Rata -rata guru adalah panutan yang lebih baik
Paper ---- Poster NIPS 2017 ---- Slide Spotlight NIPS 2017 ---- Posting Blog
Oleh Antti Tarvainen, Harri Valpola (The Curious AI Company)
Mendekati
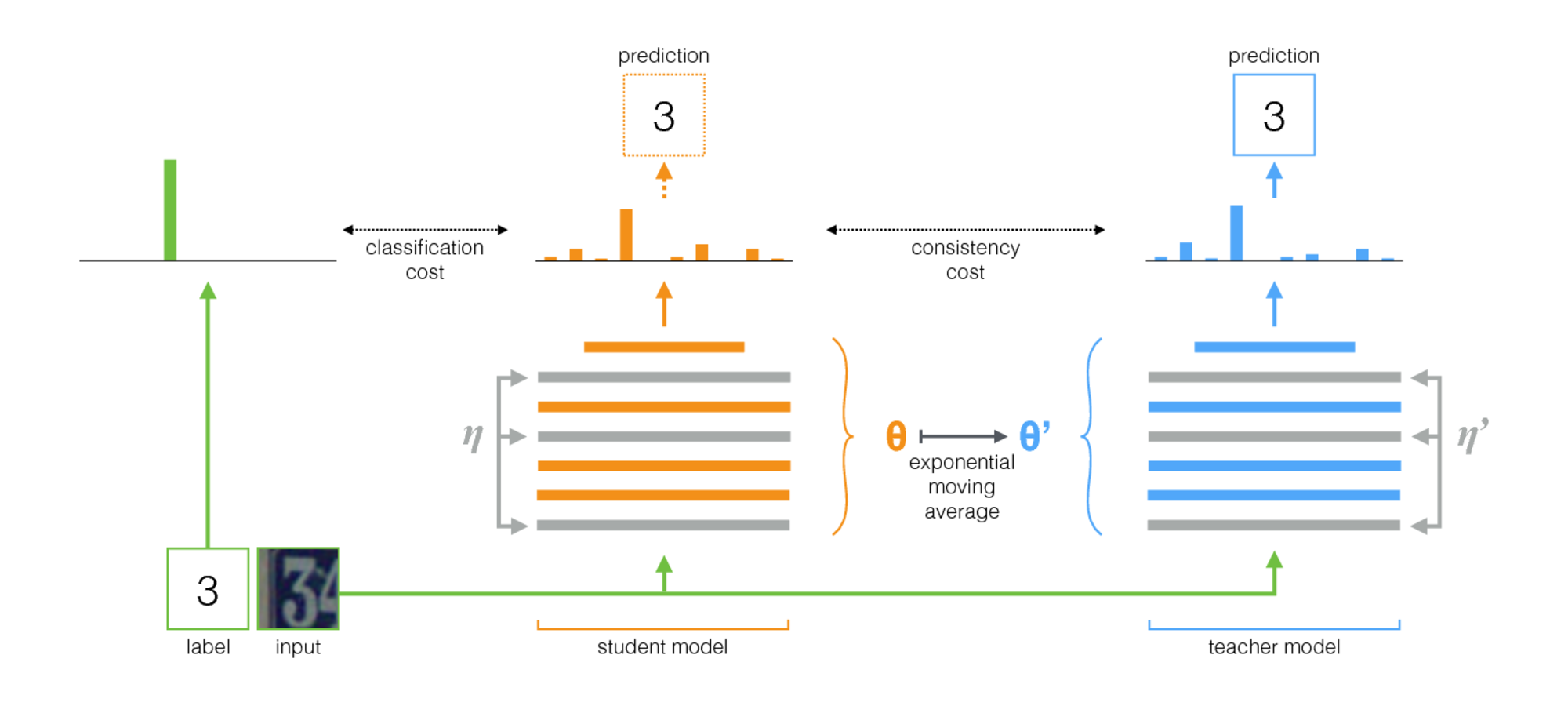
Rata-rata guru adalah metode sederhana untuk pembelajaran semi-diawasi. Itu terdiri dari langkah -langkah berikut:
- Ambil arsitektur yang diawasi dan buat salinannya. Sebutkan model asli siswa dan yang baru guru .
- Pada setiap langkah pelatihan, gunakan minibatch yang sama seperti input untuk siswa dan guru tetapi tambahkan augmentasi acak atau noise ke input secara terpisah.
- Tambahkan biaya konsistensi tambahan antara output siswa dan guru (setelah softmax).
- Biarkan pengoptimal memperbarui bobot siswa secara normal.
- Biarkan bobot guru menjadi rata -rata bergerak eksponensial (EMA) dari bobot siswa. Artinya, setelah setiap langkah pelatihan, perbarui bobot guru sedikit ke arah beban siswa.
Kontribusi kami adalah langkah terakhir. Laine dan Aila [kertas] menggunakan parameter bersama antara siswa dan guru, atau menggunakan ansambel temporal prediksi guru. Sebagai perbandingan, rata -rata guru lebih akurat dan berlaku untuk kumpulan data besar.
Berarti guru bekerja dengan baik dengan arsitektur modern. Menggabungkan rata-rata guru dengan resnet, kami meningkatkan keadaan dalam pembelajaran semi-diawasi pada dataset Imagenet dan CIFAR-10.
| Imagenet menggunakan 10% label | Top-5 kesalahan validasi |
|---|
| Variasional auto-encoder [kertas] | 35,42 ± 0,90 |
| Mean Teacher ResNet-152 | 9.11 ± 0,12 |
| Semua label, canggih [kertas] | 3.79 |
| CIFAR-10 Menggunakan 4000 Label | kesalahan pengujian |
|---|
| CT-GAN [kertas] | 9,98 ± 0,21 |
| Mean Teacher ResNet-26 | 6.28 ± 0,15 |
| Semua label, canggih [kertas] | 2.86 |
Pelaksanaan
Ada dua implementasi, satu untuk TensorFlow dan satu untuk Pytorch. Versi Pytorch mungkin lebih mudah beradaptasi dengan kebutuhan Anda, karena mengikuti idiom pytorch khas, dan ada tempat alami untuk menambahkan model dan dataset Anda. Beri tahu saya jika ada yang membutuhkan klarifikasi.
Mengenai hasil dalam makalah ini, percobaan yang menggunakan arsitektur konvnet tradisional dijalankan dengan versi TensorFlow. Eksperimen yang menggunakan jaringan residual dijalankan dengan versi Pytorch.
Tips untuk Memilih Hyperparameters dan Tuning Lainnya
Rata -rata guru memperkenalkan dua hyperparameters baru: tingkat peluruhan EMA dan berat badan konsistensi. Nilai optimal untuk masing -masing tergantung pada dataset, model, dan komposisi minibatch. Anda juga perlu memilih cara interleave sampel yang tidak berlabel dan sampel berlabel dalam minibatch.
Berikut adalah beberapa aturan praktis untuk memulai:
- Jika Anda mengerjakan dataset baru, mungkin paling mudah untuk memulai dengan hanya data berlabel dan melakukan pelatihan yang diawasi murni. Kemudian ketika Anda senang dengan arsitektur dan hiperparameter, tambahkan guru yang kejam. Jaringan yang sama harus bekerja dengan baik, meskipun Anda mungkin ingin menyesuaikan regularisasi seperti pembusukan berat yang telah Anda gunakan dengan data kecil.
- Berarti guru membutuhkan kebisingan dalam model untuk bekerja secara optimal. Dalam praktiknya, noise terbaik mungkin adalah augmentasi input acak. Gunakan augmentasi yang relevan apa pun yang dapat Anda pikirkan: algoritma akan melatih model untuk tidak berubah bagi mereka.
- Ini berguna untuk mendedikasikan sebagian dari setiap minibatch untuk contoh berlabel. Kemudian sinyal pelatihan yang diawasi cukup kuat sejak dini untuk berlatih dengan cepat dan mencegah terjebak dalam ketidakpastian. Dalam contoh -contoh Pytorch kami memiliki seperempat atau setengah dari minibatch untuk contoh berlabel dan sisanya untuk yang tidak berlabel. (Lihat TwoStreAMBatchSampler dalam kode Pytorch.)
- Untuk tingkat peluruhan EMA 0,999 tampaknya menjadi titik awal yang baik.
- Anda dapat menggunakan MSE atau KL-Divergence sebagai fungsi biaya konsistensi. Untuk divergensi KL, berat badan konsistensi yang baik sering kali antara 1,0 dan 10,0. Untuk MSE, tampaknya antara jumlah kelas dan jumlah kelas kuadrat. Pada dataset kecil kami melihat MSE mendapatkan hasil yang lebih baik, tetapi KL selalu bekerja dengan cukup baik juga.
- Mungkin membantu meningkatkan biaya konsistensi di awal dari beberapa zaman pertama sampai jaringan guru mulai memberikan prediksi yang baik.
- Trik tambahan yang kami gunakan dalam contoh Pytorch: memiliki dua lapisan logit terpisah di tingkat atas. Gunakan satu untuk klasifikasi contoh berlabel dan satu untuk memprediksi output guru. Dan kemudian memiliki biaya tambahan antara logit dari dua prediksi ini. Maksudnya sama dengan dengan peningkatan biaya konsistensi: Pada awalnya output guru mungkin salah, jadi longgarkan hubungan antara prediksi klasifikasi dan biaya konsistensi. (Lihat argumen-logit-jarak dalam implementasi Pytorch.)


