平均的な教師はより良いロールモデルです
論文---- NIPS 2017ポスター---- NIPS 2017 Spotlight Slides ----ブログ投稿
Antti Tarvainen、Harri Valpola(好奇心AI会社)
アプローチ
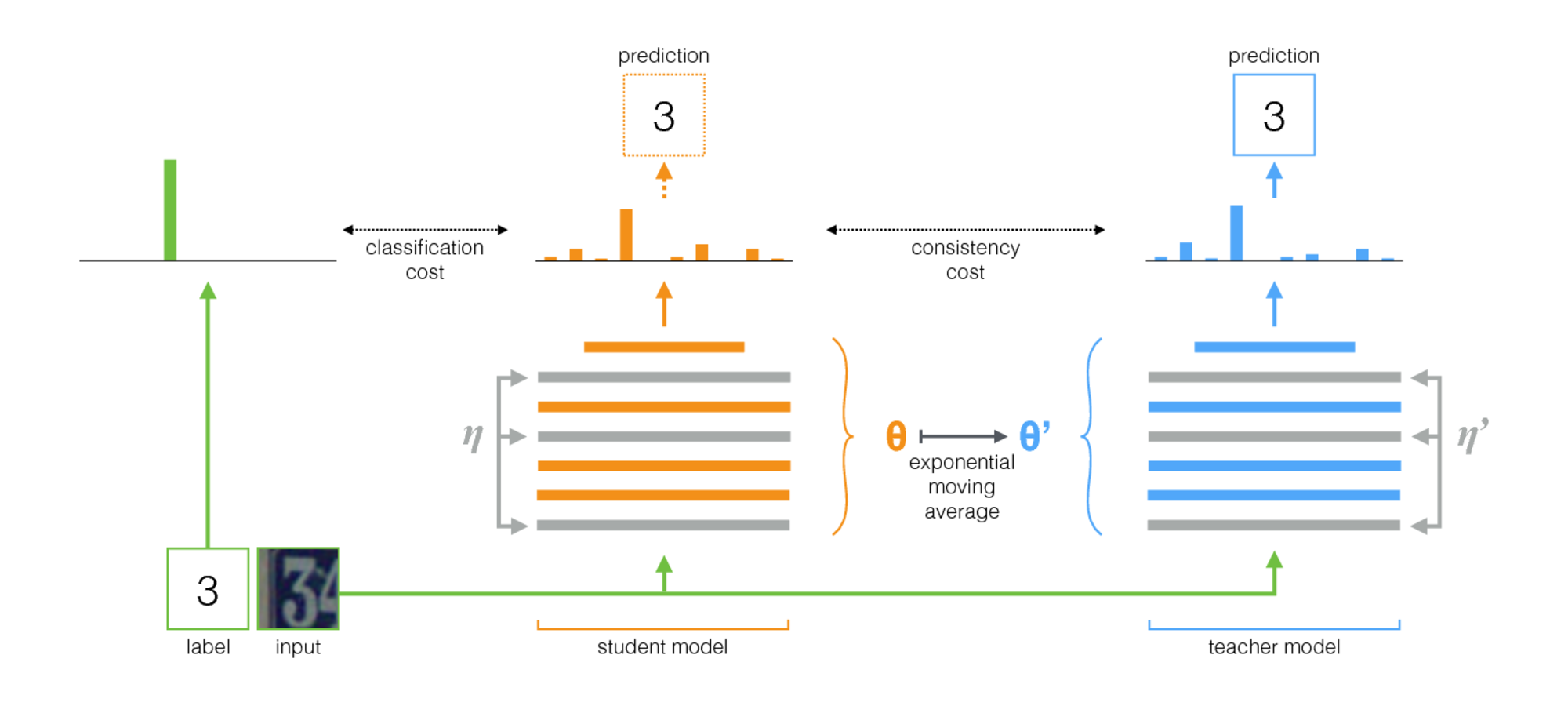
平均教師は、半教師の学習のための簡単な方法です。次の手順で構成されています。
- 監視されたアーキテクチャを取り、そのコピーを作成します。元のモデルを生徒と新しいモデルと呼びましょう。
- 各トレーニングステップで、生徒と教師の両方への入力と同じミニバッチを使用しますが、リンダムな増強またはノイズを個別に追加します。
- 生徒と教師の出力(SoftMaxの後)の間に追加の一貫性コストを追加します。
- Optimizerに、学生の重量を正常に更新させます。
- 教師の体重を、生徒の体重の指数移動平均(EMA)とします。つまり、各トレーニングステップの後、教師の体重を生徒の体重に少し更新します。
私たちの貢献は最後のステップです。 LaineとAila [Paper]は、生徒と教師の間で共有パラメーターを使用するか、教師の予測の一時的なアンサンブルを使用しました。それに比べて、平均教師はより正確であり、大規模なデータセットに適用できます。
平均教師は現代の建築にうまく機能します。平均教師と再ネットを組み合わせることで、ImagENetおよびCIFAR-10データセットの半監視学習の最先端を改善しました。
| ラベルの10%を使用したImagenet | トップ5検証エラー |
|---|
| Varional Auto-Encoder [Paper] | 35.42±0.90 |
| 平均教師Resnet-152 | 9.11±0.12 |
| すべてのラベル、最先端[紙] | 3.79 |
| 4000ラベルを使用したCIFAR-10 | テストエラー |
|---|
| ct-gan [紙] | 9.98±0.21 |
| 平均教師Resnet-26 | 6.28±0.15 |
| すべてのラベル、最先端[紙] | 2.86 |
実装
Tensorflow用の2つの実装とPytorch用の実装があります。 Pytorchバージョンは、典型的なPytorch Idiomsに従うため、おそらくニーズに適応する方が簡単で、モデルとデータセットを追加する自然な場所があります。何かが明確にする必要があるかどうか教えてください。
論文の結果に関して、従来のコンボネットアーキテクチャを使用した実験は、Tensorflowバージョンで実行されました。残差ネットワークを使用した実験は、Pytorchバージョンで実行されました。
ハイパーパラメーターやその他のチューニングを選択するためのヒント
平均教師は、EMA減衰率と一貫性コストの重量という2つの新しいハイパーパラメーターを導入します。これらのそれぞれの最適値は、データセット、モデル、およびミニバッチの構成によって異なります。また、マイニバッチでサンプルをラベル付けしたサンプルとラベル付けされたサンプルをインターリーする方法を選択する必要があります。
ここにあなたを始めるためのいくつかの経験則があります:
- 新しいデータセットに取り組んでいる場合、ラベル付きのデータのみで開始し、純粋な監視されたトレーニングを行うのが最も簡単かもしれません。次に、アーキテクチャとハイパーパラメーターに満足している場合は、平均教師を追加します。同じネットワークがうまく機能するはずですが、小さなデータで使用した重量減衰など、正規化を下げたい場合があります。
- 平均教師は、モデルのノイズが最適に動作する必要があります。実際には、最高のノイズはおそらくランダム入力の増強です。考えることができる関連する拡張を使用してください。アルゴリズムは、モデルに不変になるようにモデルを訓練します。
- ラベル付きの例には、各ミニバッチの一部を専用すると便利です。その後、監視されたトレーニング信号は、迅速にトレーニングし、不確実性に陥るのを防ぐために、早期に強くなります。 Pytorchの例では、ラベル付きの例のミニバッチの4分の1または半分があり、残りはラベル付けされていません。 (PytorchコードのTwoStreamBatchSamplerを参照してください。)
- EMA減衰率0.999の場合、良い出発点のようです。
- 一貫性コスト関数としてMSEまたはKL-Divergenceのいずれかを使用できます。 KL-Divergenceの場合、良好な一貫性コストの重量は、多くの場合1.0〜10.0の間です。 MSEの場合、クラスの数と2乗の数の間にあるようです。小さなデータセットでは、MSEがより良い結果を得ているのを見ましたが、KLも常にうまく機能しました。
- 教師ネットワークが良い予測を開始するまで、最初のいくつかのエポックで最初の一貫性コストを上げるのに役立つかもしれません。
- Pytorchの例で使用した追加のトリック:上位レベルに2つの個別のロジットレイヤーがあります。ラベルのある例の分類には、教師の出力を予測するために1つを使用します。そして、これら2つの予測のロジットの間に追加のコストがあります。意図は、一貫性コストのランプアップと同じです。最初は教師の出力が間違っている可能性があるため、分類予測と一貫性コストの間のリンクを緩めます。 (Pytorchの実装における-logit-distance-cost引数を参照してください。)


