Средние учителя - лучшие образцы для подражания
Бумага ---- NIPS 2017 Плакат ---- NIPS 2017 Spotlight Slides ---- Пост в блоге
Антти Тарвейнен, Харри Вэлпола (The Curious AI Company)
Подход
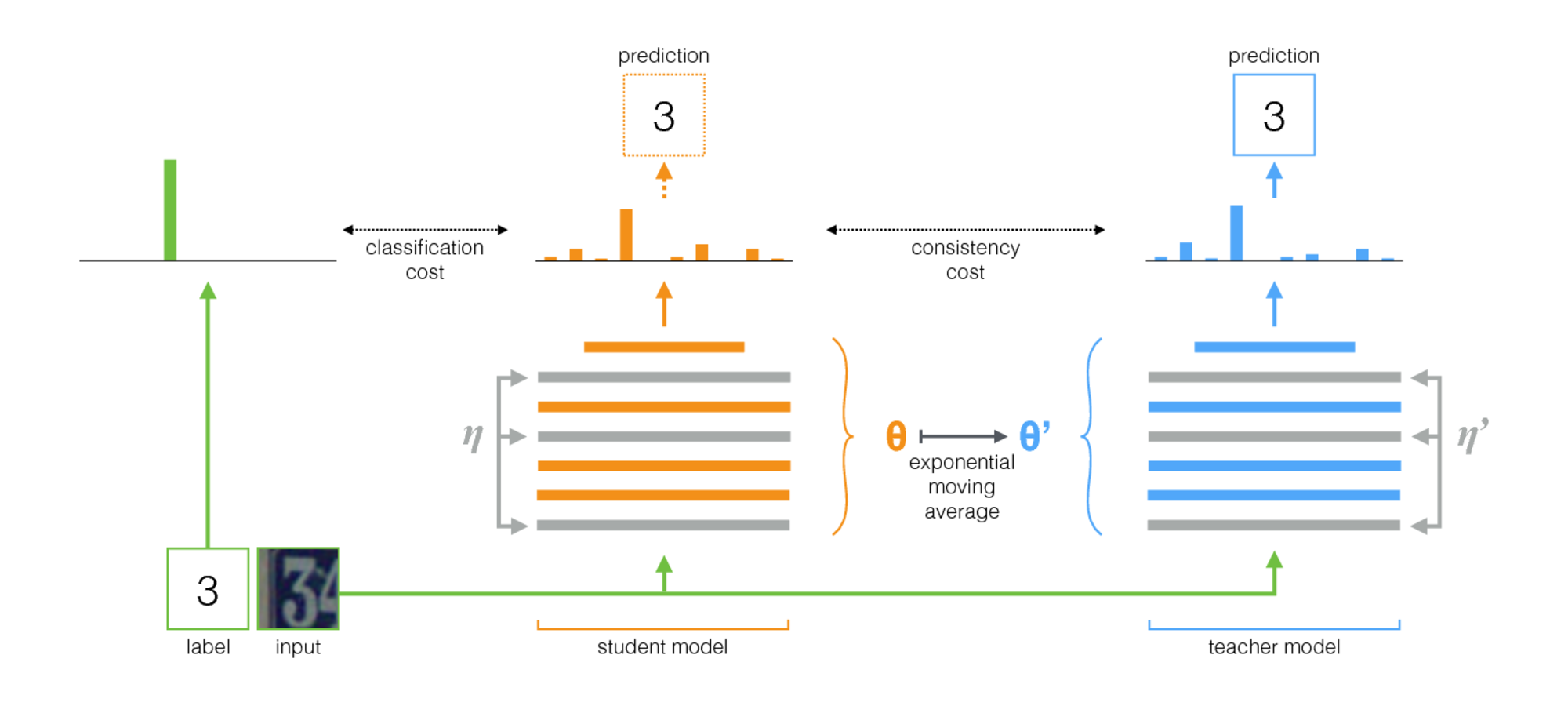
Средний учитель-это простой метод для полупрофильного обучения. Он состоит из следующих шагов:
- Возьмите контролируемую архитектуру и сделайте ее копию. Давайте назовем оригинальную модель учеником и новой учителем .
- На каждом этапе обучения используйте один и тот же Minibatch, что и входные данные как для ученика, так и для учителя, но добавьте случайное увеличение или шум к входам отдельно.
- Добавьте дополнительную стоимость согласованности между выходом ученика и учителя (после Softmax).
- Позвольте оптимизатору обновлять студента в весах нормально.
- Пусть учитель будет экспоненциальным скользящим средним (EMA) веса учеников. То есть после каждого этапа обучения обновляйте учителя немного весить в сторону весов ученика.
Наш вклад является последним шагом. Laine и Aila [Paper] использовали общие параметры между учеником и учителем или использовали временный ансамбль прогнозов учителей. Для сравнения, средний учитель более точен и применим к большим наборам данных.
Средний учитель хорошо работает с современными архитектурами. Комбинируя среднего учителя с Resnets, мы улучшили состояние искусства в полупрофильном обучении на наборах данных ImageNet и CiFAR-10.
| ImageNet с использованием 10% метков | Ошибка проверки TOP 5 |
|---|
| Вариационный автооходер [бумага] | 35,42 ± 0,90 |
| Средний учитель Resnet-152 | 9,11 ± 0,12 |
| Все этикетки, состояние искусства [бумага] | 3.79 |
| CIFAR-10 с использованием 4000 меток | ошибка тестирования |
|---|
| CT-Gan [Paper] | 9,98 ± 0,21 |
| Средний учитель Resnet-26 | 6,28 ± 0,15 |
| Все этикетки, состояние искусства [бумага] | 2.86 |
Выполнение
Есть две реализации, одна для Tensorflow и одна для Pytorch. Версия Pytorch, вероятно, легче адаптироваться к вашим потребностям, так как она следует за типичными идиомами Pytorch, и есть естественное место для добавления вашей модели и набора данных. Дайте мне знать, если что -то требует разъяснения.
Что касается результатов в статье, эксперименты с использованием традиционной архитектуры Convnet были запущены с версией TensorFlow. Эксперименты с использованием остаточных сетей были проведены с версией Pytorch.
Советы по выбору гиперпараметров и другой настройки
Среднее учитель вводит два новых гиперпараметров: частота распада и стоимость распада EMA и вес. Оптимальное значение для каждого из них зависит от набора данных, модели и состава Minibatches. Вам также необходимо будет выбрать, как переоценить немабоненные образцы и маркированные образцы в Minibatches.
Вот несколько правил, чтобы начать вас:
- Если вы работаете над новым набором данных, может быть легче всего начать с маркированных данных и провести чистого контролируемого обучения. Затем, когда вы довольны архитектурой и гиперпараметрами, добавьте подлого учителя. Та же самая сеть должна работать хорошо, хотя вы можете настроить регуляризацию, такую как распад веса, который вы использовали с небольшими данными.
- Средний учитель нуждается в некотором шуме в модели, чтобы работать оптимально. На практике лучшим шумом, вероятно, является случайное увеличение ввода. Используйте любые соответствующие дополнения, которые вы можете подумать: алгоритм будет обучать модель быть инвариантными для них.
- Полезно посвятить часть каждого Minibatch для помеченных примеров. Затем под наблюдением сигнал обучения достаточно силен на раннем этапе, чтобы быстро тренироваться и не застрять в неопределенности. В примерах Pytorch у нас есть четверть или половина Minibatch для помеченных примеров, а остальные для немеченого. (См. Twostreambatchsampler в коде Pytorch.)
- Для распада EMA 0,999, кажется, является хорошей отправной точкой.
- Вы можете использовать MSE или KL-дивергенцию в качестве функции затрат на согласованность. Для KL-дивергенции хороший вес стоимости согласованности часто составляет от 1,0 до 10,0. Для MSE, кажется, между количеством классов и количеством классов квадрат. На небольших наборах данных мы видели, как MSE получила лучшие результаты, но KL всегда работал тоже хорошо.
- Это может помочь увеличить стоимость последовательности в начале в течение первых нескольких эпох, пока сеть учителей не начнет давать хорошие прогнозы.
- Дополнительный трюк, который мы использовали в примерах Pytorch: иметь два отдельных слоя логита на верхнем уровне. Используйте один для классификации помеченных примеров и один для прогнозирования вывода учителя. И затем иметь дополнительные затраты между логитами этих двух прогнозов. Намерение такое же, как и при рампе за счет согласованности: в начале результаты учителя могут быть неправильными, поэтому ослабьте связь между прогнозом классификации и стоимостью согласованности. (См. Аргумент-logit-Distance-Cost в реализации Pytorch.)


