평균 교사는 더 나은 역할 모델입니다
종이 ----- 닙 2017 포스터 ----- 닐 2017 스포트라이트 슬라이드 ---- 블로그 게시물
Antti Tarvainen, Harri Valpola (호기심 많은 AI 회사)
접근하다
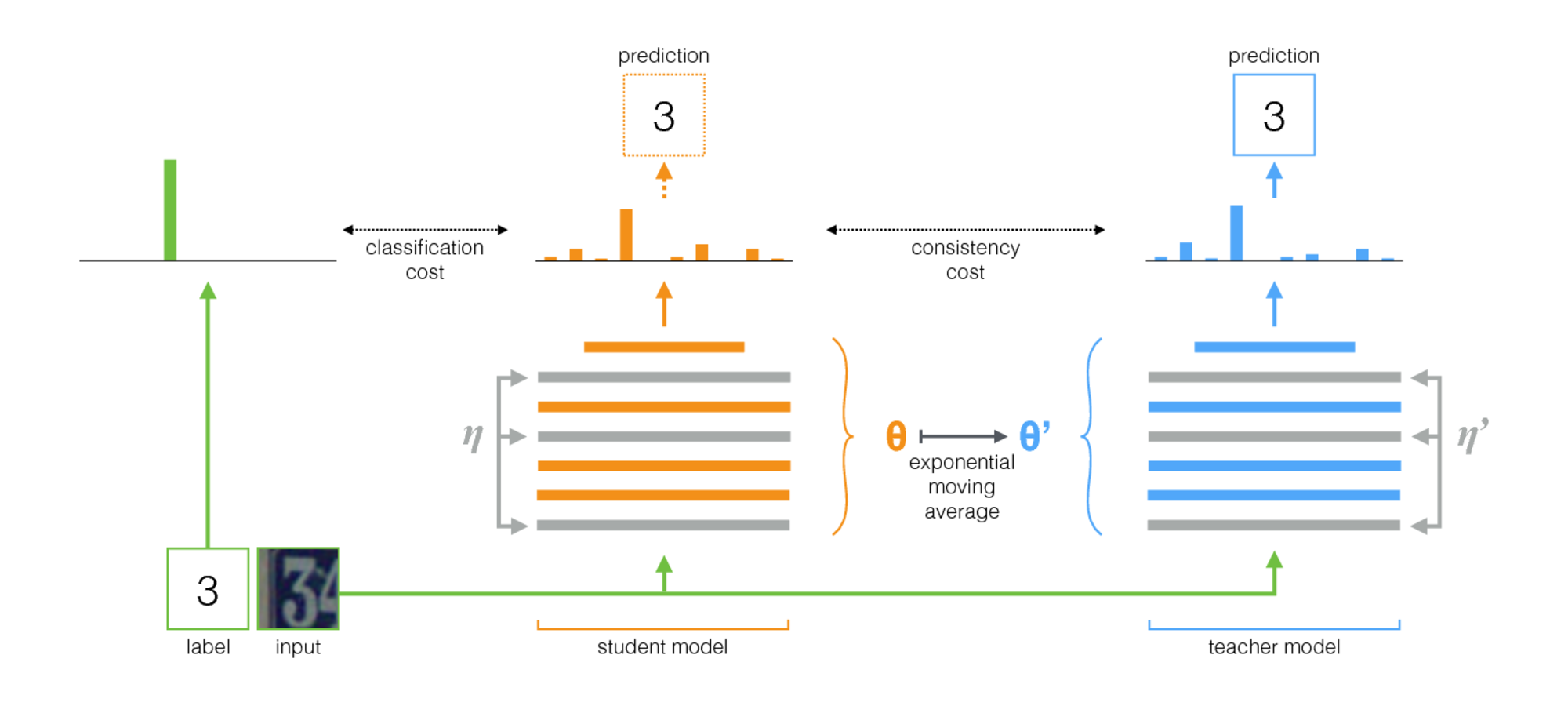
평균 교사는 반 감독 학습을위한 간단한 방법입니다. 다음 단계로 구성됩니다.
- 감독 된 아키텍처를 가져 와서 사본을 만드십시오. 독창적 인 모델을 학생과 새로운 모델 이라고 부르겠습니다.
- 각 훈련 단계에서 학생과 교사 모두에게 입력과 동일한 미니 배치를 사용하지만 입력에 임의 확대 또는 노이즈를 별도로 추가하십시오.
- 학생과 교사 출력 (SoftMax 후) 사이에 추가 일관성 비용을 추가하십시오.
- Optimizer가 학생의 무게를 정상적으로 업데이트하도록하십시오.
- 교사 웨이트를 학생의 체중의 기하 급수적 인 이동 평균 (EMA)으로 두십시오. 즉, 각 훈련 단계 후에는 교사의 웨이트를 학생의 체중으로 약간 업데이트하십시오.
우리의 기여는 마지막 단계입니다. Laine과 Aila [종이]는 학생과 교사 사이의 공유 매개 변수를 사용했거나 교사 예측의 시간적 앙상블을 사용했습니다. 이에 비해 평균 교사는 대형 데이터 세트에 더 정확하고 적용 할 수 있습니다.
평균 교사는 현대 건축과 잘 어울립니다. 평균 교사와 레지 넷을 결합하여 Imagenet 및 CIFAR-10 데이터 세트에서 반 감독 학습에서 ART의 최첨단을 개선했습니다.
| 라벨의 10%를 사용하는 ImageNet | 상단 5 유효성 검사 오류 |
|---|
| 변형 자동 인코더 [종이] | 35.42 ± 0.90 |
| 평균 교사 RESNET-152 | 9.11 ± 0.12 |
| 모든 레이블, 최신 예술 [종이] | 3.79 |
| 4000 개의 레이블을 사용하는 CIFAR-10 | 테스트 오류 |
|---|
| CT-gan [종이] | 9.98 ± 0.21 |
| 평균 교사 RESNET-26 | 6.28 ± 0.15 |
| 모든 레이블, 최신 예술 [종이] | 2.86 |
구현
텐서 플로우와 하나는 Pytorch의 두 가지 구현이 있습니다. Pytorch 버전은 일반적인 Pytorch 관용구를 따르기 때문에 귀하의 요구에 적응하기가 더 쉽습니다. 모델과 데이터 세트를 추가 할 수있는 자연스러운 장소가 있습니다. 설명이 필요한 것이 있으면 알려주세요.
논문의 결과와 관련하여 전통적인 Convnet 아키텍처를 사용한 실험은 텐서 플로우 버전으로 실행되었습니다. 잔류 네트워크를 사용한 실험은 Pytorch 버전으로 실행되었습니다.
하이퍼 파라미터 및 기타 튜닝을 선택하기위한 팁
평균 교사는 EMA 붕괴율과 일관성 비용 가중치라는 두 가지 새로운 하이퍼 파라미터를 소개합니다. 이들 각각에 대한 최적의 값은 데이터 세트, 모델 및 미니 배치의 구성에 따라 다릅니다. 또한 표지되지 않은 샘플과 라벨이 붙은 샘플을 미니 배치로 인터 리브하는 방법을 선택해야합니다.
시작하는 몇 가지 경험 규칙은 다음과 같습니다.
- 새로운 데이터 세트를 작업하는 경우 라벨이 붙은 데이터로 시작하여 순수한 감독 교육을 수행하는 것이 가장 쉬울 수 있습니다. 그런 다음 건축 및 하이퍼 파라미터에 만족하면 평균 교사를 추가하십시오. 작은 데이터와 함께 사용한 무게 붕괴와 같은 정규화를 조정할 수 있지만 동일한 네트워크가 잘 작동해야합니다.
- 평균 교사는 최적으로 작동하기 위해 모델에서 약간의 소음이 필요합니다. 실제로, 최고의 노이즈는 아마도 임의의 입력 증강 일 것입니다. 생각할 수있는 관련 보강기를 사용하십시오. 알고리즘은 모델을 변하지 않도록 훈련시킵니다.
- 라벨이 붙은 예제에 대해 각 미니 배트의 일부를 전념하는 것이 유용합니다. 그런 다음 감독 된 훈련 신호는 빨리 훈련하고 불확실성에 빠지는 것을 방지하기에 충분히 강력합니다. Pytorch 예제에는 라벨이 붙은 예제에 대해서는 Minibatch의 4 분의 1 또는 절반이 있으며 나머지는 표지되지 않은 것들을 가지고 있습니다. (Pytorch 코드의 Twostreambatchsampler를 참조하십시오.)
- EMA Decay Rate 0.999의 경우 좋은 출발점 인 것 같습니다.
- MSE 또는 KL-Divergence를 일관성 비용 함수로 사용할 수 있습니다. KL 디베이트의 경우 일관성 비용 중량이 1.0에서 10.0 사이입니다. MSE의 경우 클래스 수와 제곱 수의 수 사이에있는 것 같습니다. 소규모 데이터 세트에서 우리는 MSE가 더 나은 결과를 얻는 것을 보았지만 KL은 항상 꽤 잘 작동했습니다.
- 교사 네트워크가 좋은 예측을 시작할 때까지 처음 몇 번의 에포크에 걸쳐 시작의 일관성 비용을 증가시키는 데 도움이 될 수 있습니다.
- Pytorch 예제에서 사용한 추가 트릭 : 최상위에 두 개의 별도 로그 층이 있습니다. 라벨이 붙은 예제의 분류에 하나를 사용하고 교사 출력을 예측하기 위해 하나를 사용하십시오. 그런 다음이 두 예측의 벌목 사이에 추가 비용이 있습니다. 의도는 일관성 비용 램프와 동일합니다. 처음에는 교사 출력이 잘못 될 수 있으므로 분류 예측과 일관성 비용 사이의 링크를 풀어주십시오. (Pytorch 구현의-로그-디스턴스 비용 인수를 참조하십시오.)


