Les enseignants moyens sont de meilleurs modèles
Paper ---- Poster Nips 2017 ---- Nips 2017 Spotlight Diapositives ---- Article de blog
Par Antti Tarvainen, Harri Valpola (The Curious AI Company)
Approche
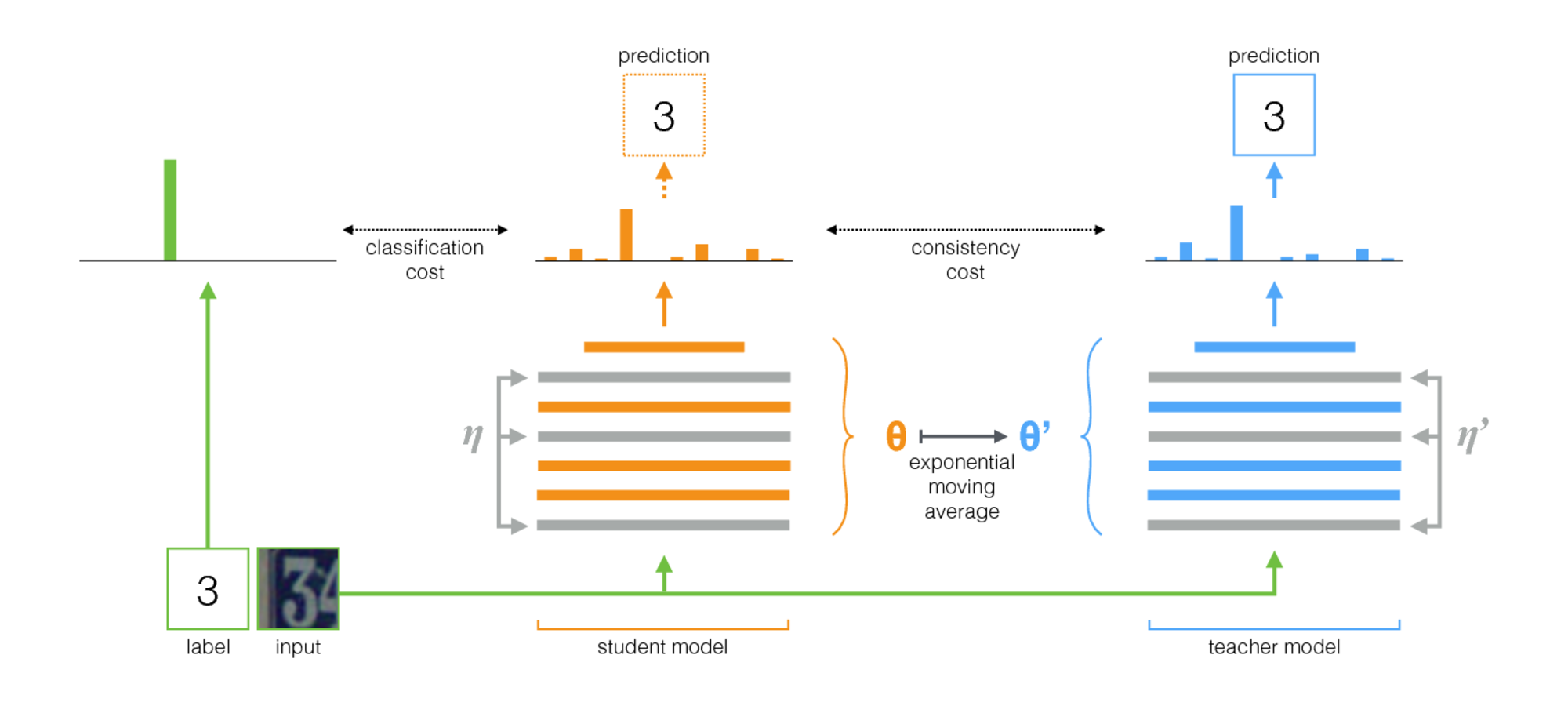
L'enseignant moyen est une méthode simple pour l'apprentissage semi-supervisé. Il se compose des étapes suivantes:
- Prenez une architecture supervisée et faites-en une copie. Appelons le modèle d'origine l' élève et le nouveau l' enseignant .
- À chaque étape de formation, utilisez le même minibatch que les entrées à la fois à l'élève et à l'enseignant, mais ajoutez une augmentation ou un bruit aléatoire aux entrées séparément.
- Ajoutez un coût de cohérence supplémentaire entre l'élève et les sorties de l'enseignant (après Softmax).
- Laissez l'optimiseur mettre à jour les poids des élèves normalement.
- Que le poids des enseignants soit une moyenne mobile exponentielle (EMA) des poids des élèves. Autrement dit, après chaque étape de formation, mettre à jour les poids des enseignants un peu vers les poids des élèves.
Notre contribution est la dernière étape. Laine et Aila [papier] ont utilisé des paramètres partagés entre l'élève et l'enseignant, ou ont utilisé un ensemble temporel de prédictions de l'enseignant. En comparaison, l'enseignant moyen est plus précis et applicable aux grands ensembles de données.
L'enseignant moyen travaille bien avec les architectures modernes. En combinant un enseignant moyen avec des réseaux, nous avons amélioré l'état de l'art dans l'apprentissage semi-supervisé sur les ensembles de données ImageNet et CIFAR-10.
| ImageNet utilisant 10% des étiquettes | Erreur de validation du top 5 |
|---|
| Encodeur automatique variationnel [papier] | 35,42 ± 0,90 |
| Enseignant moyen Resnet-152 | 9.11 ± 0,12 |
| Tous les étiquettes, ultimes de l'art [papier] | 3.79 |
| CIFAR-10 en utilisant 4000 étiquettes | Erreur de test |
|---|
| Ct-gan [papier] | 9,98 ± 0,21 |
| Enseignant moyen Resnet-26 | 6,28 ± 0,15 |
| Tous les étiquettes, ultimes de l'art [papier] | 2.86 |
Mise en œuvre
Il y a deux implémentations, une pour TensorFlow et une pour Pytorch. La version Pytorch est probablement plus facile à adapter à vos besoins, car il suit les idioms typiques de pytorch, et il y a un endroit naturel pour ajouter votre modèle et votre ensemble de données. Faites-moi savoir si quelque chose a besoin de clarification.
En ce qui concerne les résultats de l'article, les expériences utilisant une architecture ConvNet traditionnelle ont été exécutées avec la version TensorFlow. Les expériences utilisant des réseaux résiduelles ont été exécutées avec la version Pytorch.
Conseils pour choisir des hyperparamètres et d'autres réglages
L'enseignant moyen introduit deux nouveaux hyperparamètres: le taux de désintégration EMA et le poids des coûts de cohérence. La valeur optimale pour chacun d'elles dépend de l'ensemble de données, du modèle et de la composition des minibatchs. Vous devrez également choisir comment entrelacer des échantillons non marqués et des échantillons étiquetés dans des minibatchs.
Voici quelques règles de base pour vous aider à démarrer:
- Si vous travaillez sur un nouvel ensemble de données, il peut être plus facile de commencer avec uniquement des données étiquetées et de faire une formation supervisée pure. Ensuite, lorsque vous êtes satisfait de l'architecture et des hyperparamètres, ajoutez un enseignant moyen. Le même réseau doit bien fonctionner, bien que vous souhaitiez peut-être régler la régularisation telle que la décroissance de poids que vous avez utilisée avec de petites données.
- L'enseignant moyen a besoin d'un peu de bruit dans le modèle pour travailler de manière optimale. En pratique, le meilleur bruit est probablement des augmentations d'entrée aléatoires. Utilisez les augmentations pertinentes auxquelles vous pouvez penser: l'algorithme entraînera le modèle à leur invariant.
- Il est utile de consacrer une partie de chaque minibatch pour les exemples étiquetés. Ensuite, le signal d'entraînement supervisé est suffisamment fort au début pour s'entraîner rapidement et empêcher de se retrouver dans l'incertitude. Dans les exemples de Pytorch, nous avons un quart ou demi du minibatch pour les exemples marqués et le reste pour les non étiquetés. (Voir TwoStreamBatchSampler dans le code Pytorch.)
- Pour le taux de désintégration EMA, 0,999 semble être un bon point de départ.
- Vous pouvez utiliser MSE ou KL-Divergence comme fonction de coût de cohérence. Pour la divergence de KL, un bon poids de coût de cohérence se situe souvent entre 1,0 et 10,0. Pour MSE, cela semble être entre le nombre de classes et le nombre de classes au carré. Sur les petits ensembles de données, nous avons vu MSE obtenir de meilleurs résultats, mais KL a toujours bien fonctionné aussi bien.
- Cela peut aider à augmenter le coût de cohérence au début des premières époques jusqu'à ce que le réseau des enseignants commence à donner de bonnes prévisions.
- Une astuce supplémentaire que nous avons utilisée dans les exemples de Pytorch: ont deux couches logit séparées au niveau supérieur. Utilisez-en un pour la classification des exemples étiquetés et un pour prédire la sortie de l'enseignant. Puis avoir un coût supplémentaire entre les logits de ces deux prédictions. L'intention est la même que pour le rampup des coûts de cohérence: au début, la sortie de l'enseignant peut être erronée, donc desserrer le lien entre la prédiction de classification et le coût de cohérence. (Voir l'argument de -ogit-distance-coût dans l'implémentation de Pytorch.)


