ChatLLM Web
v1.0.0

Englisch / 简体中文 / 日本語
Chatten Sie mit LLM wie Vicuna ganz in Ihrem Browser mit WebGPU sicher, privat und ohne Server. Powered von Web-llm.
Versuchen Sie es jetzt
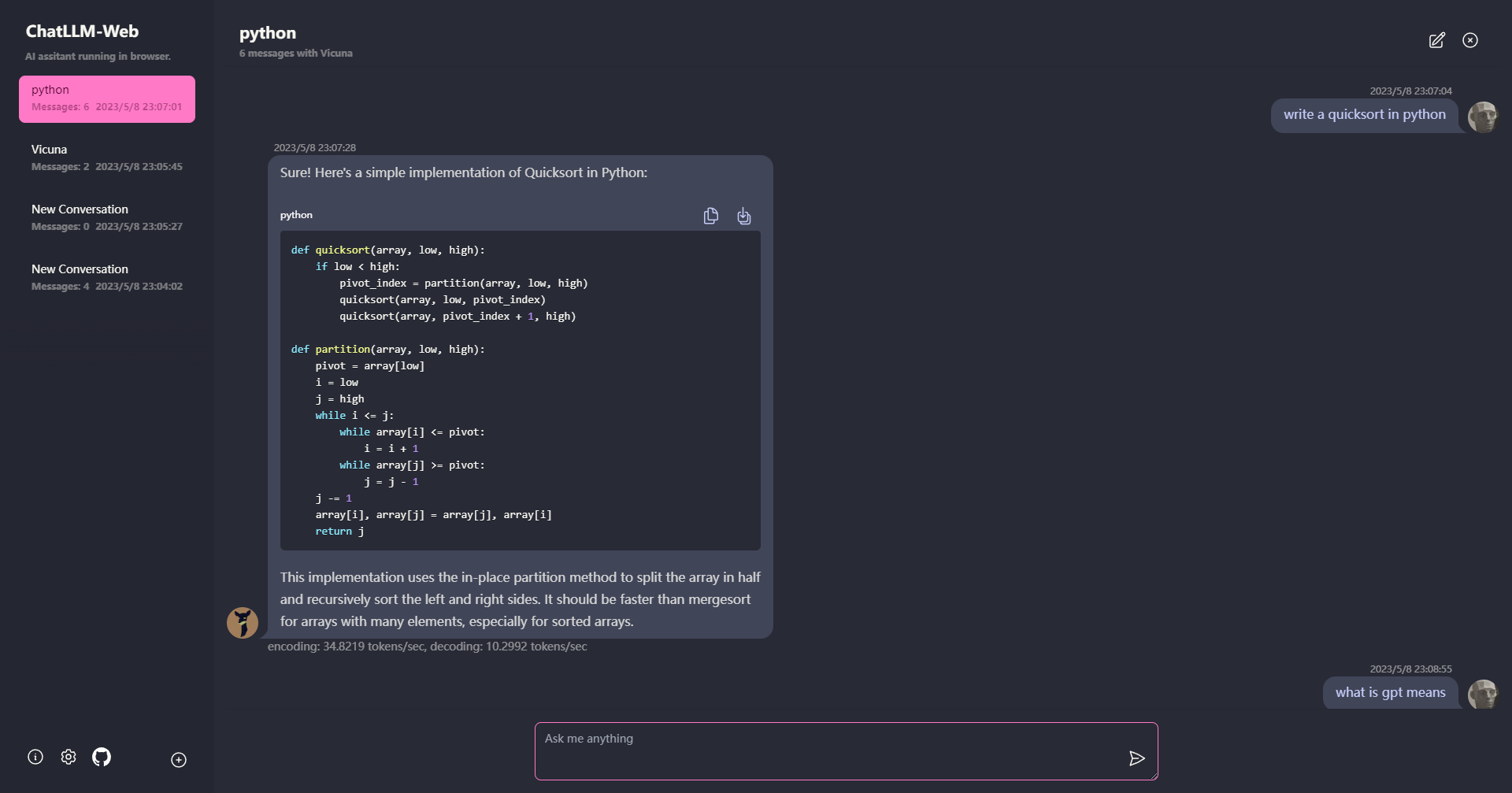
? Alles läuft im Browser ohne Serverunterstützung und wird mit WebGPU beschleunigt .
Das Modell wird in einem Webarbeiter ausgeführt, um sicherzustellen, dass es die Benutzeroberfläche nicht blockiert und eine nahtlose Erfahrung bietet.
Einfach kostenlos mit einem Klick auf Vercel in weniger als 1 Minute bereitgestellt und erhalten Ihr eigenes Chatllm-Web.
? Modell Caching wird unterstützt, sodass Sie das Modell nur einmal herunterladen müssen.
Multi-Conversation-Chat, wobei alle Daten lokal im Browser für Privatsphäre gespeichert sind.
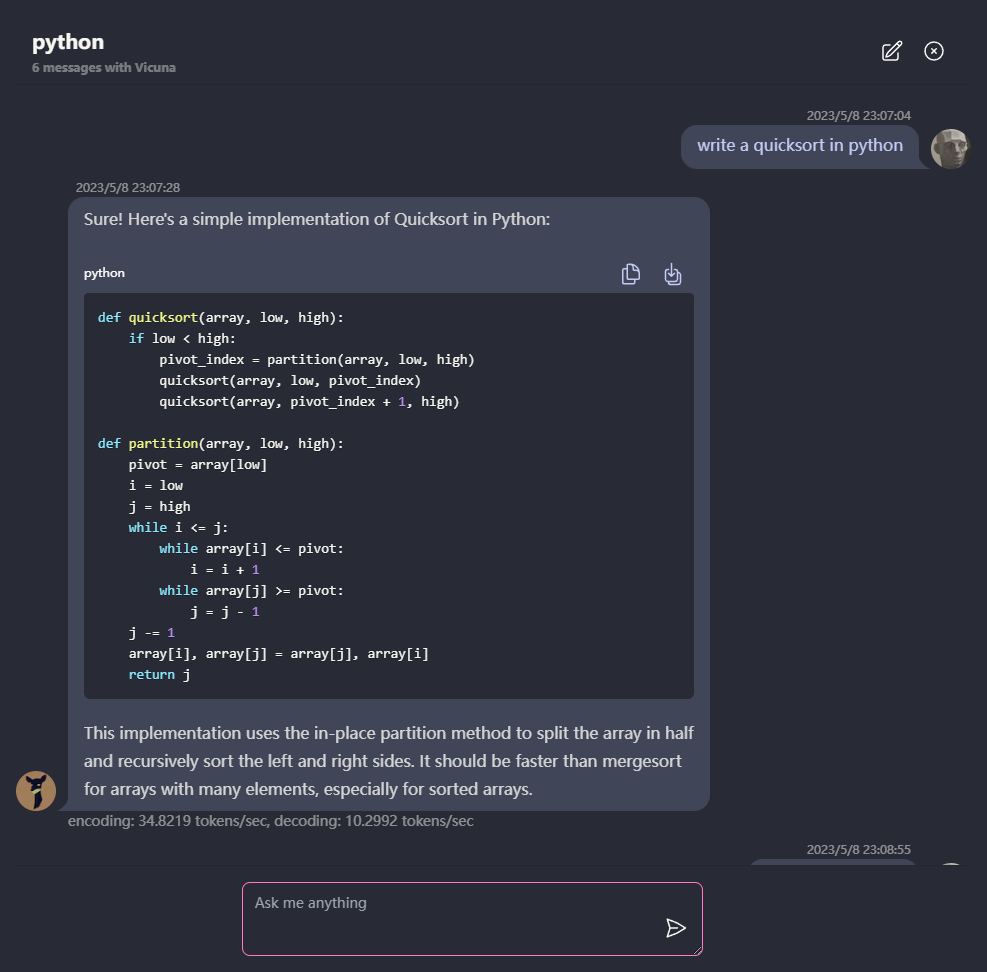
Reaktionsunterstützung für Markdown und Streaming: Mathematik, Code -Hervorhebung usw.
? Reaktionsschnelle und gut gestaltete Benutzeroberfläche, einschließlich dunkler Modus.
PWA unterstützte, laden Sie es herunter und rennen Sie sie total offline.
Um diese App zu verwenden, benötigen Sie einen Browser, der WebGPU unterstützt, z. B. Chrome 113 oder Chrome Canary. Chromversionen ≤ 112 werden nicht unterstützt.
Sie benötigen eine GPU mit etwa 6,4 GB Speicher. Wenn Ihre GPU weniger Speicher hat, wird die App weiterhin ausgeführt, aber die Antwortzeit wird langsamer.
? Wenn Sie die App zum ersten Mal verwenden, müssen Sie das Modell herunterladen. Für das von uns derzeit verwendete Vicuna-7b-Modell beträgt die Downloadgröße etwa 4 GB. Nach dem ersten Download wird das Modell für eine schnellere Verwendung aus dem Browser -Cache geladen.
Weitere Informationen finden Sie unter mlc.ai/web-llm
[✅] LLM: Verwenden Sie Web Worker, um eine LLM -Instanz zu erstellen und Antworten zu generieren.
[✅] Gespräche: Support für Multi-Konvertierungen ist verfügbar.
[✅] PWA
[] Einstellungen:
git clone https://github.com/Ryan-yang125/ChatLLM-Web.git
cd ChatLLM-Web
npm i
npm run dev
MIT


