ChatLLM Web
v1.0.0

Inglés / 简体中文 / 日本語
Chatee con LLM como Vicuna totalmente en su navegador con WebGPU, de manera segura, privada y sin servidor. Impulsado por Web-LLM.
Pruébalo ahora
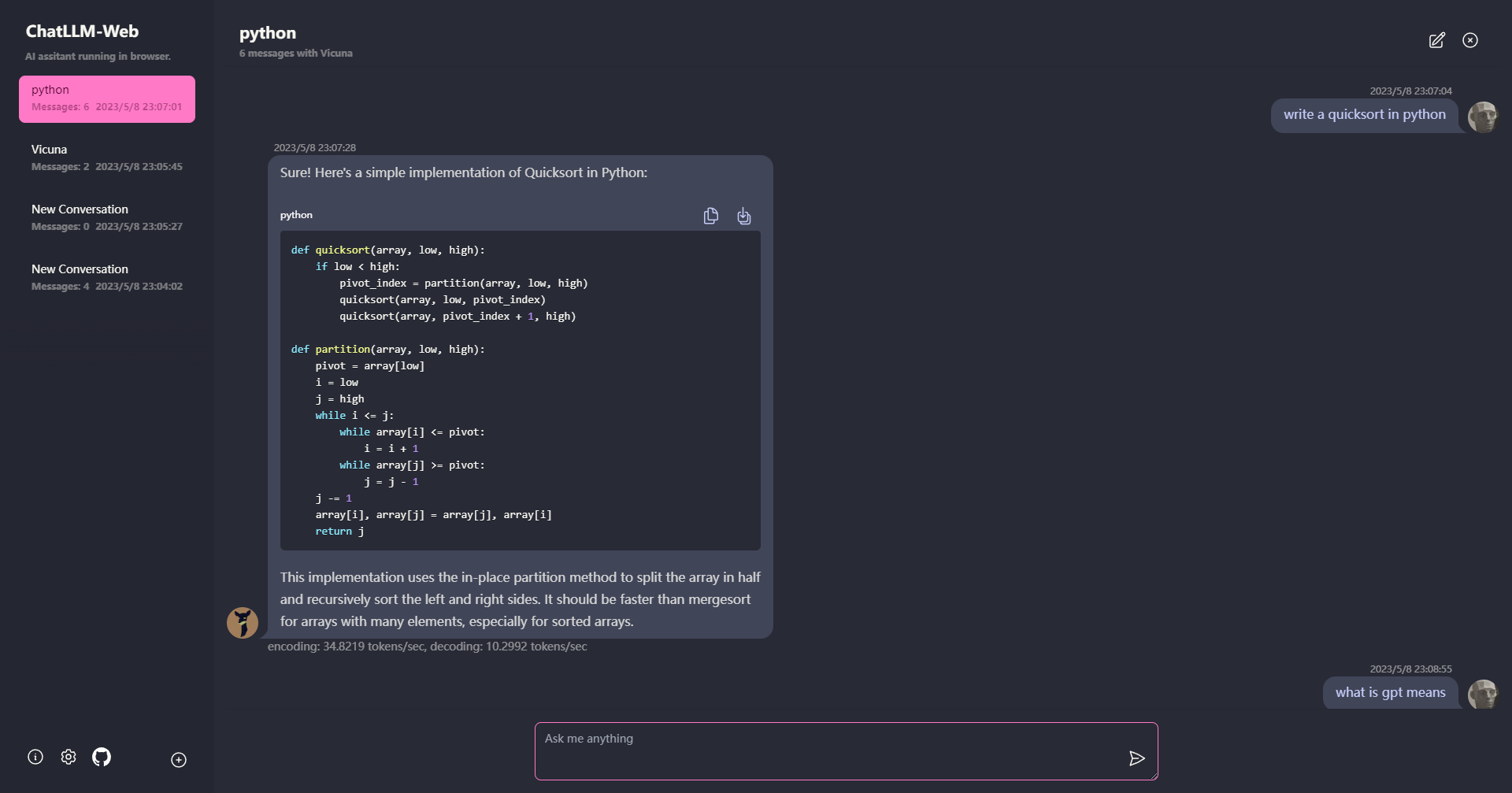
? Todo se ejecuta dentro del navegador sin soporte del servidor y se acelera con WebGPU .
El modelo se ejecuta en un trabajador web, asegurando que no bloquee la interfaz de usuario y proporcione una experiencia perfecta.
Fácil de implementar de forma gratuita con un clic en Vercel en menos de 1 minuto, luego obtendrá su propia Web Chatllm.
? El almacenamiento en caché del modelo es compatible, por lo que solo necesita descargar el modelo una vez.
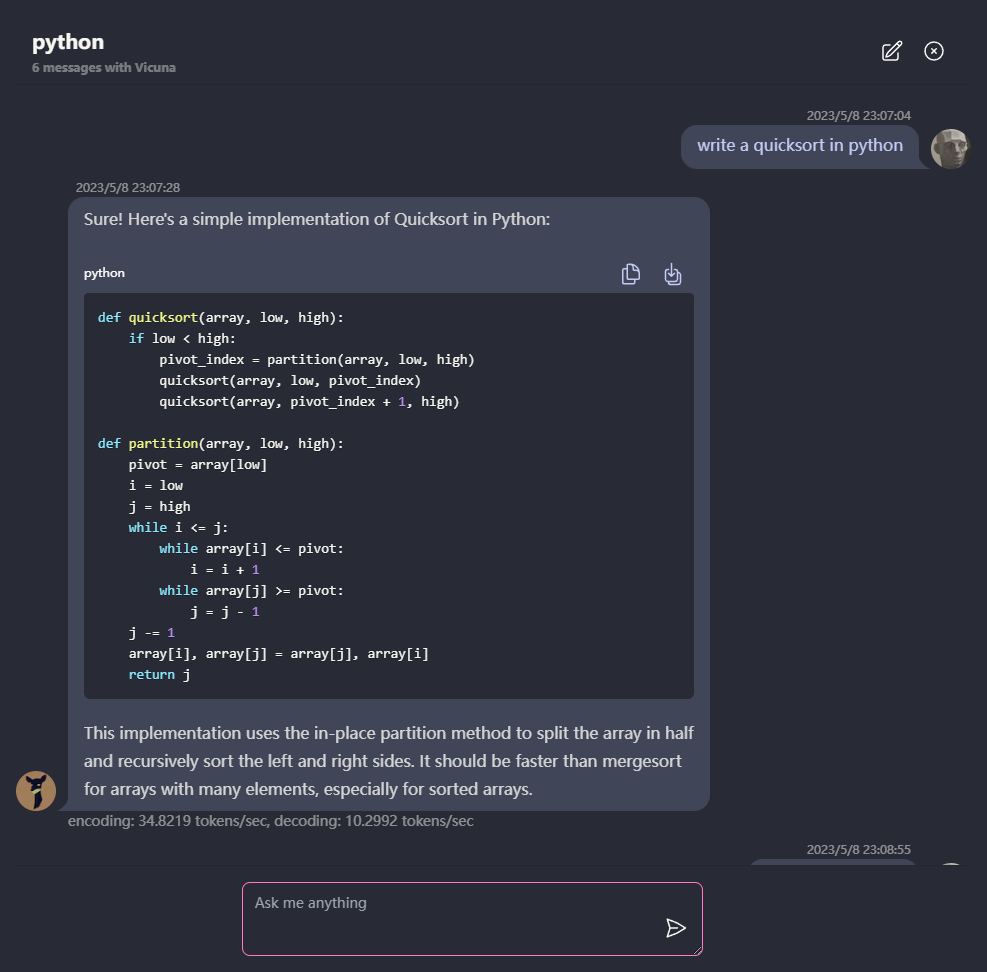
Chat múltiple de conversación, con todos los datos almacenados localmente en el navegador para la privacidad.
Soporte de respuesta a markdown y transmisión: matemáticas, resaltado de código, etc.
? UI receptiva y bien diseñada, incluido el modo oscuro.
PWA compatió, descargue y ejecuta totalmente fuera de línea.
Para usar esta aplicación, necesita un navegador que admita WebGPU, como Chrome 113 o Chrome Canary. Las versiones de Chrome ≤ 112 no son compatibles.
Necesitará una GPU con aproximadamente 6.4 GB de memoria. Si su GPU tiene menos memoria, la aplicación aún se ejecutará, pero el tiempo de respuesta será más lento.
? La primera vez que use la aplicación, deberá descargar el modelo. Para el modelo Vicuna-7B que estamos utilizando actualmente, el tamaño de descarga es de aproximadamente 4 GB. Después de la descarga inicial, el modelo se cargará desde el caché del navegador para un uso más rápido.
Para más detalles, visite mlc.ai/web-llm
[✅] LLM: Uso de Web Worker para crear una instancia de LLM y generar respuestas.
[✅] Conversaciones: el soporte de conversación múltiple está disponible.
[✅] PWA
[] Ajustes:
git clone https://github.com/Ryan-yang125/ChatLLM-Web.git
cd ChatLLM-Web
npm i
npm run dev
MIT


