GPU Anda memiliki lebih sedikit memori, aplikasi masih akan berjalan, tetapi waktu respons akan lebih lambat.
? Pertama kali Anda menggunakan aplikasi ini, Anda perlu mengunduh model. Untuk model Vicuna-7b yang saat ini kami gunakan, ukuran unduhan sekitar 4GB. Setelah unduhan awal, model akan dimuat dari cache browser untuk penggunaan yang lebih cepat.
Untuk detail lebih lanjut, silakan kunjungi mlc.ai/web-llm
[✅] LLM: Menggunakan pekerja web untuk membuat instance LLM dan menghasilkan jawaban.
[✅] Percakapan: Dukungan multi-konversi tersedia.
[✅] PWA
[] Pengaturan:
git clone https://github.com/Ryan-yang125/ChatLLM-Web.git
cd ChatLLM-Web
npm i
npm run dev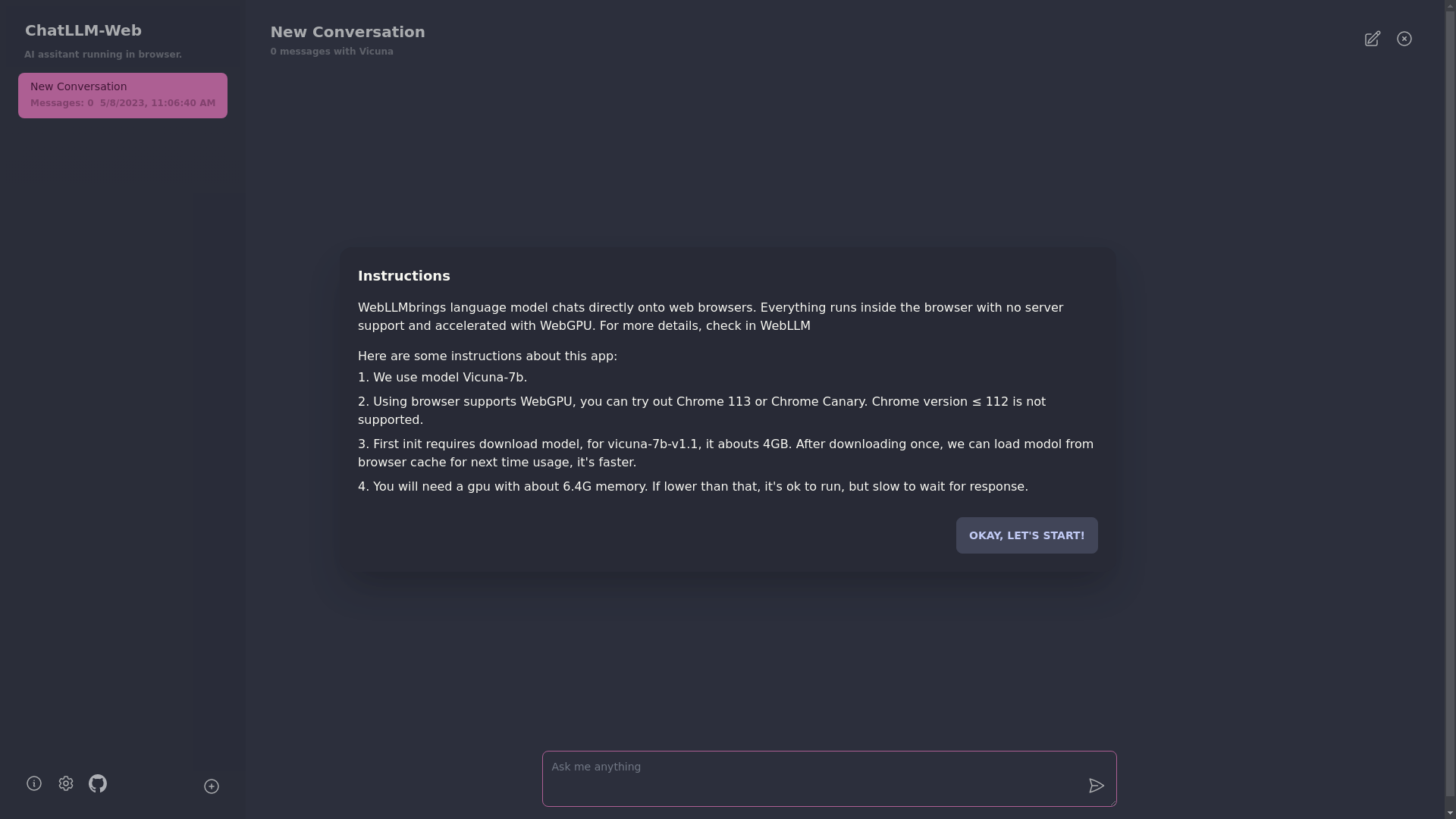
Mit


