Los maestros medio son mejores modelos a seguir
Paper ---- NIPS 2017 Póster ---- NIPS 2017 Spotlight Diapositivas ---- Publicación de blog
Por Antti Tarvainen, Harri Valpola (The Curious AI Company)
Acercarse
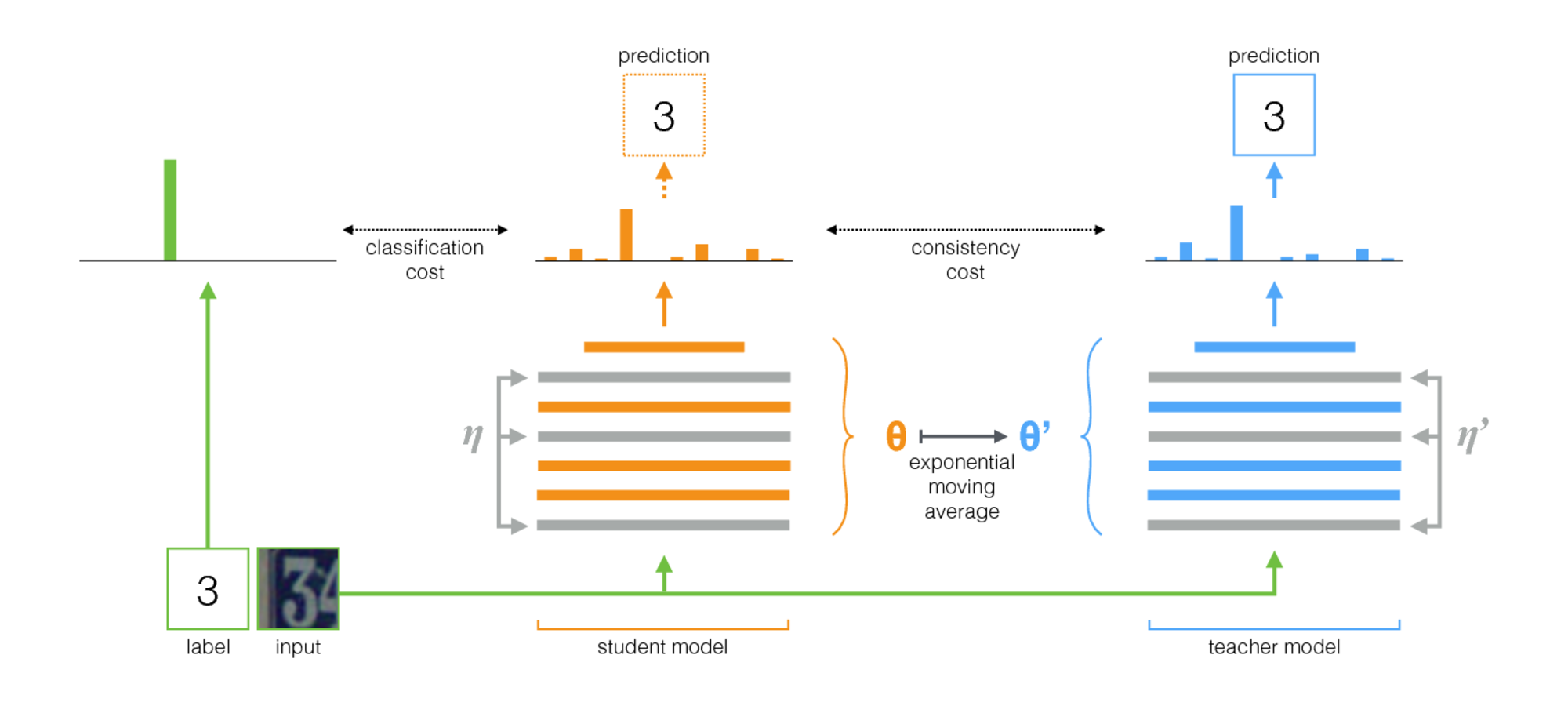
El maestro medio es un método simple para el aprendizaje semi-supervisado. Consiste en los siguientes pasos:
- Tome una arquitectura supervisada y haga una copia. Llamemos al modelo original al estudiante y al nuevo el maestro .
- En cada paso de entrenamiento, use la misma minibatch que las entradas tanto al alumno como al maestro, pero agregue un aumento aleatorio o ruido a las entradas por separado.
- Agregue un costo de consistencia adicional entre las salidas del alumno y el maestro (después de Softmax).
- Deje que el optimizador actualice las pesas de los estudiantes normalmente.
- Deje que los pesos del maestro sean un promedio móvil exponencial (EMA) de los pesos de los estudiantes. Es decir, después de cada paso de capacitación, actualice un poco los pesos del maestro para los pesos de los estudiantes.
Nuestra contribución es el último paso. Laine y Aila [documento] utilizaron parámetros compartidos entre el alumno y el maestro, o usaron un conjunto temporal de predicciones docentes. En comparación, el maestro medio es más preciso y aplicable a grandes conjuntos de datos.
El maestro medio trabaja bien con las arquitecturas modernas. Combinando el maestro medio con las resnets, mejoramos el estado del arte en el aprendizaje semi-supervisado en los conjuntos de datos ImageNet y CIFAR-10.
| Imagenet usando el 10% de las etiquetas | Error de validación de Top-5 |
|---|
| Variacional auto-codificador [documento] | 35.42 ± 0.90 |
| Medio maestro Resnet-152 | 9.11 ± 0.12 |
| Todas las etiquetas, estado del arte [papel] | 3.79 |
| Cifar-10 usando 4000 etiquetas | Error de prueba |
|---|
| CT-Gan [papel] | 9.98 ± 0.21 |
| Mani profesor resnet-26 | 6.28 ± 0.15 |
| Todas las etiquetas, estado del arte [papel] | 2.86 |
Implementación
Hay dos implementaciones, una para TensorFlow y otra para Pytorch. La versión de Pytorch probablemente sea más fácil de adaptar a sus necesidades, ya que sigue a los modismos típicos de Pytorch, y hay un lugar natural para agregar su modelo y conjunto de datos. Avíseme si algo necesita aclaración.
Con respecto a los resultados en el documento, los experimentos que utilizan una arquitectura de Convnet tradicional se ejecutaron con la versión TensorFlow. Los experimentos que usan redes residuales se ejecutaron con la versión Pytorch.
Consejos para elegir hiperparámetros y otros ajustes
El maestro medio presenta dos nuevos hiperparametros: la tasa de descomposición de EMA y el peso del costo de consistencia. El valor óptimo para cada uno de estos depende del conjunto de datos, el modelo y la composición de los minibatches. También deberá elegir cómo entrelazar muestras no etiquetadas y muestras etiquetadas en minibatches.
Aquí hay algunas reglas generales para comenzar:
- Si está trabajando en un nuevo conjunto de datos, puede ser más fácil comenzar con solo datos etiquetados y hacer una capacitación supervisada pura. Luego, cuando esté contento con la arquitectura y los hiperparámetros, agregue el maestro malo. La misma red debería funcionar bien, aunque es posible que desee ajustar la regularización, como la descomposición de peso que ha utilizado con datos pequeños.
- El maestro medio necesita algo de ruido en el modelo para funcionar de manera óptima. En la práctica, el mejor ruido son probablemente aumentos de entrada aleatorios. Use los aumentos relevantes que se le ocurra: el algoritmo capacitará al modelo para que sea invariante para ellos.
- Es útil dedicar una parte de cada minibatch para ejemplos etiquetados. Luego, la señal de entrenamiento supervisada es lo suficientemente fuerte desde el principio para entrenar rápidamente y evitar que se atasque en la incertidumbre. En los ejemplos de Pytorch tenemos una cuarta o media del minibatch para los ejemplos etiquetados y el resto para los no etiquetados. (Ver TwostreamBatchSampler en el código Pytorch.)
- Para la tasa de descomposición de EMA, 0.999 parece ser un buen punto de partida.
- Puede usar la divergencia MSE o KL como la función de costo de consistencia. Para la divergencia KL, un buen peso de costo de consistencia a menudo es entre 1.0 y 10.0. Para MSE, parece estar entre el número de clases y el número de clases al cuadrado. En pequeños conjuntos de datos vimos que MSE obtuvo mejores resultados, pero KL siempre funcionó bastante bien también.
- Puede ayudar a aumentar el costo de consistencia al principio sobre las primeras épocas hasta que la red de maestros comience a dar buenas predicciones.
- Un truco adicional que utilizamos en los ejemplos de Pytorch: tener dos capas logit separadas en el nivel superior. Use uno para la clasificación de ejemplos etiquetados y otro para predecir la producción del maestro. Y luego tiene un costo adicional entre los logits de estas dos predicciones. La intención es la misma que con el rampup de costos de consistencia: al principio, la producción del maestro puede ser incorrecta, por lo que afloje el vínculo entre la predicción de clasificación y el costo de consistencia. (Consulte el argumento-Logit-Distance-Cost en la implementación de Pytorch).


