Os professores médios são melhores modelos
Paper ---- Nips 2017 Pôster ---- NIPS 2017 Slides Spotlight ---- Postagem do blog
Por Antti Tarvainen, Harri Valpola (a curiosa empresa de IA)
Abordagem
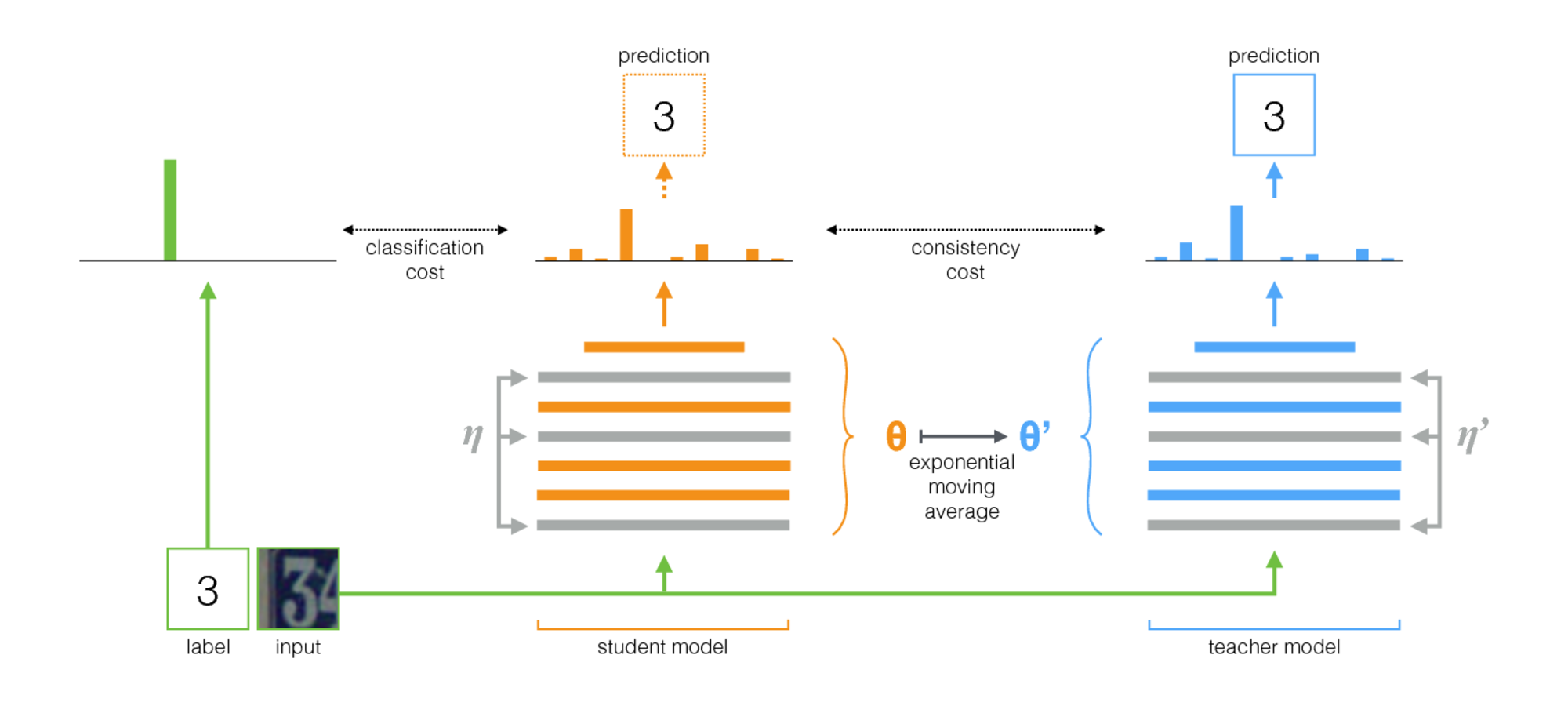
O professor médio é um método simples para o aprendizado semi-supervisionado. Consiste nas seguintes etapas:
- Pegue uma arquitetura supervisionada e faça uma cópia dela. Vamos chamar o modelo original de aluno e o novo professor .
- Em cada etapa de treinamento, use o mesmo minibatch que as entradas para o aluno e o professor, mas adicione aumento aleatório ou ruído às entradas separadamente.
- Adicione um custo de consistência adicional entre as saídas do aluno e do professor (após o softmax).
- Deixe o otimizador atualizar os pesos do aluno normalmente.
- Deixe os pesos do professor ser uma média móvel exponencial (EMA) dos pesos dos alunos. Ou seja, após cada etapa de treinamento, atualize o professor um pouco para os pesos dos alunos.
Nossa contribuição é o último passo. Laine e Aila [artigo] usaram parâmetros compartilhados entre o aluno e o professor, ou usaram um conjunto temporal de previsões de professores. Em comparação, o professor médio é mais preciso e aplicável a grandes conjuntos de dados.
O professor médio funciona bem com arquiteturas modernas. Combinando o professor médio com as Resnets, melhoramos o estado da arte em aprendizado semi-supervisionado nos conjuntos de dados ImageNet e CIFAR-10.
| Imagenet usando 10% dos rótulos | Top-5 Erro de validação |
|---|
| Oncoder automático variacional [papel] | 35,42 ± 0,90 |
| Professor médio Resnet-152 | 9,11 ± 0,12 |
| Todos os rótulos, estado da arte [artigo] | 3.79 |
| CIFAR-10 usando 4000 rótulos | erro de teste |
|---|
| CT-Gan [Papel] | 9,98 ± 0,21 |
| Professor médio Resnet-26 | 6,28 ± 0,15 |
| Todos os rótulos, estado da arte [artigo] | 2.86 |
Implementação
Existem duas implementações, uma para Tensorflow e outra para Pytorch. A versão Pytorch é provavelmente mais fácil de se adaptar às suas necessidades, pois segue idiomas típicos de Pytorch e há um local natural para adicionar seu modelo e conjunto de dados. Deixe -me saber se alguma coisa precisa de esclarecimentos.
Em relação aos resultados no artigo, os experimentos usando uma arquitetura tradicional Convnet foram executados com a versão Tensorflow. As experiências usando redes residuais foram executadas com a versão Pytorch.
Dicas para escolher hiperparâmetros e outros ajustes
O professor médio apresenta dois novos hiperparâmetros: taxa de decaimento da EMA e peso de custo de consistência. O valor ideal para cada um deles depende do conjunto de dados, do modelo e da composição dos minibatches. Você também precisará escolher como intercalar amostras não marcadas e amostras marcadas em minibatches.
Aqui estão algumas regras práticas para você começar:
- Se você estiver trabalhando em um novo conjunto de dados, pode ser mais fácil começar apenas com dados rotulados e fazer treinamento supervisionado puro. Então, quando você estiver feliz com a arquitetura e os hiperparâmetros, adicione o professor mal -humorado. A mesma rede deve funcionar bem, embora você queira ajustar a regularização, como a decaimento do peso que você usou com pequenos dados.
- O professor médio precisa de algum ruído no modelo para funcionar de maneira ideal. Na prática, o melhor ruído é provavelmente os aumentos aleatórios de entrada. Use quaisquer aumentos relevantes que você possa imaginar: o algoritmo treinará o modelo para ser invariante para eles.
- É útil dedicar uma parte de cada minibatch para exemplos rotulados. Em seguida, o sinal de treinamento supervisionado é forte o suficiente para treinar rapidamente e evitar ficar preso à incerteza. Nos exemplos de Pytorch, temos um quarto ou meio do minibatch para os exemplos rotulados e o restante para os não marcados. (Consulte TwosTreambatchSampler no código Pytorch.)
- Para a taxa de decaimento da EMA, 0,999 parece ser um bom ponto de partida.
- Você pode usar o MSE ou a Divergência KL como a função de custo de consistência. Para a distúrbio de KL, um bom peso de custo de consistência geralmente está entre 1,0 e 10,0. Para o MSE, parece estar entre o número de classes e o número de classes quadradas. Em pequenos conjuntos de dados, vimos MSE obter melhores resultados, mas a KL sempre funcionou muito bem também.
- Pode ajudar a aumentar o custo de consistência no início nas primeiras épocas até que a rede de professores comece a fornecer boas previsões.
- Um truque adicional que usamos nos exemplos de Pytorch: tenha duas camadas de logit separadas no nível superior. Use um para classificação de exemplos rotulados e outro para prever a produção do professor. E depois tenha um custo adicional entre as logits dessas duas previsões. A intenção é a mesma que com o aumento de custo de consistência: no início, a produção do professor pode estar errada, portanto, afrouxe o link entre a previsão de classificação e o custo de consistência. (Veja o argumento--Logit-Distância em Pytorch Implementation.)


