ค่าเฉลี่ยครูเป็นแบบอย่างที่ดีกว่า
Paper ---- NIPS 2017 โปสเตอร์ ---- NIPS 2017 Spotlight Slides ---- บล็อกโพสต์
โดย Antti Tarvainen, Harri Valpola (บริษัท AI ที่อยากรู้อยากเห็น)
เข้าใกล้
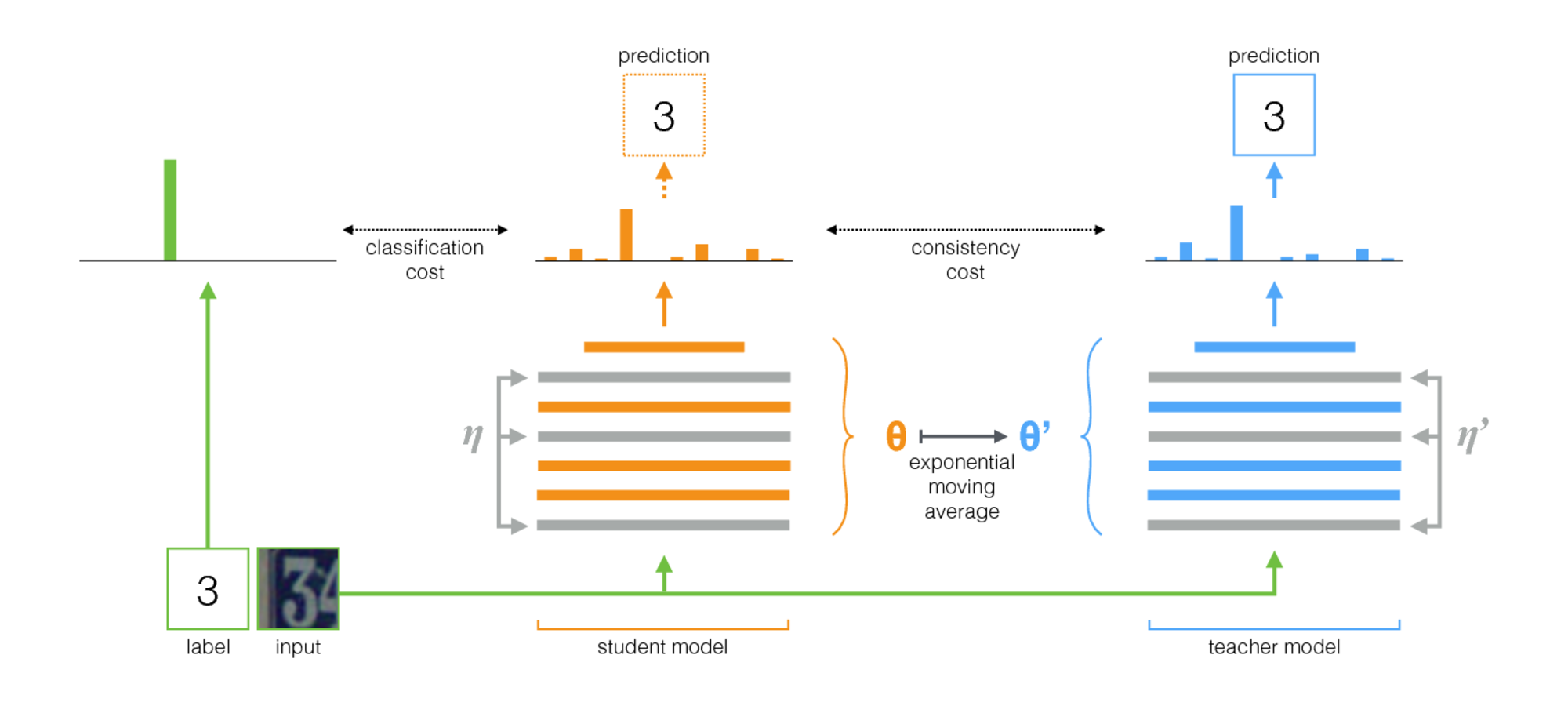
ค่าเฉลี่ยครูเป็นวิธีง่ายๆสำหรับการเรียนรู้แบบกึ่งผู้ดูแล ประกอบด้วยขั้นตอนต่อไปนี้:
- ใช้สถาปัตยกรรมภายใต้การดูแลและทำสำเนา เรียกรุ่นดั้งเดิมของ นักเรียน และเป็น ครู ใหม่
- ในแต่ละขั้นตอนการฝึกอบรมให้ใช้ minibatch เดียวกับอินพุตของทั้งนักเรียนและครู แต่เพิ่มการเพิ่มการสุ่มหรือเสียงรบกวนลงในอินพุตแยกต่างหาก
- เพิ่ม ค่าใช้จ่ายที่สอดคล้องกัน เพิ่มเติมระหว่างนักเรียนและผลงานของครู (หลังจาก Softmax)
- ให้เครื่องมือเพิ่มประสิทธิภาพอัปเดตน้ำหนักของนักเรียนตามปกติ
- ให้น้ำหนักครูเป็นค่าเฉลี่ยเคลื่อนที่แบบเอ็กซ์โปเนนเชียล (EMA) ของน้ำหนักนักเรียน นั่นคือหลังจากแต่ละขั้นตอนการฝึกอบรมอัปเดตน้ำหนักครูเล็กน้อยไปยังน้ำหนักของนักเรียน
ผลงานของเราคือขั้นตอนสุดท้าย Laine และ Aila [Paper] ใช้พารามิเตอร์ที่ใช้ร่วมกันระหว่างนักเรียนและครูหรือใช้ชุดการทำนายครูชั่วคราว ในการเปรียบเทียบค่าเฉลี่ยของครูมีความแม่นยำมากขึ้นและใช้ได้กับชุดข้อมูลขนาดใหญ่
ค่าเฉลี่ยของครูทำงานได้ดีกับสถาปัตยกรรมสมัยใหม่ เมื่อรวมค่าเฉลี่ยของครูกับ Resnets เราได้ปรับปรุงสถานะของศิลปะในการเรียนรู้แบบกึ่งผู้ดูแลในชุดข้อมูล Imagenet และ CIFAR-10
| ImageNet ใช้ 10% ของป้ายกำกับ | ข้อผิดพลาดการตรวจสอบความถูกต้องสูงสุด 5 อันดับ |
|---|
| Variational Auto-encoder [Paper] | 35.42 ± 0.90 |
| ค่าเฉลี่ยครู resnet-152 | 9.11 ± 0.12 |
| ฉลากทั้งหมดสถานะของศิลปะ [กระดาษ] | 3.79 |
| CIFAR-10 ใช้ป้ายกำกับ 4000 ป้าย | ข้อผิดพลาดทดสอบ |
|---|
| ct-gan [กระดาษ] | 9.98 ± 0.21 |
| ค่าเฉลี่ยครู resnet-26 | 6.28 ± 0.15 |
| ฉลากทั้งหมดสถานะของศิลปะ [กระดาษ] | 2.86 |
การดำเนินการ
มีการใช้งานสองครั้งหนึ่งรายการสำหรับ TensorFlow และอีกอันสำหรับ Pytorch รุ่น Pytorch น่าจะง่ายต่อการปรับให้เข้ากับความต้องการของคุณเนื่องจากเป็นไปตามสำนวน pytorch ทั่วไปและมีสถานที่ที่เป็นธรรมชาติในการเพิ่มโมเดลและชุดข้อมูลของคุณ แจ้งให้เราทราบหากมีสิ่งใดต้องการชี้แจง
เกี่ยวกับผลลัพธ์ในกระดาษการทดลองที่ใช้สถาปัตยกรรม Convnet แบบดั้งเดิมนั้นทำงานด้วยรุ่น Tensorflow การทดลองที่ใช้เครือข่ายที่เหลือใช้งานกับรุ่น Pytorch
เคล็ดลับในการเลือกพารามิเตอร์และการปรับแต่งอื่น ๆ
ค่าเฉลี่ยครูแนะนำ hyperparameters ใหม่สอง: อัตราการสลายตัวของ EMA และน้ำหนักต้นทุนที่สอดคล้องกัน ค่าที่เหมาะสมที่สุดสำหรับแต่ละสิ่งเหล่านี้ขึ้นอยู่กับชุดข้อมูลโมเดลและองค์ประกอบของ minibatches คุณจะต้องเลือกวิธีการแทรกตัวอย่างที่ไม่มีป้ายกำกับและตัวอย่างที่ติดฉลากใน minibatches
นี่คือกฎบางอย่างของนิ้วหัวแม่มือที่จะเริ่มต้น:
- หากคุณกำลังทำงานในชุดข้อมูลใหม่อาจเป็นเรื่องง่ายที่สุดในการเริ่มต้นด้วยข้อมูลที่มีป้ายกำกับเท่านั้นและทำการฝึกอบรมที่มีการดูแลอย่างบริสุทธิ์ จากนั้นเมื่อคุณมีความสุขกับสถาปัตยกรรมและพารามิเตอร์ไฮเปอร์พารามิเตอร์ให้เพิ่มค่าเฉลี่ยของครู เครือข่ายเดียวกันควรทำงานได้ดีแม้ว่าคุณอาจต้องการปรับแต่งการทำให้เป็นมาตรฐานเช่นการสลายตัวของน้ำหนักที่คุณใช้กับข้อมูลขนาดเล็ก
- ค่าเฉลี่ยของครูต้องการเสียงรบกวนในแบบจำลองเพื่อทำงานอย่างเหมาะสม ในทางปฏิบัติเสียงที่ดีที่สุดอาจเป็นการเพิ่มอินพุตแบบสุ่ม ใช้การเสริมใด ๆ ที่เกี่ยวข้องที่คุณคิดได้: อัลกอริทึมจะฝึกอบรมแบบจำลองให้ไม่เปลี่ยนแปลง
- มันมีประโยชน์ในการอุทิศส่วนหนึ่งของมินทัชแต่ละตัวสำหรับตัวอย่างที่มีป้ายกำกับ จากนั้นสัญญาณการฝึกอบรมภายใต้การดูแลนั้นแข็งแกร่งพอที่จะฝึกได้อย่างรวดเร็วและป้องกันไม่ให้ติดอยู่ในความไม่แน่นอน ในตัวอย่าง pytorch เรามีหนึ่งในสี่หรือครึ่งหนึ่งของ minibatch สำหรับตัวอย่างที่มีป้ายกำกับและส่วนที่เหลือสำหรับไม่มีป้ายกำกับ (ดู twostreambatchsampler ในรหัส pytorch)
- สำหรับอัตราการสลายตัวของ EMA 0.999 ดูเหมือนจะเป็นจุดเริ่มต้นที่ดี
- คุณสามารถใช้ MSE หรือ KL-Divergence เป็นฟังก์ชั่นต้นทุนความสอดคล้อง สำหรับ KL-Divergence น้ำหนักต้นทุนความสอดคล้องที่ดีมักจะอยู่ระหว่าง 1.0 ถึง 10.0 สำหรับ MSE ดูเหมือนว่าจะอยู่ระหว่างจำนวนคลาสและจำนวนคลาสที่ยกกำลังสอง ในชุดข้อมูลขนาดเล็กเราเห็น MSE ได้ผลลัพธ์ที่ดีกว่า แต่ KL ก็ทำงานได้ดีเช่นกัน
- มันอาจช่วยเพิ่มค่าใช้จ่ายที่สม่ำเสมอในการเริ่มต้นในช่วงสองสามครั้งแรกจนกระทั่งเครือข่ายครูเริ่มให้การคาดการณ์ที่ดี
- เคล็ดลับเพิ่มเติมที่เราใช้ในตัวอย่าง pytorch: มีสองเลเยอร์ logit แยกกันสองชั้นที่ระดับบนสุด ใช้หนึ่งสำหรับการจำแนกประเภทของตัวอย่างที่ติดฉลากและอีกหนึ่งสำหรับการทำนายผลลัพธ์ของครู จากนั้นมีค่าใช้จ่ายเพิ่มเติมระหว่างการบันทึกของการคาดการณ์ทั้งสองนี้ ความตั้งใจนั้นเหมือนกับค่าใช้จ่ายที่สม่ำเสมอ: ในการเริ่มต้นเอาท์พุทของครูอาจผิดดังนั้นคลายการเชื่อมโยงระหว่างการทำนายการจำแนกประเภทและค่าใช้จ่ายที่สอดคล้องกัน (ดูอาร์กิวเมนต์-logit-distance-cost ในการใช้งาน Pytorch)


