يعني المعلمون قدوة أفضل
Paper ---- NIPS 2017 Poster ---- Nips 2017 Spotlight Slides ---- Post Post
بقلم Antti Tarvainen ، Harri Valpola (The Curious AI Company)
يقترب
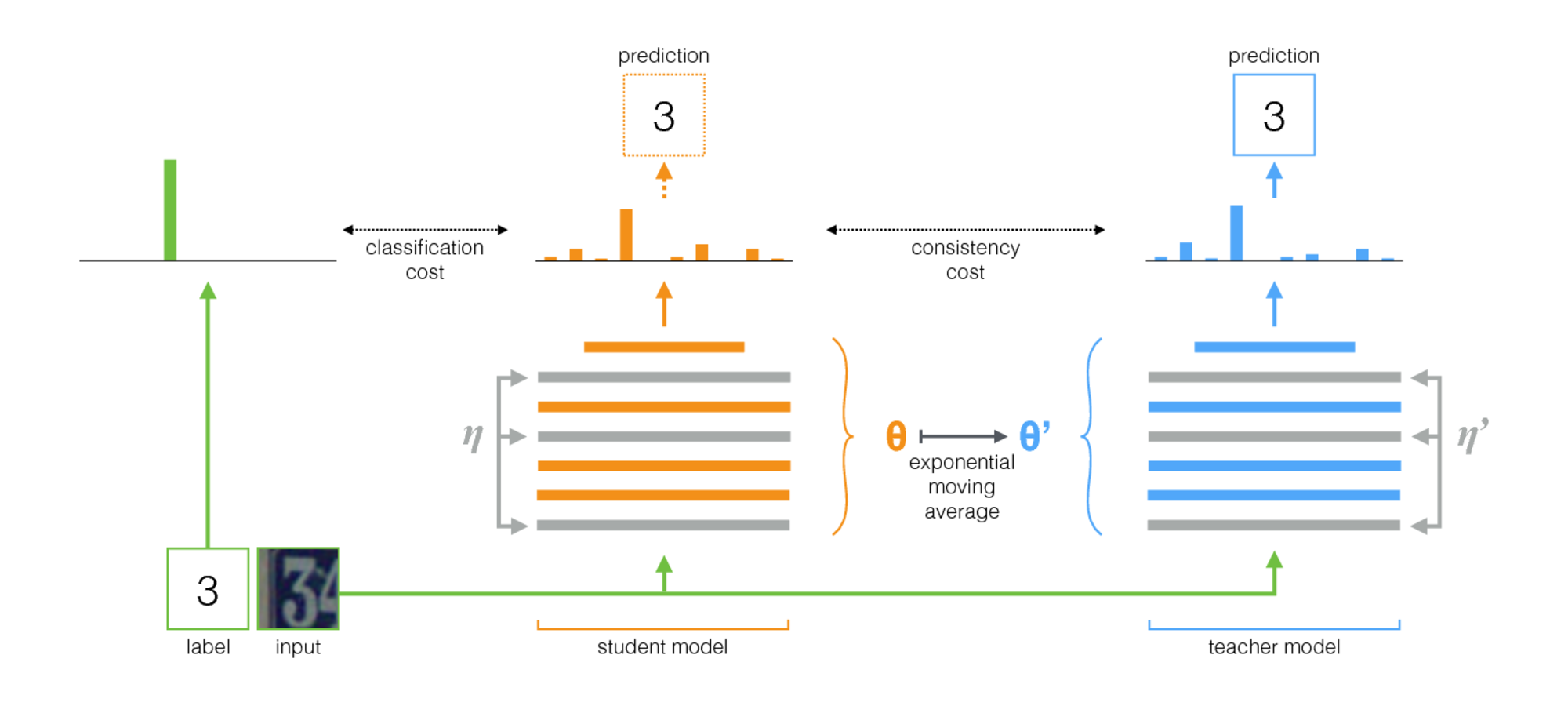
يعني المعلم طريقة بسيطة للتعلم شبه الخاضع للإشراف. يتكون من الخطوات التالية:
- خذ بنية خاضعة للإشراف وقم بنسخة من ذلك. دعنا نسمي النموذج الأصلي الطالب والمعلم الجديد.
- في كل خطوة تدريب ، استخدم نفس الحصرة مثل المدخلات لكل من الطالب والمعلم ولكن أضف زيادة عشوائية أو ضوضاء إلى المدخلات بشكل منفصل.
- أضف تكلفة اتساق إضافية بين مخرجات الطالب والمدرس (بعد SoftMax).
- دع المحسن يقوم بتحديث أوزان الطالب بشكل طبيعي.
- دع أوزان المعلم تكون متوسطًا متحركًا أسيًا (EMA) لأوزان الطالب. وهذا هو ، بعد كل خطوة تدريب ، تحديث أوزان المعلم قليلاً نحو أوزان الطالب.
مساهمتنا هي الخطوة الأخيرة. استخدمت Laine و Aila [Paper] معلمات مشتركة بين الطالب والمعلم ، أو استخدموا مجموعة زمنية لتنبؤات المعلم. بالمقارنة ، فإن متوسط المعلم هو أكثر دقة وتطبيقًا على مجموعات البيانات الكبيرة.
يعني المعلم يعمل بشكل جيد مع البنى الحديثة. الجمع بين متوسط المعلم مع Resnets ، قمنا بتحسين أحدث ما في التعلم شبه الخاضع للإشراف على مجموعات بيانات ImageNet و CIFAR-10.
| ImageNet باستخدام 10 ٪ من الملصقات | خطأ في التحقق من صحة أعلى 5 |
|---|
| المشفر التلقائي المتغير [ورقة] | 35.42 ± 0.90 |
| يعني المعلم RESNET-152 | 9.11 ± 0.12 |
| جميع الملصقات ، على أحدث ورقة [ورقة] | 3.79 |
| CIFAR-10 باستخدام 4000 علامة | اختبار خطأ |
|---|
| CT-GAN [ورقة] | 9.98 ± 0.21 |
| يعني المعلم RESNET-26 | 6.28 ± 0.15 |
| جميع الملصقات ، على أحدث ورقة [ورقة] | 2.86 |
تطبيق
هناك نوعان من التطبيقات ، واحد لترنسورفورت وواحد ل Pytorch. من المحتمل أن يكون إصدار إصدار Pytorch أسهل في التكيف مع احتياجاتك ، لأنه يتبع تعبيرات Pytorch النموذجية ، وهناك مكان طبيعي لإضافة نموذجك ومجموعة البيانات. اسمحوا لي أن أعرف إذا كان أي شيء يحتاج إلى توضيح.
فيما يتعلق بالنتائج في الورقة ، تم تشغيل التجارب باستخدام بنية ConvNet التقليدية مع إصدار TensorFlow. تم تشغيل التجارب باستخدام الشبكات المتبقية مع إصدار Pytorch.
نصائح لاختيار فرط البرارمترات وغيرها من الضبط
متوسط المعلم يقدم اثنين من المقاييس الفرعية الجديدة: معدل تسوس EMA ووزن تكلفة الاتساق. تعتمد القيمة المثلى لكل من هذه على مجموعة البيانات ، والنموذج ، وتكوين minibatches. ستحتاج أيضًا إلى اختيار كيفية التواصل مع عينات غير مسموعة وعينات تحمل علامات في الحصارات.
فيما يلي بعض قواعد الإبهام لتبدأ:
- إذا كنت تعمل على مجموعة بيانات جديدة ، فقد يكون من الأسهل البدء بالبيانات المسمى فقط وتدريب خاضع للإشراف. ثم عندما تكون سعيدًا بالهندسة المعمارية ومقاطعات فرطمية ، أضف المعلم المتوسط. يجب أن تعمل الشبكة نفسها بشكل جيد ، على الرغم من أنك قد ترغب في ضبط التنظيم مثل تحلل الوزن الذي استخدمته مع البيانات الصغيرة.
- يعني المعلم يحتاج إلى بعض الضوضاء في النموذج للعمل على النحو الأمثل. في الممارسة العملية ، ربما يكون أفضل ضوضاء هو زيادة إدخال عشوائي. استخدم أي تعزيزات ذات صلة يمكنك التفكير فيها: ستقوم الخوارزمية بتدريب النموذج على أن تكون ثابتة لهم.
- من المفيد تخصيص جزء من كل مصغرة للأمثلة المسمى. ثم تكون إشارة التدريب الخاضعة للإشراف قوية بما يكفي في وقت مبكر للتدريب بسرعة ومنع التعثر في حالة عدم اليقين. في أمثلة Pytorch ، لدينا ربع أو نصف الحافلة الصغيرة للأمثلة المسمى والباقي من أجل غير المُعلّم. (انظر TwoStreamBatchSampler في رمز Pytorch.)
- بالنسبة لمعدل تسوس EMA 0.999 يبدو أنه نقطة انطلاق جيدة.
- يمكنك استخدام إما MSE أو KL Divergence كدالة تكلفة الاتساق. بالنسبة إلى Divergence KL ، غالبًا ما يكون وزن تكلفة الاتساق جيدًا بين 1.0 و 10.0. بالنسبة إلى MSE ، يبدو أنه بين عدد الفئات وعدد الفصول التربيعة. في مجموعات البيانات الصغيرة ، رأينا MSE يحصل على نتائج أفضل ، لكن KL عملت دائمًا بشكل جيد أيضًا.
- قد يساعد ذلك في زيادة تكلفة الاتساق في البداية خلال الحقبة القليلة الأولى حتى تبدأ شبكة المعلم في تقديم تنبؤات جيدة.
- خدعة إضافية استخدمناها في أمثلة Pytorch: امتلك طبقتان لوجيت منفصلة في المستوى العلوي. استخدم واحدة لتصنيف الأمثلة المسمى وواحد للتنبؤ بإخراج المعلم. ثم يكون لديك تكلفة إضافية بين سجلات هذين التنبؤين. القصد هو نفسه كما هو الحال مع تربية تكلفة الاتساق: في البداية قد يكون ناتج المعلم خاطئًا ، لذا قم بفك الارتباط بين التنبؤ بالتصنيف وتكلفة الاتساق. (انظر حجة -logit-Distance-Cost في تطبيق Pytorch.)


