Mean Lehrer sind bessere Vorbilder
Papier ---- NIPS 2017 Poster ---- NIPS 2017 Spotlight-Folien ---- Blogbeitrag
Von Antti Tarvainen, Harri Valpola (der neugierigen AI -Firma)
Ansatz
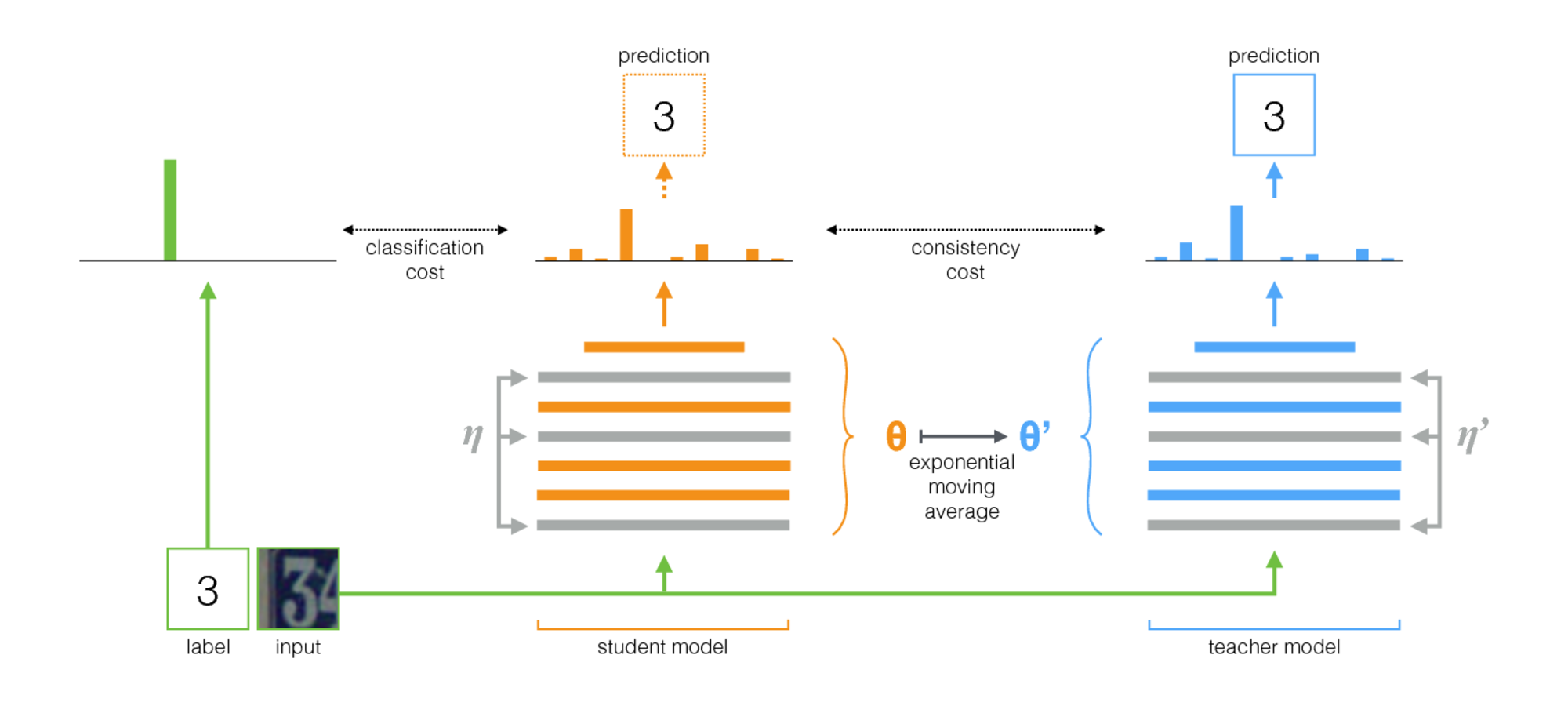
Der mittlere Lehrer ist eine einfache Methode für das halbübergreifende Lernen. Es besteht aus den folgenden Schritten:
- Nehmen Sie eine überwachte Architektur und machen Sie eine Kopie daraus. Nennen wir das Originalmodell den Schüler und das neue den Lehrer .
- Verwenden Sie bei jedem Trainingsschritt dieselbe Minibatch wie Eingaben sowohl für den Schüler als auch für den Lehrer, fügen Sie den Eingaben jedoch zufällige Augmentation oder Rauschen hinzu.
- Fügen Sie eine zusätzliche Konsistenzkosten zwischen den Ausgaben des Schülers und der Lehrer hinzu (nach Softmax).
- Lassen Sie den Optimierer die Schülergewichte normal aktualisieren.
- Lassen Sie die Lehrergewichte ein exponentieller gleitender Durchschnitt (EMA) der Schülergewichte sein. Nach jedem Trainingsschritt aktualisieren Sie die Lehrergewichte ein wenig in Richtung der Schülergewichte.
Unser Beitrag ist der letzte Schritt. Laine und Aila [Papier] verwendeten gemeinsame Parameter zwischen dem Schüler und dem Lehrer oder ein zeitliches Ensemble von Lehrervorhersagen. Im Vergleich dazu ist der mittlere Lehrer genauer und für große Datensätze genauer anwendbar.
Der mittlere Lehrer funktioniert gut mit modernen Architekturen. Durch die Kombination von mittlerem Lehrer mit ResNETs haben wir den Stand der Technik im halbübergreifenden Lernen auf den Datasets im Bildnetz und Cifar-10 verbessert.
| ImagNet mit 10% der Etiketten | Top-5-Validierungsfehler |
|---|
| Variational Auto-Ccoder [Papier] | 35,42 ± 0,90 |
| Mean Teacher Resnet-152 | 9,11 ± 0,12 |
| Alle Etiketten, Stand der Technik [Papier] | 3.79 |
| CIFAR-10 mit 4000 Etiketten | Testfehler |
|---|
| CT-GAN [Papier] | 9,98 ± 0,21 |
| Mean Teacher Resnet-26 | 6,28 ± 0,15 |
| Alle Etiketten, Stand der Technik [Papier] | 2.86 |
Durchführung
Es gibt zwei Implementierungen, eine für TensorFlow und eine für Pytorch. Die Pytorch -Version ist wahrscheinlich einfacher an Ihre Anforderungen anpassen, da sie typische Pytorch -Redewendungen folgt, und es gibt einen natürlichen Ort, an dem Sie Ihr Modell und Ihr Datensatz hinzufügen können. Lassen Sie mich wissen, ob etwas Klarstellung erforderlich ist.
In Bezug auf die Ergebnisse des Papiers wurden die Experimente mit einer herkömmlichen Konzernarchitektur mit der TensorFlow -Version durchgeführt. Die Experimente mit Restnetzwerken wurden mit der Pytorch -Version durchgeführt.
Tipps zur Auswahl von Hyperparametern und anderen Stimmen
Der mittlere Lehrer führt zwei neue Hyperparameter ein: EMA -Zerfallsrate und Konsistenzkostengewicht. Der optimale Wert für jeden von diesen hängt vom Datensatz, dem Modell und der Zusammensetzung der Minibatches ab. Sie müssen auch auswählen, wie Sie nicht markierte Proben und markierte Proben in Minibatches verschieben.
Hier sind einige Faustregeln, um Ihnen den Einstieg zu erleichtern:
- Wenn Sie an einem neuen Datensatz arbeiten, ist es möglicherweise am einfachsten, nur mit gekennzeichneten Daten zu beginnen und ein reines, überwachtes Training durchzuführen. Wenn Sie dann mit der Architektur und den Hyperparametern zufrieden sind, fügen Sie den mittleren Lehrer hinzu. Das gleiche Netzwerk sollte gut funktionieren, obwohl Sie möglicherweise die Regularisierung einstellen möchten, z. B. Gewichtsverfall, die Sie mit kleinen Daten verwendet haben.
- Der mittlere Lehrer braucht etwas Lärm im Modell, um optimal zu arbeiten. In der Praxis sind das beste Rauschen wahrscheinlich zufällige Eingangsvergrößerungen. Verwenden Sie alle relevanten Augmentationen, an die Sie sich vorstellen können: Der Algorithmus trainiert das Modell, um für sie unveränderlich zu sein.
- Es ist nützlich, einen Teil jeder Minibatch für beschriftete Beispiele zu widmen. Dann ist das überwachte Trainingssignal früh genug, um schnell zu trainieren und zu verhindern, dass sie in Unsicherheit stecken. In den Pytorch -Beispielen haben wir ein oder eine Hälfte der Minibatch für die markierten Beispiele und den Rest für die Unbezeichneten. (Siehe TwostreamBatchSampler im Pytorch -Code.)
- Für die EMA -Zerfallsrate scheint 0,999 ein guter Ausgangspunkt zu sein.
- Sie können entweder MSE oder KL-Divergenz als Konsistenzkostenfunktion verwenden. Für die KL-Divergenz liegt ein guter Konsistenzkostengewicht häufig zwischen 1,0 und 10,0. Für MSE scheint es zwischen der Anzahl der Klassen und der Anzahl der quadratischen Klassen zu liegen. Bei kleinen Datensätzen haben wir gesehen, wie MSE bessere Ergebnisse erzielte, aber KL hat auch immer ziemlich gut funktioniert.
- Es kann helfen, die Konsistenzkosten am Anfang in den ersten Epochen zu erhöhen, bis das Lehrernetzwerk gute Vorhersagen abgibt.
- Ein zusätzlicher Trick, den wir in den Pytorch -Beispielen verwendet haben: haben zwei separate Logit -Schichten auf der oberen Ebene. Verwenden Sie eine zur Klassifizierung markierter Beispiele und eine zur Vorhersage der Lehrerausgabe. Und haben dann zusätzliche Kosten zwischen den Protokollen dieser beiden Vorhersagen. Die Absicht ist die gleiche wie bei der Konsistenzkostenrampup: Am Anfang kann die Lehrerausgabe falsch sein. Lösen Sie also den Zusammenhang zwischen der Klassifizierungsvorhersage und den Konsistenzkosten. (Siehe das Argument für-Logit-Distanz-Kosten in der Pytorch-Implementierung.)


