ChatLLM Web
v1.0.0

Inglês / 简体中文 / 日本語
Converse com o LLM como Vicuna totalmente no seu navegador com o WebGPU, com segurança, privada e sem servidor. Alimentado por web-llm.
Experimente agora
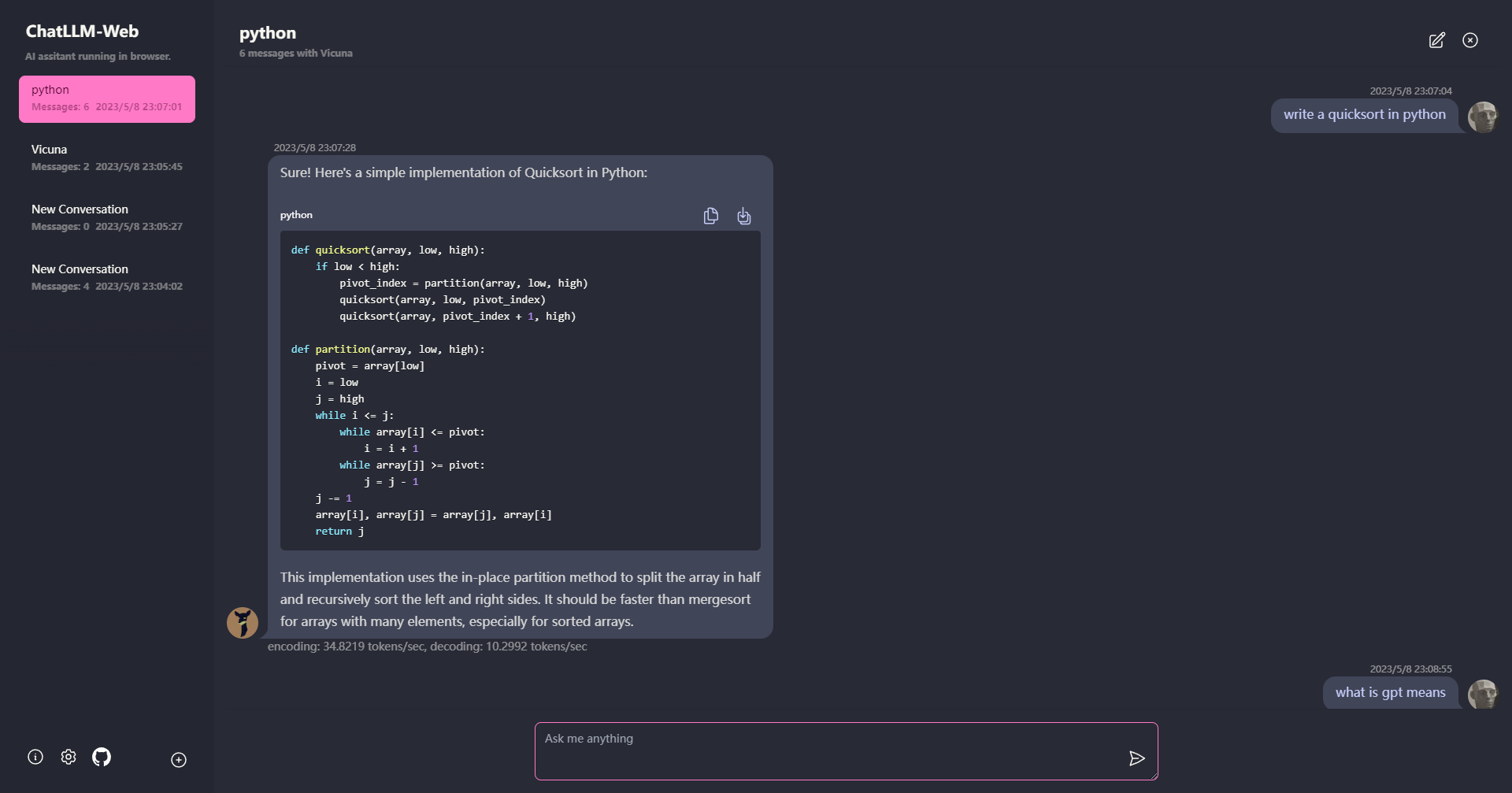
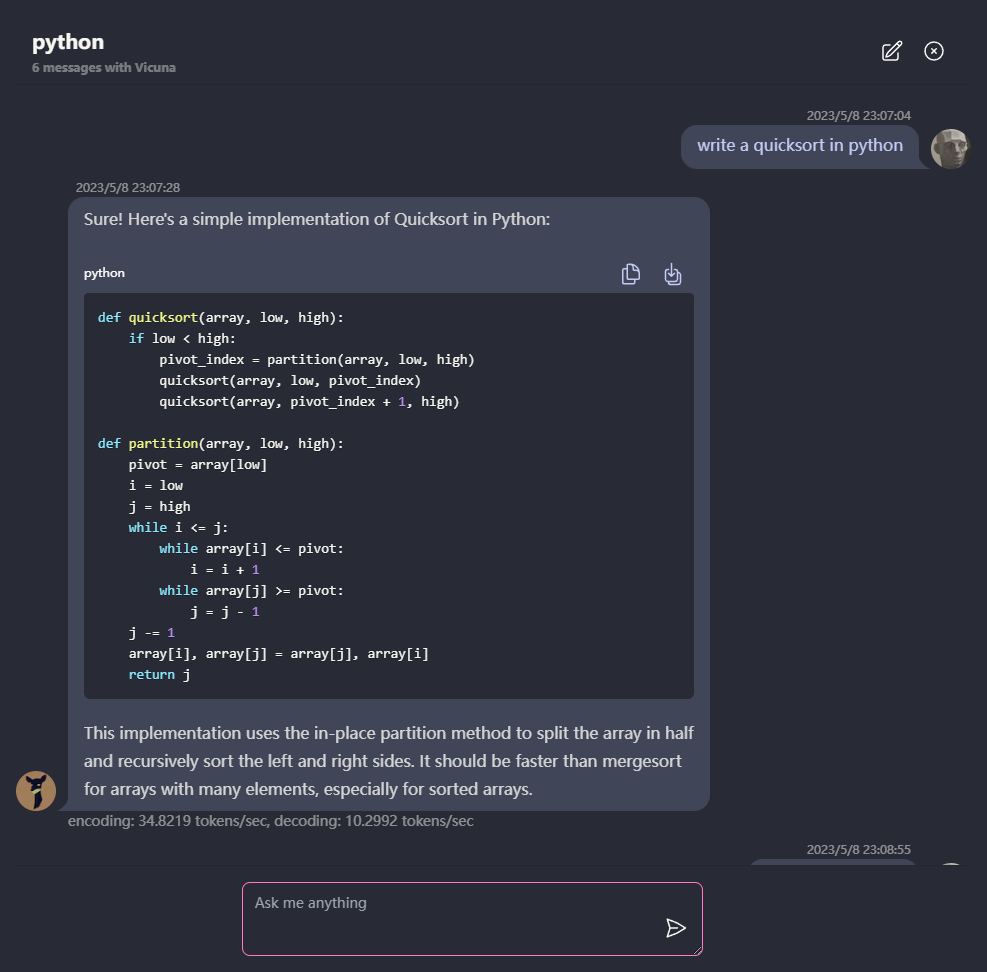
? Tudo corre dentro do navegador sem suporte ao servidor e é acelerado com o WebGPU .
O modelo é executado em um trabalhador da web, garantindo que não bloqueie a interface do usuário e proporcionando uma experiência perfeita.
Fácil de implantar gratuitamente com um clique no Vercel em menos de 1 minuto, depois você obtém sua própria web Chatllm.
? O cache do modelo é suportado, portanto, você só precisa baixar o modelo uma vez.
CHAT MULTI-CONVERSAÇÃO, com todos os dados armazenados localmente no navegador para privacidade.
Suporte de resposta a marcação e streaming: matemática, destaque de código, etc.
? UI responsiva e bem projetada, incluindo o modo escuro.
A PWA apoiou, baixe e corra totalmente offline.
Para usar este aplicativo, você precisa de um navegador que suporta WebGPU, como Chrome 113 ou Chrome Canary. As versões do Chrome ≤ 112 não são suportadas.
Você precisará de uma GPU com cerca de 6,4 GB de memória. Se a sua GPU tiver menos memória, o aplicativo ainda será executado, mas o tempo de resposta será mais lento.
? Na primeira vez que você usa o aplicativo, você precisará baixar o modelo. Para o modelo Vicuna-7b que estamos usando atualmente, o tamanho do download é de cerca de 4 GB. Após o download inicial, o modelo será carregado no cache do navegador para uso mais rápido.
Para mais detalhes, visite mlc.ai/web-llm
[✅] LLM: Usando o Web Worker para criar uma instância LLM e gerar respostas.
[✅] Conversas: o suporte a múltiplas conversação está disponível.
[✅] pwa
[] Configurações:
git clone https://github.com/Ryan-yang125/ChatLLM-Web.git
cd ChatLLM-Web
npm i
npm run dev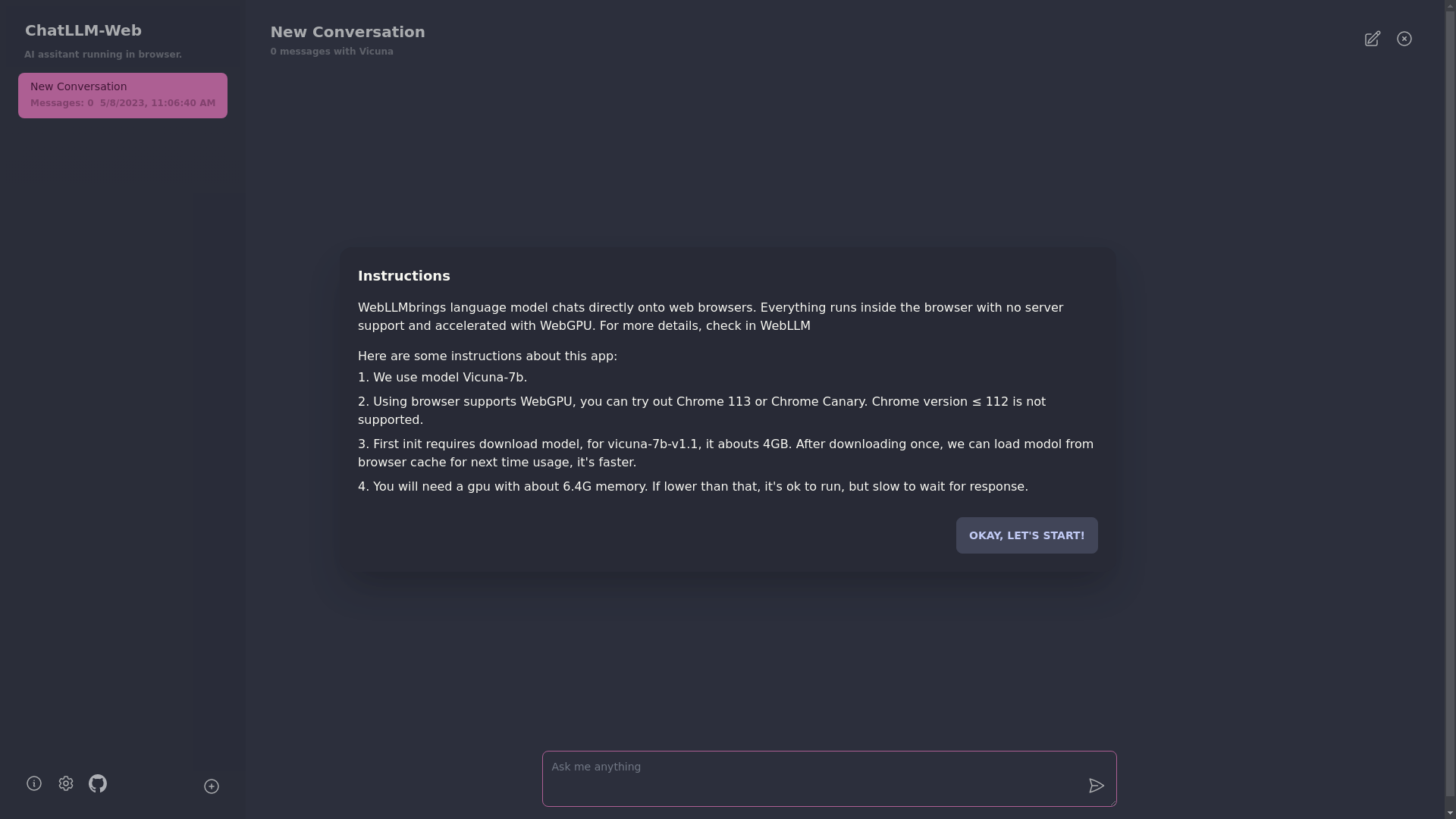
Mit


